我試圖找出選擇哪個最佳選擇,我的主要要求是減少 IO。
- 我有一個包含 500M 記錄的表,下面提到的查詢是在表上選擇默認的聚集索引掃描。
- 我試圖創建一個覆寫非聚集索引,但它仍然選擇聚集索引掃描作為默認值。所以我強迫它使用覆寫索引,我的觀察是邏輯讀取從 3M 下降到 1M,但 CPU 和持續時間增加。
- 我試圖了解這種行為以及什么是最好的。
詢問:
set statistics time, io on;
select
min(CampaignID),
max(CampaignID)
from Campaign
where datecreated < dateadd(day, -90, getutcdate())
go
CREATE NONCLUSTERED INDEX [NCIX]
ON [dbo].[Campaign](DateCreated)
INCLUDE (Campaignid)
go
select
min(CampaignID),
max(CampaignID)
from Campaign with (index = NCIX)
where datecreated < dateadd(day, -90, getutcdate())
set statistics time, io off;
留言:
(1 row affected)
Table 'Campaign'. Scan count 2, logical reads 3548070, physical reads 0, page server reads 0, read-ahead reads 0, page server read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob page server reads 0, lob read-ahead reads 0, lob page server read-ahead reads 0.
(8 rows affected)
(1 row affected)
SQL Server Execution Times:
CPU time = 14546 ms, elapsed time = 14723 ms.
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 3 ms.
(1 row affected)
Table 'Campaign'. Scan count 1, logical reads 1191017, physical reads 0, page server reads 0, read-ahead reads 19, page server read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob page server reads 0, lob read-ahead reads 0, lob page server read-ahead reads 0.
(6 rows affected)
(1 row affected)
SQL Server Execution Times:
CPU time = 163953 ms, elapsed time = 164163 ms.
執行計劃:
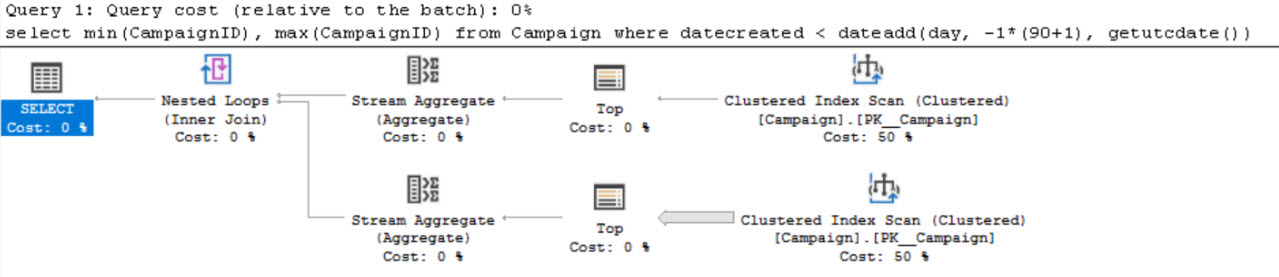

完成執行計劃
uj5u.com熱心網友回復:
首先,沒有“最佳”運營商。有時讀取更多資料比讀取一些資料并對其進行按摩以獲得我們的結果更有效。“最好”,因為幾乎一切都是相對的。
讓我們試著了解評論中發生了什么......
查詢
select
min(CampaignID),
max(CampaignID)
from Campaign
where datecreated < dateadd(day, -90, getutcdate())
其中說:
我想要日期小于固定日期的任何記錄的第一個和最后一個 ID(最小/最大)。
集群的
第一個沒有索引/索引提示的查詢做了 SQL Server 認為比讀取任何索引更便宜的操作,即使它需要更多的 IO(磁盤使用)。這是因為在驗證表中的記錄時找到最小值和最大值比選擇表的一半更便宜,然后重新排序/聚合它們會找到完全相同的資訊。
聚集索引將所有資料存盤在磁盤上,并按鍵列進行邏輯排序,在本例中為 CampaignID(我假設)。這意味著,找到最小和最大 ID 很容易:最小值是符合條件的第一個 ID -> 讓我們檢查第一個 ID 中的每個 ID,并在找到日期到位的記錄后停止(這將很可能是第一個)。最大值是從索引末尾開始匹配條件的第一條記錄。
以日期為鍵的索引
有了第一個索引(日期為鍵列),SQL Server就可以用日期來過濾資料了,確實如此,但是對排序沒有幫助。它仍然必須檢查該索引中的每條記錄,并從一組可能無序的值中找出最小值和最大值。
以 ID 為鍵的索引
對于 ID 是鍵列的第二個索引,SQL Server 可以使用與聚集鍵相同的技巧。唯一的區別是沒有其他資料可以讀取,只有ID和日期,這比整個記錄要小得多,因此它可以容納更少的頁面并且需要更少的IO。
即使沒有索引提示,SQL Server 也很可能會選擇第二個索引。
筆記
在這里我要補充一點:僅針對一個查詢進行優化并不總是最好的策略。您無法對所有內容進行優化,如果此查詢每天/每周/每季度運行一次,那么使用集群鍵的 14-15 秒運行時間很可能不會造成傷害。如果索引對其他查詢沒有幫助,我不會創建它,除非它是一個關鍵任務查詢。
轉載請註明出處,本文鏈接:https://www.uj5u.com/net/371165.html
上一篇:SQL計數取決于特定條件