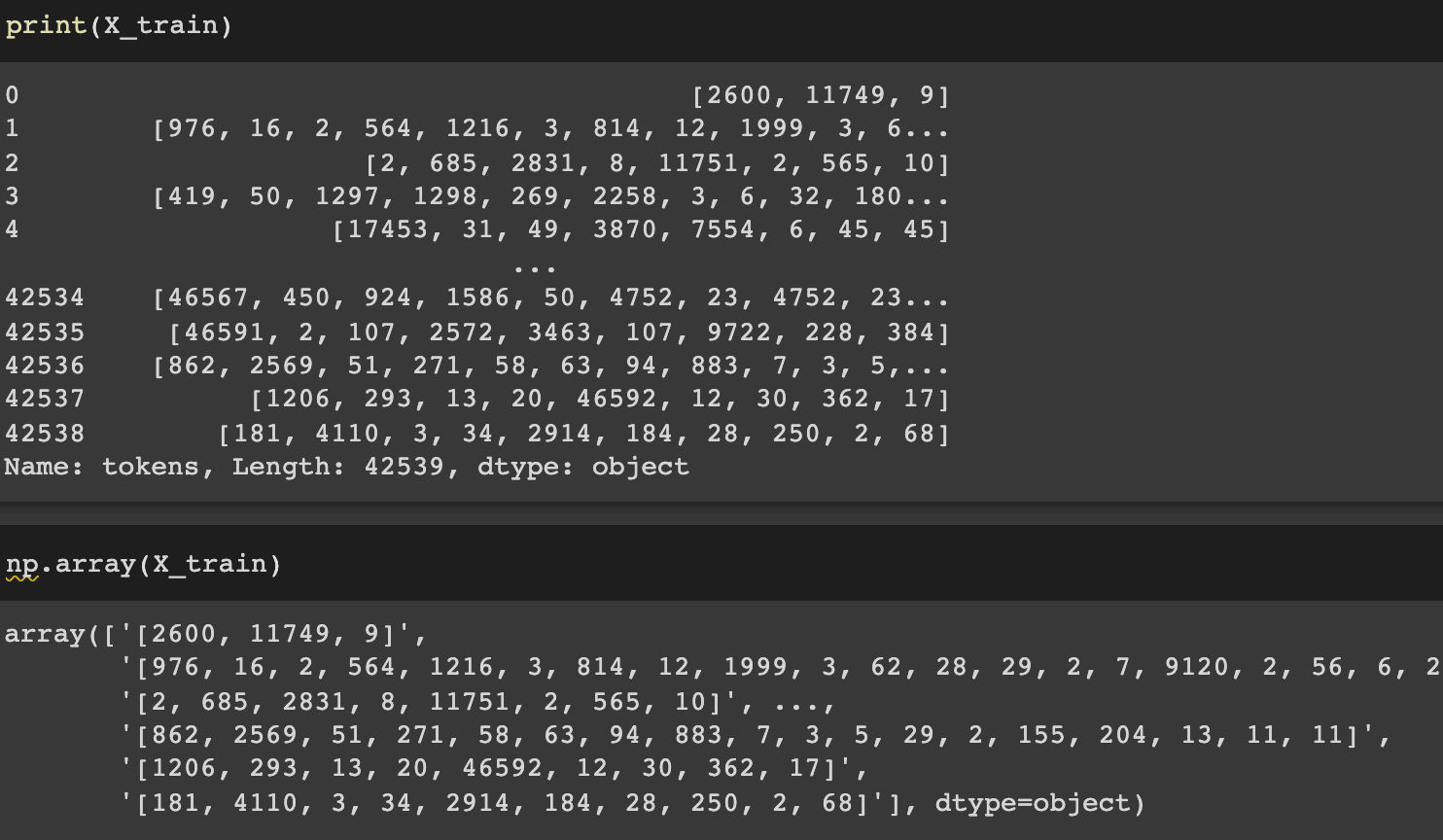
我要這個
array([[2600, 11749, 9], [976, 16, 2, ...],...)
但我不知道為什么列印單引號。我該怎么辦?
uj5u.com熱心網友回復:
看來pandas系列已經輸入了不同長度的numpy陣列。
看來pandas系列已經輸入了不同長度的numpy陣列。
試試這個
X_train.values
或者
list(map(np.array, x_train))
uj5u.com熱心網友回復:
看起來每一行X_train都是一個字串而不是一個串列,所以我認為你需要將這些字串轉換為串列。我認為應該這樣做:
X_train = pd.Series([[int(x) for x in string.strip('[]').split(',')] for string in X_train.tolist()])
uj5u.com熱心網友回復:
它看起來像X_train一個pandas資料框。很難從框架顯示中分辨出像您這樣的列包含什么 - 它真的是陣列嗎?的np.array(X_train),告訴我們沒有,它包含字串看起來像陣列。 X_train.to_numpy()是從幀中提取陣列的首選方法,但我認為結果將是相同的。
我的猜測是,從過去的 SO 問題來看,最初您有一列帶有陣列的框架。然后你把它保存為csv,并重新加載它。因為csv本質上是 2d 格式,pandas必須撰寫字串,而不是陣列。這就是你得到的。
看原始碼csv。
雖然可以將這些字串轉換為陣列(前提是它們不包含...),但這并非易事。許多以前的 SO 都提出了建議,但我會讓其他人找到相關的重復項。
即使您成功地將字串轉換為陣列,框架仍將包含長度不同的陣列,這意味著生成的陣列仍將是 objectdtype,即包含不同長度陣列的陣列。它不會是二維數字 dtype 陣列。
這個名字X_train暗示要使用此資料為某種形式的機器學習。大多數(如果不是全部)這些方法都期望資料大小一致。陣列應具有類似[batch, samples, features]. 他們不能“衣衫襤褸”。
制作一個框架:
In [24]: df = pd.DataFrame([None,None,None],columns=['one'])
In [25]: df
Out[25]:
one
0 None
1 None
2 None
In [29]: df['one'] = [np.ones(5),np.arange(4),np.zeros(9)]
In [30]: df
Out[30]:
one
0 [1.0, 1.0, 1.0, 1.0, 1.0]
1 [0, 1, 2, 3]
2 [0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0]
一個參差不齊的陣列:
In [31]: df.to_numpy()
Out[31]:
array([[array([1., 1., 1., 1., 1.])],
[array([0, 1, 2, 3])],
[array([0., 0., 0., 0., 0., 0., 0., 0., 0.])]], dtype=object)
制作一個 csv 并回傳:
In [32]: df.to_csv('test')
In [33]: df1 = pd.read_csv('test')
In [34]: df1
Out[34]:
Unnamed: 0 one
0 0 [1. 1. 1. 1. 1.]
1 1 [0 1 2 3]
2 2 [0. 0. 0. 0. 0. 0. 0. 0. 0.]
注意顯示與 [30] 相同。但陣列就像你的一樣:
In [35]: df1.to_numpy()
Out[35]:
array([[0, '[1. 1. 1. 1. 1.]'],
[1, '[0 1 2 3]'],
[2, '[0. 0. 0. 0. 0. 0. 0. 0. 0.]']], dtype=object)
在csv外觀一樣的框架-無報價。但是 csv 閱讀器無法決議這些[]部分。它只是將測驗拆分為逗號。
In [36]: cat test
,one
0,[1. 1. 1. 1. 1.]
1,[0 1 2 3]
2,[0. 0. 0. 0. 0. 0. 0. 0. 0.]
但是等等,[34] 沒有逗號。那是因為源框架有串列,而不是陣列。
In [37]: df['one'] = [np.ones(5).tolist(),np.arange(4).tolist(),np.zeros(9).toli
...: st()]
In [38]: df
Out[38]:
one
0 [1.0, 1.0, 1.0, 1.0, 1.0]
1 [0, 1, 2, 3]
2 [0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0]
In [39]: df.to_numpy()
Out[39]:
array([[list([1.0, 1.0, 1.0, 1.0, 1.0])],
[list([0, 1, 2, 3])],
[list([0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0])]],
dtype=object)
In [40]: df.to_csv('test')
In [41]: cat test
,one
0,"[1.0, 1.0, 1.0, 1.0, 1.0]"
1,"[0, 1, 2, 3]"
2,"[0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0]"
In [42]: df1 = pd.read_csv('test')
In [43]: df1
Out[43]:
Unnamed: 0 one
0 0 [1.0, 1.0, 1.0, 1.0, 1.0]
1 1 [0, 1, 2, 3]
2 2 [0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0]
In [44]: df1.to_numpy()
Out[44]:
array([[0, '[1.0, 1.0, 1.0, 1.0, 1.0]'],
[1, '[0, 1, 2, 3]'],
[2, '[0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0]']], dtype=object)
將這樣的字串轉換為串列很容易——只需eval在每個字串上使用即可。
轉載請註明出處,本文鏈接:https://www.uj5u.com/net/387125.html