我需要最相似的列檔案,我有資料:
輸入:
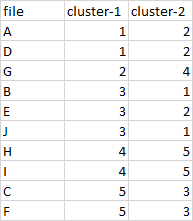
我需要 cluster-1 在最大計數中等于 cluster-2,一個不會被指定為不包含在集群中的檔案
輸出:
uj5u.com熱心網友回復:
首先Series.mode按原始列比較每個組,過濾器,并在必要時添加未過濾的行,分配bin給cluster-2:
print (df)
file cluster-1 cluster-2
0 A 1 2
1 D 1 2
2 G 2 4
3 B 3 1
4 E 3 2
5 J 3 1
m = (df.groupby('cluster-1')['cluster-2']
.transform(lambda x: x.mode().iat[0])
.eq(df['cluster-2']))
df = (df[m].append(df[~m].assign(**{'cluster-1':'bin'}), ignore_index=True)
.rename(columns={'cluster-1':'cluster'})
.drop('cluster-2', axis=1))
print (df)
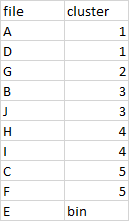
file cluster
0 A 1
1 D 1
2 G 2
3 B 3
4 J 3
5 E bin
轉載請註明出處,本文鏈接:https://www.uj5u.com/net/376299.html