我有一個腳本,用于存盤str從各種網站請求的XML(另存為's)。即使 SQL 列型別為 ,其中一些請求也會被截斷NVARCHAR(MAX)。我需要知道為什么。我不確定它是時間問題(回應在完成下載之前存盤到 SQL)還是分頁(?)問題。
該問題出現在 62k 到 65k 字符及以上。低于此字符數的任何內容都會正確保存檔案。
代碼:
import urllib.error
import urllib.request
from bs4 import BeautifulSoup
def get_feed(url):
try:
header = {'User-Agent': 'Mozilla/5.0'}
request = urllib.request.Request(url=url, headers=header)
response = urllib.request.urlopen(request)
xml = BeautifulSoup(response, 'xml')
return xml
except urllib.error.HTTPError as response:
return None
def get_sql_connection():
try:
server = 'mydb.database.windows.net'
database = 'mydb'
driver= '{ODBC Driver 17 for SQL Server}'
conn_string = 'DRIVER=' driver ';SERVER=' server ';DATABASE=' database
conn = pyodbc.connect(conn_string ';Authentication=ActiveDirectoryMsi')
return conn
except Exception as e:
logging.error(e)
return None
def write_xml(conn, xml):
end_format = '%Y-%m-%dT%H:%M:%S%z'
cursor = conn.cursor()
data = {
"xml_doc": str(xml),
"created": datetime.now(timezone(timedelta(hours=-8))).strftime(end_format)}
cursor.execute("INSERT INTO dbo.XML (xml_doc, created) VALUES (?,?)", data['xml_doc'], data['created'])
conn.commit()
#-------------------------
conn = get_sql_connection()
url = 'https://example.com'
xml = get_feed(url)
write = write_feed_table(conn, xml)
再次......任何超出 ~62k-65k 的字符數,都將xml被截斷。
uj5u.com熱心網友回復:
64K 是一種神奇的數字,尤其是對于 XML,但一些提供商和其他軟體也會代表您發出短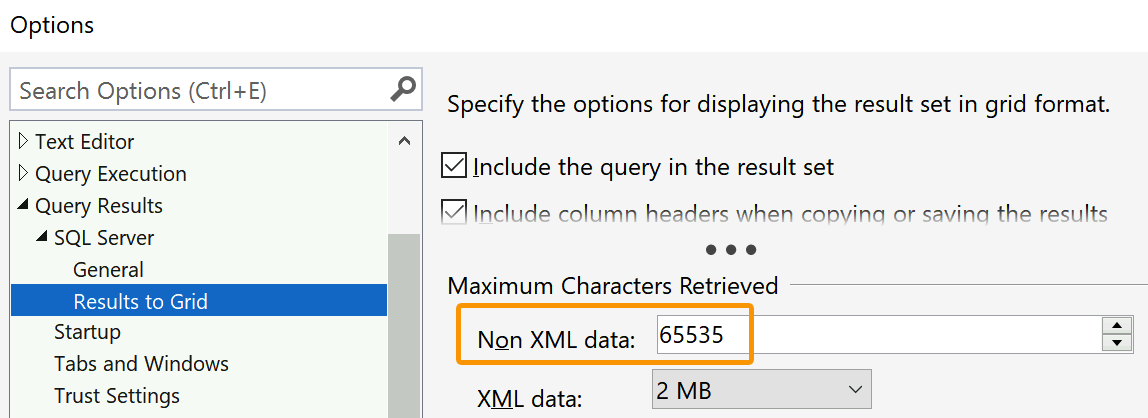
你可以增加這個數字,但我承認我沒怎么玩過它。特別是對于 XML(有時甚至不是XML),最好將輸出顯示為適當的 XML 列。這使它成為網格中的一個可單擊單元格,當您單擊時,它會打開一個不會像文本輸出那樣被截斷的檔案(好吧,除非您超過默認的最大 2 MB,您也可以將其增加到 5MB,或者,如果你真的很勇敢,無限)。
有關其他一些潛在的解決方法,請參閱:
- 您如何在 SSMS 中查看來自 ntext 或 nvarchar(max) 的所有文本?
- 如何從 SSMS 獲取完整的結果集
轉載請註明出處,本文鏈接:https://www.uj5u.com/net/404973.html
標籤:
上一篇:資料查詢,保留常用資料