我有一些 (x, y, class) 格式的資料,如下所示:
data = [(1, 2, 'A'), (2, 3, 'A'), (3, 4, 'A'), (4, 5, 'A'), (5, 6, 'A'), (1, 4, 'B'), (2, 5, 'B'), (3, 6, 'B'), (4, 7, 'B'), (5, 8, 'B'), (1, 3, 'C'), (2, 4, 'C'), (3.1, 5, 'C'), (4.1, 6, 'C'), (5.1, 7, 'C')]
我想用pandas. 如果有人使用命令:
import pandas as pd
import matplotlib.pyplot as plt
df = pd.DataFrame(data, columns = ['x', 'y', 'c'])
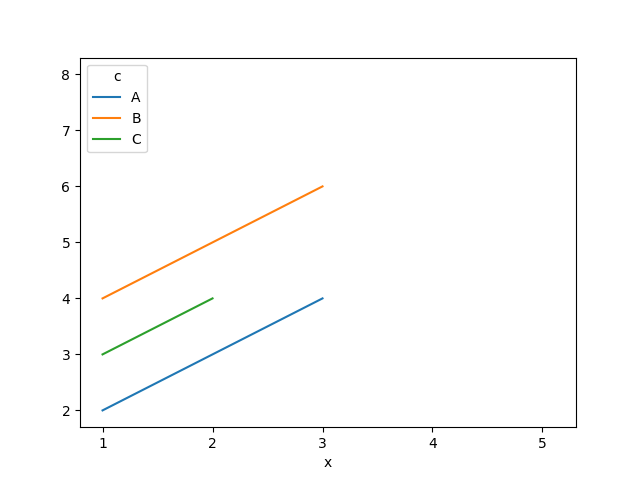
df.pivot(index = 'x', columns = 'c', values = 'y').plot()
plt.show()
輸出如下
相反,如果我們使用以下方法洗掉 C 類:
import pandas as pd
import matplotlib.pyplot as plt
df = pd.DataFrame(data, columns = ['x', 'y', 'c'])
df[df['c'].isin(['A', 'B'])].pivot(index = 'x', columns = 'c', values = 'y').plot()
plt.show()
輸出是
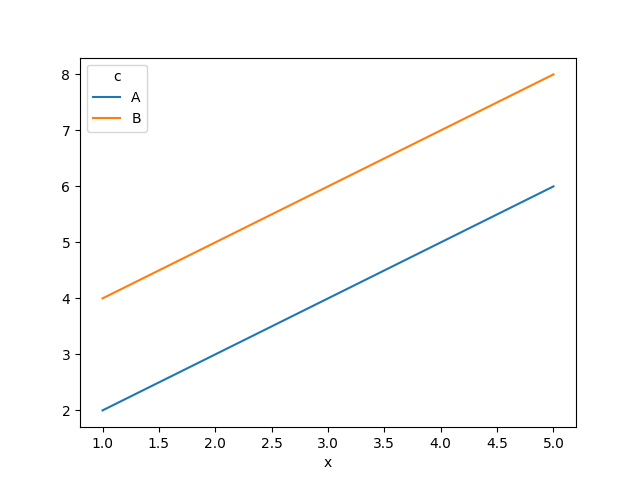
這很簡單:因為 C 類有一些不同的x值,我們最終nan會在值列中得到一些結果,這意味著 pandas 無法繪制資料。
我可以interpolate用來填充缺失的值,因為我的資料并不是非常大,但是我的資料規模足夠大,因此將類'C'與其他兩個一起繪制在圖的頂部會更有意義,這意味著它需要到
- 被添加到圖例中
- 完整地出現在劇情中
我怎樣才能做到這一點?
uj5u.com熱心網友回復:
使用起來seaborn很簡單lineplot。
import seaborn as sns
sns.lineplot(data=df, x='x', y='y', hue='c')
pandas 的另一個選項是groupby.
fig, ax = plt.subplots(figsize=(8,6))
for _label, _dfg in df.groupby('c'):
_dfg.plot(x='x',y='y', ax=ax, label=_label)
轉載請註明出處,本文鏈接:https://www.uj5u.com/net/406726.html
標籤: