我正在抓取一個網頁并獲取作者串列及其費率。將資料保存在 .csv 檔案中,現在想要處理收集的資料并創建評分最高的 5 個作者的頂級串列。
這是 .csv 檔案的樣子:
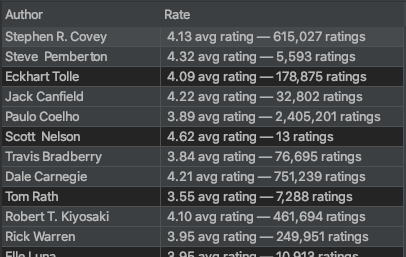
這是我到目前為止所做的:
import csv
with open ('goodreads-book.csv', 'r') as csv_file:
csv_reader = csv.reader(csv_file)
next(csv_reader)
with open("TopFiveRatedAuthors.csv", 'w') as new_file:
for line in csv_reader:
rate = line[1]
rate = rate[19:-8]
# print(rate)
if (rate) > ('100,000'):
# print (rate)
t =line
csv_writer = csv.writer(new_file)
csv_writer.writerow(line)
我的問題是在線:
if str(rate) > '100,000':
現在它回傳一些隨機單元格,但是,我想在這里撰寫一個代碼來動態比較單元格并且只回傳評分最高的單元格。我對這個話題很陌生,我真的很感激任何幫助。
uj5u.com熱心網友回復:
由于 Python 比較字串的方式,嘗試比較數字字串并不總是有效。示例:'10000' > '900' 將回傳 False。如果要比較字串,請將它們轉換為數字,例如:
rate = rate[19:-8]
rate = int(rate.replace(',','')) #get rid of commas before conversion
if rate > 100000: #compare integers
uj5u.com熱心網友回復:
您可能可以Rate在空格上拆分列。第五部分應該是評分。然后洗掉,并轉換為整數。例如:
import csv
with open ('goodreads-book.csv', 'r') as f_input, open('TopFiveRatedAuthors.csv', 'w', newline='') as f_output:
csv_input = csv.reader(f_input)
header = next(csv_input)
csv_output = csv.writer(f_output)
csv_output.writerow(header) # copy header to output
for row in csv_input:
rating = int(row[1].split(' ')[4].replace(',', ''))
if rating > 100000:
csv_output.writerow(row)
您需要將 CSV 檔案的文本版本放入您的問題中,以便對其進行測驗。如果有問題,請添加print(row)以查看它在哪一行失敗,然后還要print(row[1].split(' '))查看它是否正確拆分。
例如4.13 avg rating -- 615,027 ratings應該拆分成串列:
['4.13', 'avg', 'rating', '--', '615,027', 'ratings']
所以[4]是需要的號碼。
uj5u.com熱心網友回復:
如果你想獲得 top(x) 評級,我會使用 pandas 匯入 csv,清理評級欄位,然后呼叫 nlargest 方法
import pandas as pd
df = pd.read_csv('ratings.csv')
#code here to put rating field in proper format and own column. Like others have suggested, include the csv file so we can see how it looks
newdf = df.nlargest(10, "rating") #10 highest or whatever # you want
轉載請註明出處,本文鏈接:https://www.uj5u.com/net/376575.html
上一篇:如何總結excel檔案中特定行和列的最高/最低總成本?
下一篇:讀取txt檔案錯誤地使用分隔符