大家好,我正在學習 python 我是新手我在 csv 檔案中有一個列,其中包含以下示例:
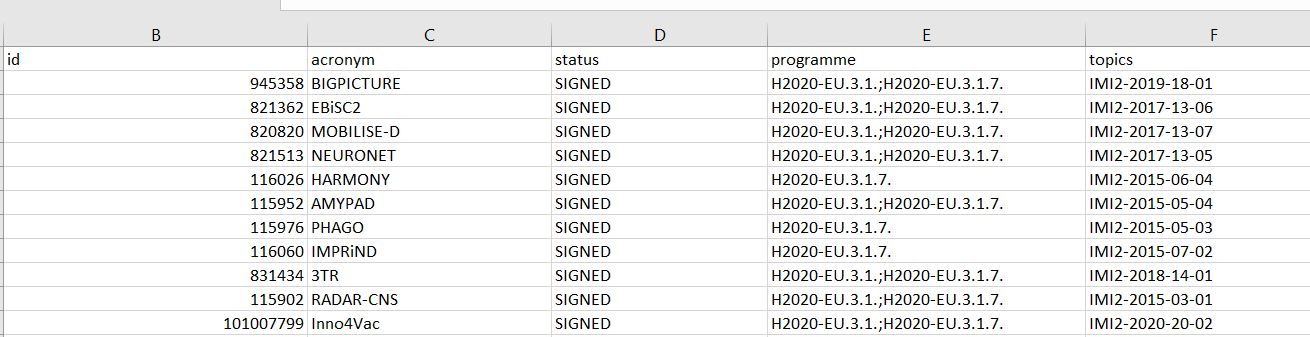
例如,我想將基于該半列的列程式分成兩列
program 1: H2020-EU.3.1.
program 2: H2020-EU.3.1.7.
這是我最初寫的
import csv
import os
with open('IMI.csv', 'r') as csv_file:
csv_reader = csv.reader(csv_file)
with open('new_IMI.csv', 'w') as new_file:
csv_writer = csv.writer(new_file, delimiter='\t')
#for line in csv_reader:
# csv_writer.writerow(line)
請注意,在我進行列拆分后,我需要將檔案再次寫入為 csv 并將其保存到我的計算機
請指導我
uj5u.com熱心網友回復:
使用.loc遍歷資料幀的每一行效率有點低。最好拆分整個列,并expand=True分配給新列。同樣如上所述,pandas在這里易于使用:
代碼:
import pandas as pd
df = pd.read_csv('IMI.csv')
df[['programme1','programme2']] = df['programme'].str.split(';', expand=True)
df.drop(['programme'], axis=1, inplace=True)
df.to_csv('IMI.csv', index=False)
輸出示例:
前:
print(df)
id acronym status programme topics
0 945358 BIGPICTURE SIGNED H2020-EU.3.1.;H2020-EU3.1.7 IMI2-2019-18-01
1 821362 EBiSC2 SIGNED H2020-EU.3.1.;H2020-EU3.1.7 IMI2-2017-13-06
2 116026 HARMONY SIGNED H202-EU.3.1. IMI2-2015-06-04
后:
print(df)
id acronym status topics programme1 programme2
0 945358 BIGPICTURE SIGNED IMI2-2019-18-01 H2020-EU.3.1. H2020-EU3.1.7
1 821362 EBiSC2 SIGNED IMI2-2017-13-06 H2020-EU.3.1. H2020-EU3.1.7
2 116026 HARMONY SIGNED IMI2-2015-06-04 H2020-EU.3.1. None
uj5u.com熱心網友回復:
您可以使用pandaslibrary 而不是csv.
import pandas as pd
df = pd.read_csv('IMI.csv')
p1 = {}
p2 = {}
for i in range(len(df)):
if ';' in df['programme'].loc[i]:
p1[df['id'].loc[i]] = df['programme'].loc[i].split(';')[0]
p2[df['id'].loc[i]] = df['programme'].loc[i].split(';')[1]
df['programme1'] = df['id'].map(p1)
df['programme2'] = df['id'].map(p2)
如果你想洗掉programme列:
df.drop('programme', axis=1)
保存新的 csv 檔案:
df.to_csv('new_file.csv', inplace=True)
轉載請註明出處,本文鏈接:https://www.uj5u.com/net/376561.html