我認為我對 Pandas 資料框有很好的掌握,但出于某種原因,我可以將此字典轉換為資料框 - 我將發布帶有常量變數的完整代碼,以防有人想單獨標記:
import pandas as pd
import numpy as np
patches = 26
min_sl = 2.1
max_sl = 104.1
array = np.arange(min_sl, max_sl 1, step=1)
##Creating an array List
array_list = [i for i in array]
## Creating a dictionary
dict_l={i:"" for i in range(1,patches 1)}
## Populating the dictionary
start = 0
end = 4
for i in dict_l:
dict_l[i] = array_list[start:end]
start = start 5
end = end 5
這將創建以下字典
{1: [2.1, 3.1, 4.1, 5.1],
2: [7.1, 8.1, 9.1, 10.1],
3: [12.1, 13.1, 14.1, 15.1],
4: [17.1, 18.1, 19.1, 20.1],
5: [22.1, 23.1, 24.1, 25.1],
6: [27.1, 28.1, 29.1, 30.1],
7: [32.1, 33.1, 34.1, 35.1],
8: [37.1, 38.1, 39.1, 40.1],
9: [42.1, 43.1, 44.1, 45.1],
10: [47.1, 48.1, 49.1, 50.1],
11: [52.1, 53.1, 54.1, 55.1],
12: [57.1, 58.1, 59.1, 60.1],
13: [62.1, 63.1, 64.1, 65.1],
14: [67.1, 68.1, 69.1, 70.1],
15: [72.1, 73.1, 74.1, 75.1],
16: [77.1, 78.1, 79.1, 80.1],
17: [82.1, 83.1, 84.1, 85.1],
18: [87.1, 88.1, 89.1, 90.1],
19: [92.1, 93.1, 94.1, 95.1],
20: [97.1, 98.1, 99.1, 100.1],
21: [102.1, 103.1, 104.1],
22: [],
23: [],
24: [],
25: [],
26: []}
我想要的是一個簡單的資料框,它將每個串列放在一行中,因此例如索引 1 將有一個具有以下值的串列:[2.1, 3.1, 4.1, 5.1],
result = pd.DataFrame.from_dict(dict_l, orient='index')
result
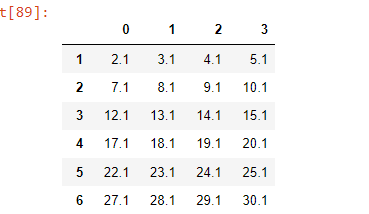
正如你所看到的,我的結果不是我想要的,因為我只想要一列
如果我不指定函式 from_dict,我會收到一個錯誤,所以我想知道是否有人知道如何做到這一點..
我試圖用逗號連接所有列,這在理論上是我想要做的:
結果['行名稱'] = 結果[[i for i in range(0,4,1)]].apply(lambda x: ','.join(x[x.notnull()]),axis=1 )
但是,我收到型別錯誤 TypeError: sequence item 0: expected str instance, float found
有誰知道如何做到這一點?
uj5u.com熱心網友回復:
df = pd.DataFrame({k:[v] for k,v in dict_l.items()}).astype(str)
df = df.stack().reset_index(drop=True)
print(df)
輸出:
0 [2.1, 3.1, 4.1, 5.1]
1 [7.1, 8.1, 9.1, 10.1]
2 [12.1, 13.1, 14.1, 15.1]
3 [17.1, 18.1, 19.1, 20.1]
4 [22.1, 23.1, 24.1, 25.1]
5 [27.1, 28.1, 29.1, 30.1]
6 [32.1, 33.1, 34.1, 35.1]
7 [37.1, 38.1, 39.1, 40.1]
8 [42.1, 43.1, 44.1, 45.1]
9 [47.1, 48.1, 49.1, 50.1]
10 [52.1, 53.1, 54.1, 55.1]
11 [57.1, 58.1, 59.1, 60.1]
12 [62.1, 63.1, 64.1, 65.1]
13 [67.1, 68.1, 69.1, 70.1]
14 [72.1, 73.1, 74.1, 75.1]
15 [77.1, 78.1, 79.1, 80.1]
16 [82.1, 83.1, 84.1, 85.1]
17 [87.1, 88.1, 89.1, 90.1]
18 [92.1, 93.1, 94.1, 95.1]
19 [97.1, 98.1, 99.1, 100.1]
20 [102.1, 103.1, 104.1]
21 []
22 []
23 []
24 []
25 []
uj5u.com熱心網友回復:
只需將串列放入串列中:
...
dict_l[i] = [array_list[start:end]]
...
印刷:
0
1 [2.1, 3.1, 4.1, 5.1]
2 [7.1, 8.1, 9.1, 10.1]
3 [12.1, 13.1, 14.1, 15.1]
4 [17.1, 18.1, 19.1, 20.1]
5 [22.1, 23.1, 24.1, 25.1]
6 [27.1, 28.1, 29.1, 30.1]
7 [32.1, 33.1, 34.1, 35.1]
8 [37.1, 38.1, 39.1, 40.1]
9 [42.1, 43.1, 44.1, 45.1]
10 [47.1, 48.1, 49.1, 50.1]
11 [52.1, 53.1, 54.1, 55.1]
12 [57.1, 58.1, 59.1, 60.1]
13 [62.1, 63.1, 64.1, 65.1]
14 [67.1, 68.1, 69.1, 70.1]
15 [72.1, 73.1, 74.1, 75.1]
16 [77.1, 78.1, 79.1, 80.1]
17 [82.1, 83.1, 84.1, 85.1]
18 [87.1, 88.1, 89.1, 90.1]
19 [92.1, 93.1, 94.1, 95.1]
20 [97.1, 98.1, 99.1, 100.1]
21 [102.1, 103.1, 104.1]
22 []
23 []
24 []
25 []
26 []
uj5u.com熱心網友回復:
DataFrames 是二維資料結構,所以字典的串列被解釋為行。要么構造一個系列(1D)并將其轉換為 DataFrame
result = pd.Series(dict_l).to_frame()
或者用額外的括號包裹字典值以創建“第三維”。
result = pd.DataFrame([[lst] for lst in dict_l.values()],
index=dict_l.keys())
輸出:
>>> result
0
1 [2.1, 3.1, 4.1, 5.1]
2 [7.1, 8.1, 9.1, 10.1]
3 [12.1, 13.1, 14.1, 15.1]
4 [17.1, 18.1, 19.1, 20.1]
5 [22.1, 23.1, 24.1, 25.1]
6 [27.1, 28.1, 29.1, 30.1]
7 [32.1, 33.1, 34.1, 35.1]
8 [37.1, 38.1, 39.1, 40.1]
9 [42.1, 43.1, 44.1, 45.1]
10 [47.1, 48.1, 49.1, 50.1]
11 [52.1, 53.1, 54.1, 55.1]
12 [57.1, 58.1, 59.1, 60.1]
13 [62.1, 63.1, 64.1, 65.1]
14 [67.1, 68.1, 69.1, 70.1]
15 [72.1, 73.1, 74.1, 75.1]
16 [77.1, 78.1, 79.1, 80.1]
17 [82.1, 83.1, 84.1, 85.1]
18 [87.1, 88.1, 89.1, 90.1]
19 [92.1, 93.1, 94.1, 95.1]
20 [97.1, 98.1, 99.1, 100.1]
21 [102.1, 103.1, 104.1]
22 []
23 []
24 []
25 []
26 []
轉載請註明出處,本文鏈接:https://www.uj5u.com/net/360928.html