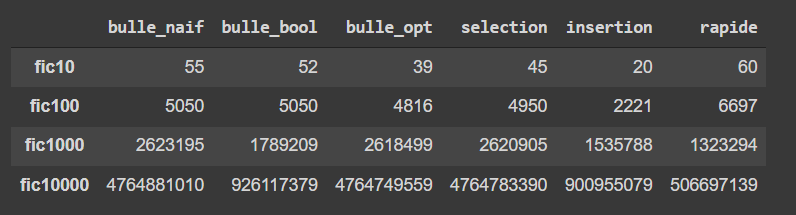
我有以下陣列: [['fic10', {'bulle_naif': '55'}, {'bulle_bool': '52'}, {'bulle_opt': '39'}, {'selection': '45' },{'插入':'20'},{'rapide':'60'}],['fic100',{'bulle_naif':'5050'},{'bulle_bool':'5050'},{' Bulle_opt':'4816'},{'selection':'4950'},{'insertion':'2221'},{'rapide':'6697'}],['fic1000',{'bulle_naif':' 2623195'},{'bulle_bool':'1789209'},{'bulle_opt':'2618499'},{'selection':'2620905'},{'insertion':'1535788'},{'rapide':' 1323294'}],['fic10000',{'bulle_naif':'4764881010'},{'bulle_bool':'926117379'},{'bulle_opt':'4764749559'},{'selection':'4764783390'},{'insertion':'900955079'},'rapide'6'7' }]]]
我將其轉換為資料幀:
uj5u.com熱心網友回復:
讓我們以更易于理解的方式呈現您的資料pandas.DataFrame。
第一種方法:key:list每列一個條目的字典
此方法的目標是重新排列您的資料,使其看起來像一個單獨的 dict,每列一個條目,以及每列的值串列:
# {'bulle_naif': ['55', '5050', '2623195', '4764881010'],
# 'bulle_bool': ['52', '5050', '1789209', '926117379'],
# 'bulle_opt': ['39', '4816', '2618499', '4764749559'],
# 'selection': ['45', '4950', '2620905', '4764783390'],
# 'insertion': ['20', '2221', '1535788', '900955079'],
# 'rapide': ['60', '6697', '1323294', '506697139'],
# 'name': ['fic10', 'fic100', 'fic1000', 'fic10000']}
這是進行該轉換的代碼:
import pandas as pd
raw_data = [['fic10', {'bulle_naif': '55'}, {'bulle_bool': '52'}, {'bulle_opt': '39'}, {'selection': '45'}, {'insertion': '20'}, {'rapide': '60'}], ['fic100', {'bulle_naif': '5050'}, {'bulle_bool': '5050'}, {'bulle_opt': '4816'}, {'selection': '4950'}, {'insertion': '2221'}, {'rapide': '6697'}], ['fic1000', {'bulle_naif': '2623195'}, {'bulle_bool': '1789209'}, {'bulle_opt': '2618499'}, {'selection': '2620905'}, {'insertion': '1535788'}, {'rapide': '1323294'}], ['fic10000', {'bulle_naif': '4764881010'}, {'bulle_bool': '926117379'}, {'bulle_opt': '4764749559'}, {'selection': '4764783390'}, {'insertion': '900955079'}, {'rapide': '506697139'}]]
cleaned_data = { k: [] for d in raw_data[0][1:] for k in d.keys() }
cleaned_data['name'] = []
for row in raw_data:
cleaned_data['name'].append(row[0])
for d in row[1:]:
for k,v in d.items():
cleaned_data[k].append(v)
print(cleaned_data)
# {'bulle_naif': ['55', '5050', '2623195', '4764881010'],
# 'bulle_bool': ['52', '5050', '1789209', '926117379'],
# 'bulle_opt': ['39', '4816', '2618499', '4764749559'],
# 'selection': ['45', '4950', '2620905', '4764783390'],
# 'insertion': ['20', '2221', '1535788', '900955079'],
# 'rapide': ['60', '6697', '1323294', '506697139'],
# 'name': ['fic10', 'fic100', 'fic1000', 'fic10000']}
# IMPORTANT NOTE
# This cleaning-up is a bit careless
# If a key is missing in one of the lists, the resulting data will be misaligned
# Making sure data is not misaligned:
assert(all(len(l) == len(cleaned_data['name']) for l in cleaned_data.values()))
good_dataframe = pd.DataFrame(cleaned_data).set_index('name')
print(good_dataframe)
# bulle_naif bulle_bool bulle_opt selection insertion rapide
# name
# fic10 55 52 39 45 20 60
# fic100 5050 5050 4816 4950 2221 6697
# fic1000 2623195 1789209 2618499 2620905 1535788 1323294
# fic10000 4764881010 926117379 4764749559 4764783390 900955079 506697139
第二種方法:沒有鍵但按順序排列的二維陣列
如果您的資料已經排序,這樣bulle_naif,bulle_opt等,已經在每一行的相同的順序,那么你就可以擺脫所有型別的字典,并提供pandas.DataFrame直接二維陣列:
# assumes the rows of raw_data are all in the same order already
array_data = [[row[0]] [v for d in row[1:] for v in d.values()] for row in raw_data]
print(array_data)
# [['fic10', '55', '52', '39', '45', '20', '60'],
# ['fic100', '5050', '5050', '4816', '4950', '2221', '6697'],
# ['fic1000', '2623195', '1789209', '2618499', '2620905', '1535788', '1323294'],
# ['fic10000', '4764881010', '926117379', '4764749559', '4764783390', '900955079', '506697139']]
keys = ['name'] [k for d in raw_data[0][1:] for k in d.keys()]
dataframe = pd.DataFrame(array_data, columns = keys).set_index('name')
print(dataframe)
# bulle_naif bulle_bool bulle_opt selection insertion rapide
# name
# fic10 55 52 39 45 20 60
# fic100 5050 5050 4816 4950 2221 6697
# fic1000 2623195 1789209 2618499 2620905 1535788 1323294
# fic10000 4764881010 926117379 4764749559 4764783390 900955079 506697139
如果您不知道所有行都已按相同順序顯示,則必須對它們進行顯式排序以確保:
# I shuffled the entries in raw_data
raw_data = [
['fic10', {'bulle_bool': '52'}, {'bulle_naif': '55'}, {'selection': '45'}, {'insertion': '20'}, {'rapide': '60'}, {'bulle_opt': '39'}],
['fic100', {'bulle_opt': '4816'}, {'bulle_naif': '5050'}, {'insertion': '2221'}, {'selection': '4950'}, {'rapide': '6697'}, {'bulle_bool': '5050'}],
['fic1000', {'bulle_opt': '2618499'}, {'selection': '2620905'}, {'insertion': '1535788'}, {'bulle_bool': '1789209'}, {'rapide': '1323294'}, {'bulle_naif': '2623195'}],
['fic10000', {'selection': '4764783390'}, {'bulle_opt': '4764749559'}, {'bulle_bool': '926117379'}, {'bulle_naif': '4764881010'}, {'insertion': '900955079'}, {'rapide': '506697139'}]]
array_data = [[row[0]] [v for d in sorted(row[1:], key=lambda d: next(iter(d.keys()))) for v in d.values()] for row in raw_data]
print(array_data)
# [['fic10', '52', '55', '39', '20', '60', '45'],
# ['fic100', '5050', '5050', '4816', '2221', '6697', '4950'],
# ['fic1000', '1789209', '2623195', '2618499', '1535788', '1323294', '2620905'],
# ['fic10000', '926117379', '4764881010', '4764749559', '900955079', '506697139', '4764783390']]
轉載請註明出處,本文鏈接:https://www.uj5u.com/net/370123.html
上一篇:如何像陣列一樣選擇物件?