如何確定多引數模型的后驗估計的置信/可信區間?
我可以分別得到每個引數的置信區間。(目前正在使用bayestestR,但我不介意使用其他東西)
library(dplyr)
library(ggplot2)
library(bayestestR)
N <- 10000
#Posterior samples (random example)
p1 <- rnorm(N)
p2 <- p1 rnorm(N)
df_post <- tibble(p1,p2)
describe_posterior(
df_post,
centrality = "median",
test = c("p_direction", "p_significance")
)
##Yields:
# Summary of Posterior Distribution
#
# Parameter | Median | 95% CI | pd | ps
# -----------------------------------------------------
# p1 | 0.02 | [-1.85, 2.08] | 50.64% | 0.46
# p2 | -2.24e-03 | [-2.82, 2.78] | 50.04% | 0.47
我可以用點和 2D 輪廓生成一個圖,這給了我后驗分布的視覺指示(雖然我不知道每個輪廓代表什么百分比):
ggplot(df_post, aes(x=p1, y=p2))
geom_density_2d(size=1)
geom_point(size=0.1)
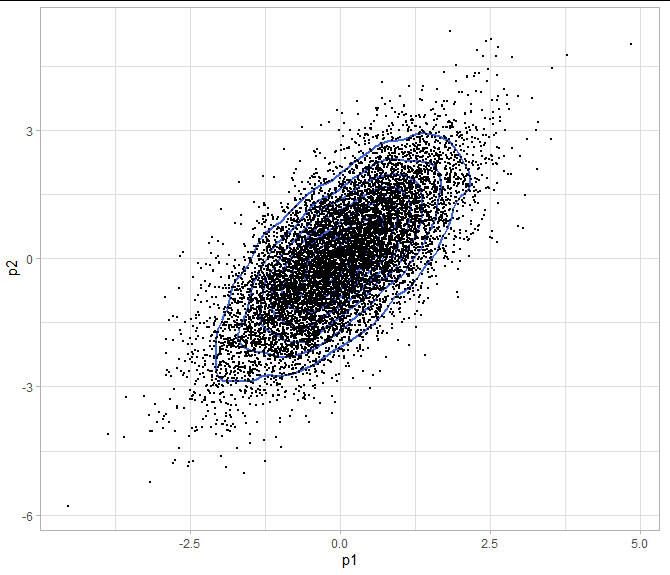
我的問題是,我如何實際計算(和/或繪制)二維 X% 可信區間?
uj5u.com熱心網友回復:
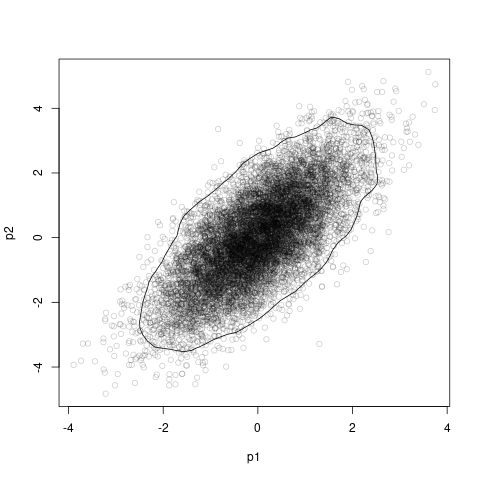
這是一個 base-R-plotting 解決方案,它根據二維核密度估計繪制了 95% 的最高后驗密度區域:
library(emdbook)
library(coda)
HPDregionplot(as.mcmc(df_post))
with(df_post, points(p1, p2, col = adjustcolor("black", alpha.f = 0.2)))
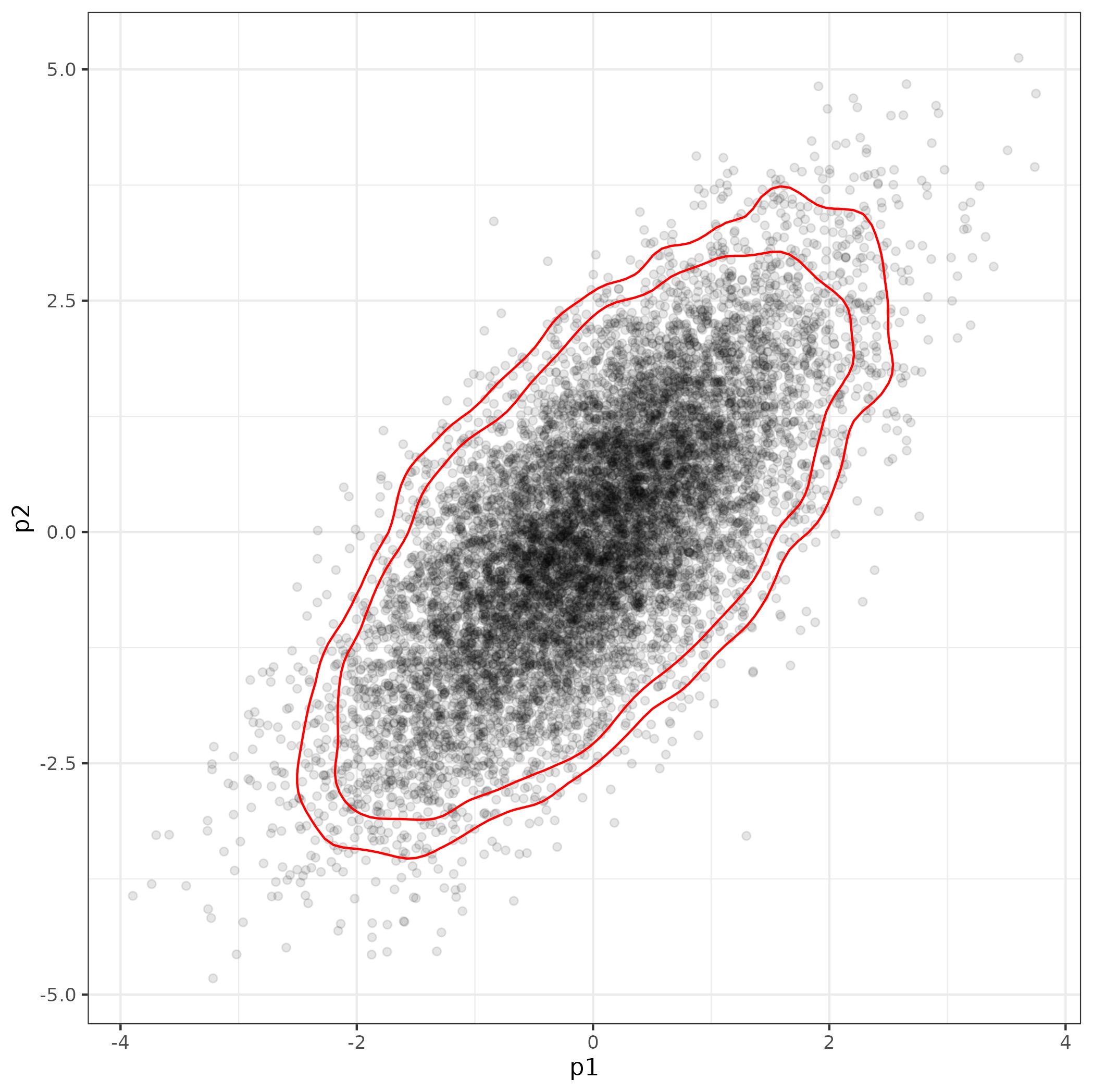
更順利/在ggplot:
library(ggplot2); theme_set(theme_bw())
## see function definition below
L <- with(df_post, get_hpd2d_levels(p1, p2))
gg0 <- ggplot(df_post, aes(p1, p2)) geom_point(alpha=0.1)
geom_density_2d(breaks = L, colour="red")
print(gg0)
最高后驗密度區域是經典的貝葉斯方法。如果您想深入研究,您可以查看一些用于計算中心集(袋圖、功能深度等)的引數較少的方法。這類似于最高后驗密度區域和基于分位數的可信區間之間的差異。
##' Get 2D highest posterior density levels corresponding to probability regions
##' @param x x-coordinate of samples
##' @param y y-coordinate
##' @param probs vector of probability levels
##' @param ... arguments for MASS::kde2d
##' @examples
##' dd <- data.frame(x=rnorm(1000), y=rnorm(1000))
##' get_hpd2d_levels(dd$x,dd$y)
##' gg2 <- ggplot(dd, aes(x,y)) geom_density_2d(breaks=get_hpd2d_levels(dd$x,dd$y), colour="red")
##' print(gg2)
get_hpd2d_levels <- function(x, y, prob=c(0.9,0.95), ...) {
post1 <- MASS::kde2d(x, y)
dx <- diff(post1$x[1:2])
dy <- diff(post1$y[1:2])
sz <- sort(post1$z)
c1 <- cumsum(sz) * dx * dy
## remove duplicates
## dups <- duplicated(sz)
## sz <- sz[!dups]
## c1 <- c1[!dups]
levels <- sapply(prob, function(x) {
approx(c1, sz, xout = 1 - x, ties = mean)$y
})
return(levels)
}
uj5u.com熱心網友回復:
@Ben Bolker 的回答很有效,但這里有另一個建議(基于@dash2 的評論)也有效:
car::dataEllipse(p1, p2, levels=0.95)
轉載請註明出處,本文鏈接:https://www.uj5u.com/net/403224.html
標籤:
下一篇:每個變數有多個列的分組頻率表