先把問題描述一下。。
這兩天決議一份PDF檔案的時候,需要提取出檔案中的一段文字訊息。代碼是公司前輩之前寫好的一個方法,代碼如下:

x1, y1, x2, y2四個引數圈定了一個范圍,提取的就是這個范圍中的文,在檔案中如下圖:

但是實際提取出來的文字是這樣的:
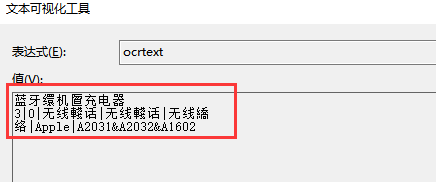
去百度查了一下,度娘上的基本都是以亂碼為主,我這個方法提取的文字有部分是正確,部分錯誤。好像不是網上說的字符編碼問題,請大佬幫忙指點一下迷津

uj5u.com熱心網友回復:
沒有人遇到過這種問題嗎,,,,uj5u.com熱心網友回復:
用了繁體,就是編碼問題uj5u.com熱心網友回復:
如果是編碼的問題,為什么有的文字就沒有問題,比如‘藍牙’兩個字就沒問題,‘耳’字就錯了。如果是您說的這個編碼問題,在“PdfTextExtractor.GetTextFromPage”這個方法中能做修改嗎?uj5u.com熱心網友回復:
PDF不同的文字塊可能使用的是不同的字體,你用PDF編輯軟體看看。打斷點進去瞅瞅。
不行就換成熟的組件,AsposePDF,IText 之類的
uj5u.com熱心網友回復:
其實不用這么麻煩!你找到你前輩編碼的地方換種編碼格式就行了uj5u.com熱心網友回復:
是的已經發現是字體的原因了,現在在想辦法看看是否能把字體轉一下轉載請註明出處,本文鏈接:https://www.uj5u.com/net/38136.html
標籤:C#
上一篇:怎么使用c#呼叫MATLAB函式
下一篇:visual物件名無效