假設我有一個像這樣的資料透視表:
import pandas as pd
d = {'Col_A': [1,2,3,3,3,4,9,9,10,11],
'Col_B': ['A','K','E','E','H','A','J','A','L','A'],
'Value1':[648,654,234,873,248,45,67,94,180,120],
'Value2':[180,120,35,654,789,34,567,21,235,83]
}
df = pd.DataFrame(data=d)
df_pvt = pd.pivot_table(df,values=['Value1','Value2'], index='Col_A', columns='Col_B', aggfunc=np.sum).fillna(0)
df_pvt
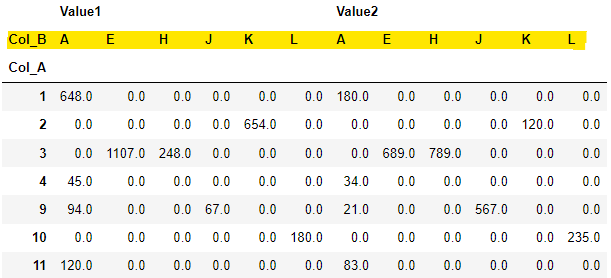
我想要實作的是為 Col_B(突出顯示)設定一個順序,以便 Value1 和 Value2 的輸出將按 E、J、A、K、L、H 的順序顯示。
uj5u.com熱心網友回復:
col_B在重塑之前轉換為分類:
(df.astype({'Col_B' : pd.CategoricalDtype(['E', 'J', 'A', 'K', 'L', 'H'], ordered = True)})
.pivot_table(values=['Value1','Value2'],
index='Col_A',
columns='Col_B',
aggfunc=np.sum)
)
Value1 Value2
Col_B E J A K L H E J A K L H
Col_A
1 0 0 648 0 0 0 0 0 180 0 0 0
2 0 0 0 654 0 0 0 0 0 120 0 0
3 1107 0 0 0 0 248 689 0 0 0 0 789
4 0 0 45 0 0 0 0 0 34 0 0 0
9 0 67 94 0 0 0 0 567 21 0 0 0
10 0 0 0 0 180 0 0 0 0 0 235 0
11 0 0 120 0 0 0 0 0 83 0 0 0
轉載請註明出處,本文鏈接:https://www.uj5u.com/net/376267.html