我有一個具有 3 個值的變數:男性、女性、未知。對于分析的許多部分,我需要保留未知數,但我想做一個密度/直方圖,比較一些沒有未知數的分數。我還需要添加什么才能取出其中一個值?
我的資料如下所示:
| 性別描述 | SATCompositeSuper |
|---|---|
| 女性 | 730 |
| 女性 | 780 |
| 男性 | 800 |
| 女性 | 1000 |
| 女性 | 1110 |
| 女性 | 不適用 |
| 男性 | 1050 |
| 男性 | 950 |
| 未知 | 900 |
| 男性 | 780 |
句法:
# Color by groups- gender
master_df %>%
drop_na() %>%
library(ggplot2)
ggplot(master_df, aes(x=SATCompositeSuper, na.rm=TRUE, color=GenderDescription,
fill=GenderDescription))
geom_histogram(aes(y=..density..), alpha=0.5, position="identity")
geom_density(alpha=.2)
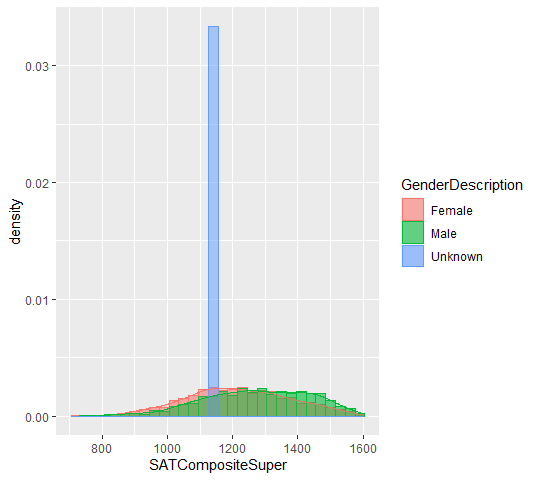
當前輸出(因為我沒有考慮未知)是這樣的:
uj5u.com熱心網友回復:
您的示例不會產生您在帖子中顯示的情節,但是我可以考慮通過兩種方法過濾掉未知
首先,您可以在繪制資料之前過濾掉資料
library(dplyr)
library(tidyverse)
master_df <- master_df %>%
drop_na() %>%
filter(GenderDescription != "Unknown")
ggplot(master_df, aes(x=SATCompositeSuper, na.rm=TRUE, color=GenderDescription, fill=GenderDescription))
geom_histogram(aes(y=..density..), alpha=0.5, position="identity")
geom_density(alpha=.2)
第二個是在繪圖時過濾資料
ggplot(data=master_df[!master_df$GenderDescription %in% c("Unknown"),], aes(x=SATCompositeSuper, na.rm=TRUE, color=GenderDescription, fill=GenderDescription))
geom_histogram(aes(y=..density..), alpha=0.5, position="identity")
geom_density(alpha=.2)
轉載請註明出處,本文鏈接:https://www.uj5u.com/net/376449.html
下一篇:使用拼湊時如何減少圖之間的空間