給定資料框中數字變數名稱的向量,我需要計算每個變數的均值和標準差。例如,給定mtcars資料集和以下變數名稱向量:
vars_to_transform <- c("mpg", "disp")
我希望得到以下結果:
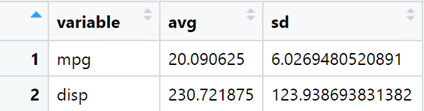
我想到的第一個解決方案如下:
library(dplyr)
library(purrr)
data("mtcars")
vars_to_transform <- c("mpg", "disp")
vars_to_transform %>%
map_dfr( function(x) { c(variable = x, avg = mean(mtcars[[x]], na.rm = T), sd = sd(mtcars[[x]], na.rm = T)) } )
結果如下:

正如你所看到的,所有回傳的變數是文字,但我預計將有號碼avg和sd。
有沒有辦法解決這個問題?或者有比這更好的解決方案嗎?
PS我使用的是purr0.3.4
uj5u.com熱心網友回復:
以下作業(而不是c()在您的代碼中使用,使用tibble):
vars_to_transform %>%
map_dfr(~ tibble(variable = .x, avg = mean(mtcars[[.x]], na.rm = T),
sd = sd(mtcars[[.x]], na.rm = T)))
說明: With c(),您正在使用一個向量,其元素必須具有相同的型別(character在您的情況下,因為variable是character)。使用tibble,每個元素可以有不同的型別。
@廣津金所暗示的,在下面評論,我感謝,一個則還可以使用list代替tibble。
或嘗試添加type.convert:
library(dplyr)
library(purrr)
data("mtcars")
vars_to_transform <- c("mpg", "disp")
vars_to_transform %>%
map_dfr( function(x) { c(variable = x, avg = mean(mtcars[[x]], na.rm = T), sd = sd(mtcars[[x]], na.rm = T)) } ) %>%
type.convert(as.is=T)
#> # A tibble: 2 × 3
#> variable avg sd
#> <chr> <dbl> <dbl>
#> 1 mpg 20.1 6.03
#> 2 disp 231. 124.
uj5u.com熱心網友回復:
似乎是一種過于復雜的做法select-> pivot-> group-> summarise。
mtcars %>%
select(all_of(vars_to_transform)) %>%
pivot_longer(everything()) %>%
group_by(name) %>%
summarise(
mean = mean(value),
sd = sd(value)
)
# A tibble: 2 x 3
name mean sd
<chr> <dbl> <dbl>
1 disp 231. 124.
2 mpg 20.1 6.03
uj5u.com熱心網友回復:
另外一個選擇:
library(purrr)
library(dplyr)
vars_to_transform <- c("mpg", "disp")
funs <- lst(mean, sd)
mtcars %>%
select(all_of(vars_to_transform)) %>%
map_df(~ funs %>%
map(exec, .x), .id = "var")
# A tibble: 2 x 3
var mean sd
<chr> <dbl> <dbl>
1 mpg 20.1 6.03
2 disp 231. 124.
uj5u.com熱心網友回復:
m <- mtcars %>% select(vars_to_transform)
tibble(variable = names(m), avg = apply(m, 2, mean), sd = apply(m, 2, sd))
## A tibble: 2 × 3
# variable avg sd
# <chr> <dbl> <dbl>
#1 mpg 20.1 6.03
#2 disp 231. 124.
轉載請註明出處,本文鏈接:https://www.uj5u.com/net/389580.html
上一篇:根據R中另一列的值計算一列的值