問題總結:
我有一個 BigQuery SQL 表,格式如下:
| 來源 | 目標 | 重量 |
|---|---|---|
| 一個 | 乙 | 1 |
| 一個 | C | 2 |
| D | 一個 | 3 |
| 乙 | 一個 | 4 |
我正在嘗試重新排串列格,例如,所有A值都將移到Source列中并移出Target列,并得到預期結果:
| 來源 | 目標 | 重量 |
|---|---|---|
| 一個 | 乙 | 1 |
| 一個 | C | 2 |
| 一個 | D | 3 |
| 一個 | 乙 | 4 |
我可以一個人做這個單一的價值,但我的問題是,我想轉移Source和Target值多值。
實際上,權重是兩個集合之間的 Jaccard 相似系數。它們是在 BigQuery 中估算的,但由于它們不是在給定 BigQuery 的表格格式的情況下以成對方式估算的,因此我希望Source列中的值出現在Target列中。
我試過的:
對于單個值,例如,A僅,我有以下解決方案:
WITH temp AS (
SELECT
*, "A" AS new_source
FROM networks.my_table
WHERE `Source`= "A" OR `Target` = "A"
ORDER BY jaccard DESC
),
output AS (
SELECT *,
CASE WHEN `Target` = new_source THEN `Source` ELSE `Target` END new_target
FROM temp
)
SELECT * FROM output
但我似乎無法將其概括為所有情況。
或者,如果有一種方法可以在應用 Jaccard 系數估計之前將資料轉換為矩陣,我也會接受該解決方案。
uj5u.com熱心網友回復:
考慮以下方法
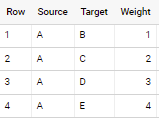
select if(Target = 'A', struct(Target as Source, Source as Target, Weight), t).*
from your_table t
如果應用于您問題中的樣本資料 - 輸出是
轉載請註明出處,本文鏈接:https://www.uj5u.com/net/381379.html