我很困惑如何將我的 JSON 資料切碎到表中,因為沒有使用陣列名稱進行格式化
實際的 JSON 檔案要大得多(19K 行),所以我只提取了其中的一小部分(頂級的前兩個和其中的一些。
DECLARE @txt1 varchar(max) = '{ "Rv0005": { "p.Glu540Asp": { "annotations": [ { "type": "drug", "drug": "moxifloxacin", "literature": "10.1128/AAC.00825-17;10.1128/JCM.06860-11", "confers": "resistance" } ], "genome_positions": [ 6857, 6858, 6859 ] }, "p.Ala504Thr": { "annotations": [ { "type": "drug", "drug": "ciprofloxacin", "confers": "resistance" }, { "type": "drug", "drug": "fluoroquinolones", "confers": "resistance" }, { "type": "drug", "drug": "levofloxacin", "confers": "resistance" }, { "type": "drug", "drug": "moxifloxacin", "confers": "resistance" }, { "type": "drug", "drug": "ofloxacin", "confers": "resistance" } ], "genome_positions": [ 6749, 6750, 6751 ] }, "p.Ala504Val": { "annotations": [ { "type": "drug", "drug": "ciprofloxacin", "confers": "resistance" }, { "type": "drug", "drug": "fluoroquinolones", "confers": "resistance" }, { "type": "drug", "drug": "levofloxacin", "confers": "resistance" }, { "type": "drug", "drug": "moxifloxacin", "confers": "resistance" }, { "type": "drug", "drug": "ofloxacin", "confers": "resistance" } ], "genome_positions": [ 6749, 6750, 6751 ] } }, "Rv2043c": { "p.Thr100Ile": { "annotations": [ { "type": "drug", "drug": "pyrazinamide", "literature": "10.1128/JCM.01214-17", "confers": "resistance" } ], "genome_positions": [ 2288942, 2288943, 2288944 ] }, "p.Thr160Ala": { "annotations": [ { "type": "drug", "drug": "pyrazinamide", "literature": "10.1128/JCM.01214-17", "confers": "resistance" } ], "genome_positions": [ 2288762, 2288763, 2288764 ] }, "c.101_102insT": { "annotations": [ { "type": "drug", "drug": "pyrazinamide", "confers": "resistance" } ], "genome_positions": [ 2289140, 2289141 ] } } }'
SELECT * FROM OPENJSON(@txt1)
頂層是一個基因,這只是來自兩個基因的資料(Rv0005 = 基因 1,Rv2043c = 基因 2)。每個基因可以有多個突變(例如,Rv0005 在 p.Glu540Asp 和 p.Ala504Thr 處有一個突變),并且這些突變中的每一個都有一些與之相關的資料(文獻、抗性、基因組位置等)。我知道我可以通過以下方式決議部分 JSON 和 JSON 陣列
SELECT * FROM OPENJSON(@txt1)
SELECT * FROM OPENJSON(@txt1, '$.Rv0005."p.Glu540Asp".genome_positions')
但是我不知道如何在不知道鍵/值是什么的情況下將整個內容切碎。特別是有 35 個獨特的基因(JSON 樹的頂部),每個突變都在它們下面命名,但都是獨特的(egpGlu540Asp 等)。
最終,我要么想將資料提取到多個規范化表中,但老實說,像這樣一張大表就可以了
CREATE TABLE #Muts (gene varchar(max), mutations varchar(max), annotation_type varchar(max), annotation_drug varchar(max), annotation_literature varchar(max), annotation_confers varchar(max), genome_positions int )
并且前幾個值的資料看起來像這樣(注意一些突變賦予對多種藥物的抗性)
| 基因 | 突變 | annotation_type | annotation_drug | annotation_literature | annotation_confers | 基因組位置 |
|---|---|---|---|---|---|---|
| RV0005 | p.Glu540Asp | 藥品 | 莫西沙星 | 10.1128/AAC.00825-17;10.1128/JCM.06860-11 | 反抗 | 6857 |
| RV0005 | p.Glu540Asp | 藥品 | 莫西沙星 | 10.1128/AAC.00825-17;10.1128/JCM.06860-11 | 反抗 | 6858 |
| RV0005 | p.Glu540Asp | 藥品 | 莫西沙星 | 10.1128/AAC.00825-17;10.1128/JCM.06860-11 | 反抗 | 6859 |
| RV0005 | p.Ala504Thr | 藥品 | 環丙沙星 | 10.1128/AAC.00825-17;10.1128/JCM.06860-11 | 反抗 | 6849 |
| RV0005 | p.Ala504Thr | 藥品 | 氟喹諾酮類 | 10.1128/AAC.00825-17;10.1128/JCM.06860-11 | 反抗 | 6849 |
| RV0005 | p.Ala504Thr | 藥品 | 左氧氟沙星 | 10.1128/AAC.00825-17;10.1128/JCM.06860-11 | 反抗 | 6849 |
| RV0005 | p.Ala504Thr | 藥品 | 莫西沙星 | 10.1128/AAC.00825-17;10.1128/JCM.06860-11 | 反抗 | 6849 |
| RV0005 | p.Ala504Thr | 藥品 | 氧氟沙星 | 10.1128/AAC.00825-17;10.1128/JCM.06860-11 | 反抗 | 6849 |
| RV0005 | p.Ala504Thr | 藥品 | 環丙沙星 | 10.1128/AAC.00825-17;10.1128/JCM.06860-11 | 反抗 | 6850 |
| RV0005 | p.Ala504Thr | 藥品 | 氟喹諾酮類 | 10.1128/AAC.00825-17;10.1128/JCM.06860-11 | 反抗 | 6850 |
| RV0005 | p.Ala504Thr | 藥品 | 左氧氟沙星 | 10.1128/AAC.00825-17;10.1128/JCM.06860-11 | 反抗 | 6850 |
| RV0005 | p.Ala504Thr | 藥品 | 莫西沙星 | 10.1128/AAC.00825-17;10.1128/JCM.06860-11 | 反抗 | 6850 |
| RV0005 | p.Ala504Thr | 藥品 | 氧氟沙星 | 10.1128/AAC.00825-17;10.1128/JCM.06860-11 | 反抗 | 6850 |
| RV0005 | p.Ala504Thr | 藥品 | 環丙沙星 | 10.1128/AAC.00825-17;10.1128/JCM.06860-11 | 反抗 | 6851 |
| RV0005 | p.Ala504Thr | 藥品 | 氟喹諾酮類 | 10.1128/AAC.00825-17;10.1128/JCM.06860-11 | 反抗 | 6851 |
| RV0005 | p.Ala504Thr | 藥品 | 左氧氟沙星 | 10.1128/AAC.00825-17;10.1128/JCM.06860-11 | 反抗 | 6851 |
| RV0005 | p.Ala504Thr | 藥品 | 莫西沙星 | 10.1128/AAC.00825-17;10.1128/JCM.06860-11 | 反抗 | 6851 |
| RV0005 | p.Ala504Thr | 藥品 | 氧氟沙星 | 10.1128/AAC.00825-17;10.1128/JCM.06860-11 | 反抗 | 6851 |
uj5u.com熱心網友回復:
當您想將 JSON 陣列“旋轉”到表格時,您必須將 CROSS APPLY 與 OPENJSON 結合使用。
以下查詢回傳預期結果:
SELECT a.[key] as gene, b.[key] as mutations, c.*, d.value as genome_positions
FROM OPENJSON(@txt1) a
CROSS APPLY OPENJSON(a.value) b
CROSS APPLY OPENJSON(b.value,'$.annotations')
WITH (
annotation_type nvarchar(100) '$.type'
, annotation_drug nvarchar(100) '$.drug'
, annotation_literature nvarchar(100) '$.literature'
, annotation_confers nvarchar(100) '$.confers'
) c
CROSS APPLY OPENJSON(b.value,'$.genome_positions') d
結果:
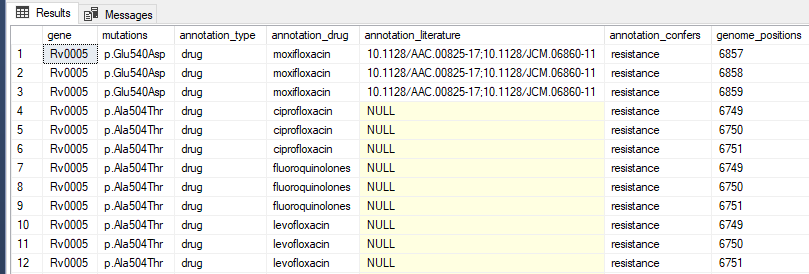
資料庫<>小提琴
uj5u.com熱心網友回復:
當 'type' 為 5 時,(kv 對的)值是一個陣列。要到達陣列的最低級別,您可以嘗試指定 JSON 模式和 OPENJSON。
/* specify explicity JSON schema */
/* to open bottom-most array */
select *
from openjson(@txt1) j
cross apply openjson(j.[value]) l1
cross apply openjson(l1.[value]) l2
cross apply openjson(l2.[value]) l3
cross apply openjson(l3.[value])
with ([type] nvarchar(4000),
drug nvarchar(4000),
literature nvarchar(4000),
confers nvarchar(4000))
where l3.[type]=5;
可以通過過濾“型別”列來訪問其余的葉級欄位。
/* open the rest of the fields */
select *
from openjson(@txt1) j
cross apply openjson(j.[value]) l1
cross apply openjson(l1.[value]) l2
cross apply openjson(l2.[value]) l3
where l3.[type]<>5;
uj5u.com熱心網友回復:
請嘗試以下解決方案。
查詢陳述句
DECLARE @json NVARCHAR(MAX) =
N'{
"Rv0005": {
"p.Glu540Asp": {
"annotations": [
{
"type": "drug",
"drug": "moxifloxacin",
"literature": "10.1128/AAC.00825-17;10.1128/JCM.06860-11",
"confers": "resistance"
}
],
"genome_positions": [
6857,
6858,
6859
]
},
"p.Ala504Thr": {
"annotations": [
{
"type": "drug",
"drug": "ciprofloxacin",
"confers": "resistance"
},
{
"type": "drug",
"drug": "fluoroquinolones",
"confers": "resistance"
},
{
"type": "drug",
"drug": "levofloxacin",
"confers": "resistance"
},
{
"type": "drug",
"drug": "moxifloxacin",
"confers": "resistance"
},
{
"type": "drug",
"drug": "ofloxacin",
"confers": "resistance"
}
],
"genome_positions": [
6749,
6750,
6751
]
},
"p.Ala504Val": {
"annotations": [
{
"type": "drug",
"drug": "ciprofloxacin",
"confers": "resistance"
},
{
"type": "drug",
"drug": "fluoroquinolones",
"confers": "resistance"
},
{
"type": "drug",
"drug": "levofloxacin",
"confers": "resistance"
},
{
"type": "drug",
"drug": "moxifloxacin",
"confers": "resistance"
},
{
"type": "drug",
"drug": "ofloxacin",
"confers": "resistance"
}
],
"genome_positions": [
6749,
6750,
6751
]
}
},
"Rv2043c": {
"p.Thr100Ile": {
"annotations": [
{
"type": "drug",
"drug": "pyrazinamide",
"literature": "10.1128/JCM.01214-17",
"confers": "resistance"
}
],
"genome_positions": [
2288942,
2288943,
2288944
]
},
"p.Thr160Ala": {
"annotations": [
{
"type": "drug",
"drug": "pyrazinamide",
"literature": "10.1128/JCM.01214-17",
"confers": "resistance"
}
],
"genome_positions": [
2288762,
2288763,
2288764
]
},
"c.101_102insT": {
"annotations": [
{
"type": "drug",
"drug": "pyrazinamide",
"confers": "resistance"
}
],
"genome_positions": [
2289140,
2289141
]
}
}
}';
-- test if it is a legit JSON
SELECT ISJSON(@json) AS Result;
SELECT genes.[Key] AS gene
, mutations.[Key] AS mutation
, annotations.*
, JSON_VALUE(mutations.value, '$.genome_positions[0]') as [gen_pos1]
, JSON_VALUE(mutations.value, '$.genome_positions[1]') as [gen_pos2]
, JSON_VALUE(mutations.value, '$.genome_positions[2]') as [gen_pos3]
FROM OPENJSON (@json) AS genes
CROSS APPLY OPENJSON(genes.value) AS mutations
CROSS APPLY OPENJSON(mutations.value, '$.annotations')
WITH
(
[type] VARCHAR(20) '$.type'
, [drug] VARCHAR(20) '$.drug'
, [literature] VARCHAR(200) '$.literature'
, [confers] VARCHAR(20) '$.confers'
) AS annotations
輸出
--------- --------------- ------ ------------------ ------------------------------------------- ------------ ---------- ---------- ----------
| gene | mutation | type | drug | literature | confers | gen_pos1 | gen_pos2 | gen_pos3 |
--------- --------------- ------ ------------------ ------------------------------------------- ------------ ---------- ---------- ----------
| Rv0005 | p.Glu540Asp | drug | moxifloxacin | 10.1128/AAC.00825-17;10.1128/JCM.06860-11 | resistance | 6857 | 6858 | 6859 |
| Rv0005 | p.Ala504Thr | drug | ciprofloxacin | NULL | resistance | 6749 | 6750 | 6751 |
| Rv0005 | p.Ala504Thr | drug | fluoroquinolones | NULL | resistance | 6749 | 6750 | 6751 |
| Rv0005 | p.Ala504Thr | drug | levofloxacin | NULL | resistance | 6749 | 6750 | 6751 |
| Rv0005 | p.Ala504Thr | drug | moxifloxacin | NULL | resistance | 6749 | 6750 | 6751 |
| Rv0005 | p.Ala504Thr | drug | ofloxacin | NULL | resistance | 6749 | 6750 | 6751 |
| Rv0005 | p.Ala504Val | drug | ciprofloxacin | NULL | resistance | 6749 | 6750 | 6751 |
| Rv0005 | p.Ala504Val | drug | fluoroquinolones | NULL | resistance | 6749 | 6750 | 6751 |
| Rv0005 | p.Ala504Val | drug | levofloxacin | NULL | resistance | 6749 | 6750 | 6751 |
| Rv0005 | p.Ala504Val | drug | moxifloxacin | NULL | resistance | 6749 | 6750 | 6751 |
| Rv0005 | p.Ala504Val | drug | ofloxacin | NULL | resistance | 6749 | 6750 | 6751 |
| Rv2043c | p.Thr100Ile | drug | pyrazinamide | 10.1128/JCM.01214-17 | resistance | 2288942 | 2288943 | 2288944 |
| Rv2043c | p.Thr160Ala | drug | pyrazinamide | 10.1128/JCM.01214-17 | resistance | 2288762 | 2288763 | 2288764 |
| Rv2043c | c.101_102insT | drug | pyrazinamide | NULL | resistance | 2289140 | 2289141 | NULL |
--------- --------------- ------ ------------------ ------------------------------------------- ------------ ---------- ---------- ----------
uj5u.com熱心網友回復:
使用臨時表可以更輕松地從展開的 json 中透視資料。
DECLARE @txt1 varchar(max) = '{...}' IF OBJECT_ID('tempdb..#tmpJsonUnfolded', 'U') IS NOT NULL DROP TABLE #tmpJsonUnfolded; SELECT lvl1.[key] as gene , lvl2.[key] as mutations , lvl3.[key] as data_class , lvl4.[key] as num , lvl5.[key] as col , case when lvl3.[key] = 'genome_positions' then lvl4.[value] when lvl3.[key] = 'annotations' then lvl5.[value] end as [value] --, lvl4.[value] as value4 --, lvl5.[value] as value5 INTO #tmpJsonUnfolded FROM OPENJSON(@txt1) lvl1 CROSS APPLY OPENJSON(lvl1.value) lvl2 CROSS APPLY OPENJSON(lvl2.value) lvl3 CROSS APPLY OPENJSON(lvl3.value) lvl4 OUTER APPLY ( SELECT * FROM OPENJSON(lvl4.value) WHERE lvl3.[key] = 'annotations' ) lvl5;
select gene , mutations , [type] as annotation_type , [num] as annotation_num , [drug] as annotation_drug , [literature] as annotation_literature , [confers] as annotation_confers , [genome_positions] from ( select gene , mutations , num , [col] , [value] from #tmpJsonUnfolded where data_class = 'annotations' union all select gene , mutations , 0 , data_class as [col] , string_agg([value], ', ') as [value] from #tmpJsonUnfolded where data_class = 'genome_positions' group by gene, mutations, data_class ) src pivot ( max([value]) for [col] in ([type], [drug], [literature], [confers], [genome_positions]) ) pvt
基因 | 突變| annotation_type | annotation_num | annotation_drug | annotation_literature | annotation_confers | 基因組位置 :------ | :------------ | :-------------- | -------------: | :--------------- | :---------------------------------------- | :----------------- | :------------------------ RV0005 | p.Ala504Thr | 藥| 0 | 環丙沙星| 空 | 抵抗| 6749、6750、6751 RV0005 | p.Ala504Thr | 藥| 1 | 氟喹諾酮類| 空 | 抵抗| 空 Rv0005 | p.Ala504Thr | 藥| 2 | 左氧氟沙星| 空 | 抵抗| 空 Rv0005 | p.Ala504Thr | 藥| 3 | 莫西沙星| 空 | 抵抗| 空 Rv0005 | p.Ala504Thr | 藥| 4 | 氧氟沙星| 空 | 抵抗|空 Rv0005 | p.Ala504Val | 藥| 0 | 環丙沙星| 空 | 抵抗| 6749、6750、6751 RV0005 | p.Ala504Val | 藥| 1 | 氟喹諾酮類| 空 | 抵抗| 空 Rv0005 | p.Ala504Val | 藥| 2 | 左氧氟沙星| 空 | 抵抗| 空 Rv0005 | p.Ala504Val | 藥| 3 | 莫西沙星| 空 | 抵抗| 空 Rv0005 | p.Ala504Val | 藥| 4 | 氧氟沙星| 空 | 抵抗|空值 RV0005 | p.Glu540Asp | 藥| 0 | 莫西沙星| 10.1128/AAC.00825-17;10.1128/JCM.06860-11 | 抵抗| 6857、6858、6859 Rv2043c | c.101_102insT | 藥| 0 | 吡嗪酰胺| 空 | 抵抗| 2289140、2289141 Rv2043c | p.Thr100Ile | 藥| 0 | 吡嗪酰胺| 10.1128/JCM.01214-17 | 抵抗| 2288942、2288943、2288944 Rv2043c | p.Thr160Ala | 藥| 0 | 吡嗪酰胺| 10.1128/JCM.01214-17 | 抵抗| 2288762、2288763、2288764
關于db<>fiddle 的演示在這里
轉載請註明出處,本文鏈接:https://www.uj5u.com/net/388482.html
標籤:数组 json sql-server 查询语句 打开-json