我正在使用 Pytorch 進行二元分類任務,但我的模型無法學習,我無法確定是模型問題還是資料問題。
這是我的模型:
from torch import nn
class RNN(nn.Module):
def __init__(self, input_dim):
super(RNN, self).__init__()
self.rnn = nn.RNN(input_size=input_dim, hidden_size=64,
num_layers=2,
batch_first=True, bidirectional=True)
self.norm = nn.BatchNorm1d(128)
self.rnn2 = nn.RNN(input_size=128, hidden_size=64,
num_layers=2,
batch_first=True, bidirectional=False)
self.drop = nn.Dropout(0.5)
self.fc7 = nn.Linear(64, 2)
self.sigmoid2 = nn.Softmax(dim=2)
def forward(self, x):
out, h_n = self.rnn(x)
out = out.permute(0, 2, 1)
out = self.norm(out)
out = out.permute(0, 2, 1)
out, h_n = self.rnn2(out)
out = self.drop(out)
out = self.fc7(out)
out = self.sigmoid2(out)
return out.squeeze()
該模型由兩個 RNN 層組成,中間有一個 BatchNorm,然后是一個 Dropout 和最后一層,我使用具有兩個類的 Softmax 函式而不是 Sigmoid 進行評估。
然后我創建并訓練模型:
model = RNN(2476)
optimizer = torch.optim.Adam(model.parameters(), lr=1e-4)
loss_function = nn.CrossEntropyLoss()
lr_scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=30, gamma=0.1)
model.train()
EPOCHS = 25
BATCH_SIZE = 64
epoch_loss = []
for ii in range(EPOCHS):
for i in range(1, X_train.size()[0]//BATCH_SIZE 1):
x_train = X_train[(i-1)*BATCH_SIZE:i*BATCH_SIZE]
labels = y_train[(i-1)*BATCH_SIZE:i*BATCH_SIZE]
optimizer.zero_grad()
y_pred = model(x_train)
y_pred = y_pred.round()
single_loss = loss_function(y_pred, labels.long().squeeze())
single_loss.backward()
optimizer.step()
lr_scheduler.step()
print(f"\rBatch {i}/{X_train.size()[0]//BATCH_SIZE 1} Trained: {i*BATCH_SIZE}/{X_train.size()[0]} Loss: {single_loss.item():10.8f} Step: {lr_scheduler.get_lr()}", end="")
epoch_loss.append(single_loss.item())
print(f'\nepoch: {ii:3} loss: {single_loss.item():10.8f}')
這是訓練模型時的輸出:
Batch 353/354 Trained: 22592/22644 Loss: 0.86013699 Step: [1.0000000000000007e-21]
epoch: 0 loss: 0.86013699
Batch 353/354 Trained: 22592/22644 Loss: 0.81326193 Step: [1.0000000000000014e-33]
epoch: 1 loss: 0.81326193
Batch 353/354 Trained: 22592/22644 Loss: 0.87576205 Step: [1.0000000000000022e-45]
epoch: 2 loss: 0.87576205
Batch 353/354 Trained: 22592/22644 Loss: 0.92263710 Step: [1.0000000000000026e-57]
epoch: 3 loss: 0.92263710
Batch 353/354 Trained: 22592/22644 Loss: 0.90701210 Step: [1.0000000000000034e-68]
epoch: 4 loss: 0.90701210
Batch 353/354 Trained: 22592/22644 Loss: 0.92263699 Step: [1.0000000000000039e-80]
epoch: 5 loss: 0.92263699
Batch 353/354 Trained: 22592/22644 Loss: 0.82888693 Step: [1.0000000000000044e-92]
epoch: 6 loss: 0.82888693
Batch 353/354 Trained: 22592/22644 Loss: 0.81326193 Step: [1.000000000000005e-104]]
epoch: 7 loss: 0.81326193
Batch 353/354 Trained: 22592/22644 Loss: 0.87576205 Step: [1.0000000000000055e-115]
epoch: 8 loss: 0.87576205
Batch 353/354 Trained: 22592/22644 Loss: 0.82888693 Step: [1.0000000000000062e-127]
epoch: 9 loss: 0.82888693
Batch 353/354 Trained: 22592/22644 Loss: 0.81326199 Step: [1.0000000000000067e-139]
epoch: 10 loss: 0.81326199
Batch 353/354 Trained: 22592/22644 Loss: 0.82888693 Step: [1.0000000000000072e-151]
epoch: 11 loss: 0.82888693
Batch 353/354 Trained: 22592/22644 Loss: 0.89138699 Step: [1.0000000000000076e-162]
epoch: 12 loss: 0.89138699
Batch 353/354 Trained: 22592/22644 Loss: 0.82888699 Step: [1.000000000000008e-174]]
epoch: 13 loss: 0.82888699
Batch 353/354 Trained: 22592/22644 Loss: 0.82888687 Step: [1.0000000000000089e-186]
epoch: 14 loss: 0.82888687
Batch 353/354 Trained: 22592/22644 Loss: 0.82888693 Step: [1.0000000000000096e-198]
epoch: 15 loss: 0.82888693
Batch 353/354 Trained: 22592/22644 Loss: 0.84451199 Step: [1.0000000000000103e-210]
epoch: 16 loss: 0.84451199
Batch 353/354 Trained: 22592/22644 Loss: 0.96951205 Step: [1.0000000000000111e-221]
epoch: 17 loss: 0.96951205
Batch 353/354 Trained: 22592/22644 Loss: 0.87576205 Step: [1.0000000000000117e-233]
epoch: 18 loss: 0.87576205
Batch 353/354 Trained: 22592/22644 Loss: 0.89138705 Step: [1.0000000000000125e-245]
epoch: 19 loss: 0.89138705
Batch 353/354 Trained: 22592/22644 Loss: 0.79763699 Step: [1.0000000000000133e-257]
epoch: 20 loss: 0.79763699
Batch 353/354 Trained: 22592/22644 Loss: 0.84451199 Step: [1.0000000000000138e-268]
epoch: 21 loss: 0.84451199
Batch 353/354 Trained: 22592/22644 Loss: 0.84451205 Step: [1.0000000000000146e-280]
epoch: 22 loss: 0.84451205
Batch 353/354 Trained: 22592/22644 Loss: 0.79763693 Step: [1.0000000000000153e-292]
epoch: 23 loss: 0.79763693
Batch 353/354 Trained: 22592/22644 Loss: 0.87576205 Step: [1.000000000000016e-304]]
epoch: 24 loss: 0.87576205
這是每個時期的損失:
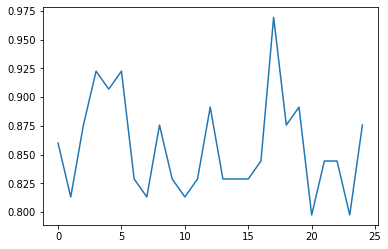
對于資料,輸入資料中的每個特征的維度為(2474,),目標具有 1 個維度([1]或[0]),然后我將sequence length維度 ( 1)添加到RNN層的輸入資料中:
X_train.size(), X_test.size(), y_train.size(), y_test.size()
(torch.Size([22644, 1, 2474]),
torch.Size([5661, 1, 2474]),
torch.Size([22644, 1]),
torch.Size([5661, 1]))
目標類分布:
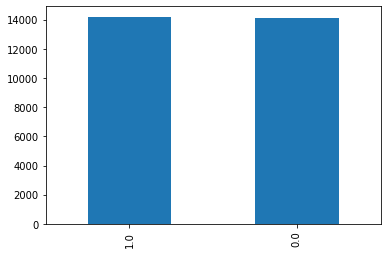
我不明白為什么我的模型沒有學習,課程是平衡的,我沒有通知資料有任何問題。有什么建議?
uj5u.com熱心網友回復:
這不是您問題的直接解決方案,但是導致這種架構的程序是什么?我發現如果只是為了讓識別問題變得更簡單(我在問題出現之前添加了什么?),迭代地建立復雜性很有幫助。
為了節省迭代構建 RNN 的時間,您可以嘗試單批次訓練,通過該訓練構建一個可以過擬合單個訓練批次的網路。如果您的網路可以過擬合單個訓練批次,則它應該足夠復雜以學習訓練資料中的特征。
一旦您擁有可以輕松過擬合單個訓練批次的架構,您就可以使用整個訓練集進行訓練,并探索其他策略以通過正則化來解決過擬合問題。
您的模型似乎并不過分復雜,但這可能意味著從單個 rnn 層和單個線性層開始,看看您的損失是否會在單個批次上發生變化。
轉載請註明出處,本文鏈接:https://www.uj5u.com/net/391422.html
上一篇:在運行歷史記錄中找不到有效模型。這意味著smac無法擬合有效模型。請檢查日志檔案是否有錯誤
下一篇:前一個等待合并時的新拉取請求