我正在嘗試使用多個表創建一個雪花視圖。我知道 FROM...JOIN 陳述句可以組合多個表。
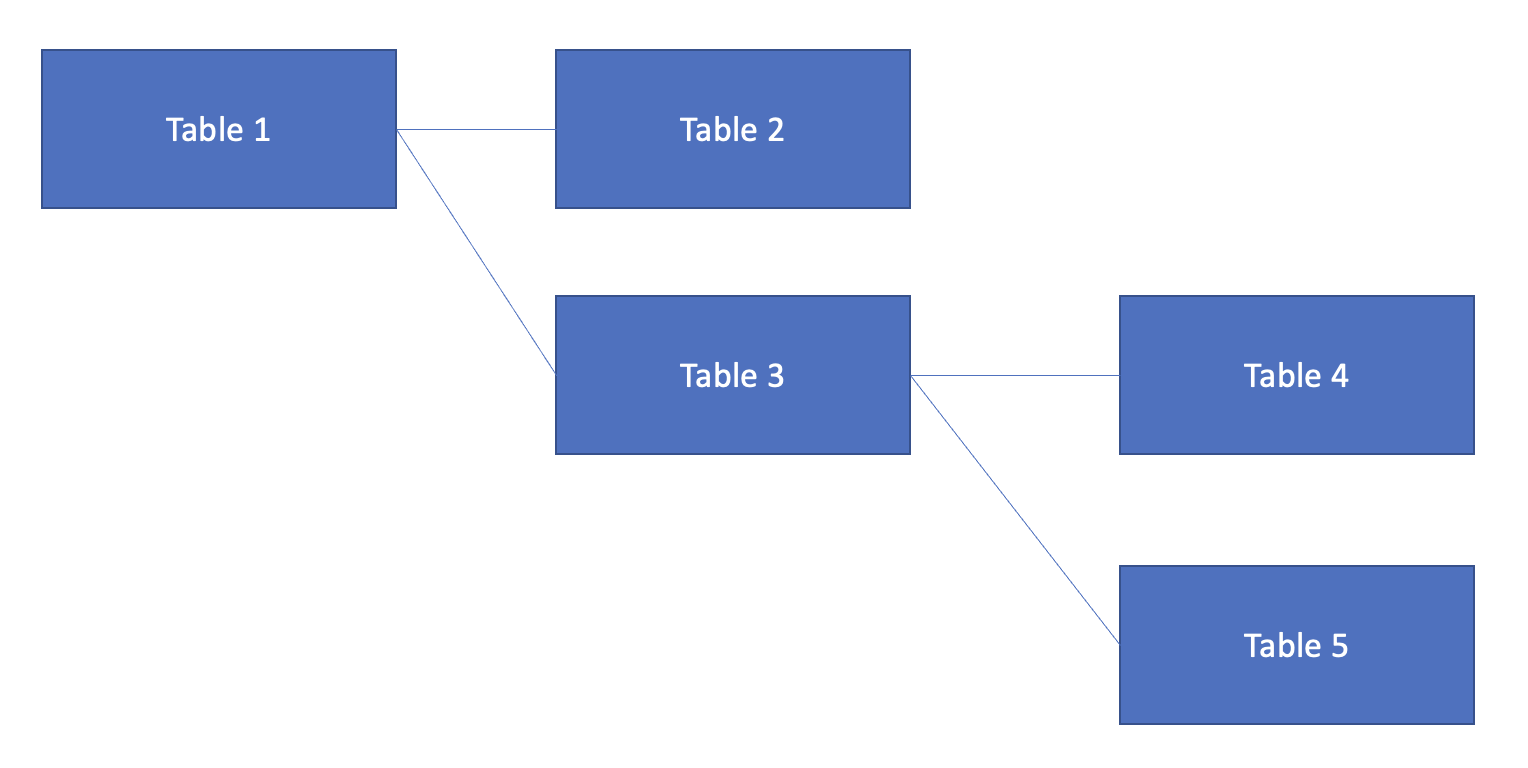
當我想從一個已經從另一個表連接的表中加入時,撰寫腳本的最佳方法是什么?在這種情況下,從表 3 開始,將表 4 和表 5 連接起來。表 3 由表 1 連接而成。
uj5u.com熱心網友回復:
您的問題不清楚,但通常所有表格joined如下
select *
from table1 t1
join table2 t2 on t1.id = t2.table1_ID
join table3 t3 on t1.id = t3.table1_ID
join table4 t4 on t3.id = t4.table3_ID
join table5 t5 on t3.id = t5.table3_ID
你的資料并不清楚你需要什么樣的資料,但這取決于你的需求,你需要什么樣的資訊與什么樣的表格組合。
with cte1 as (
select *
from table1 t1
join table2 t2 on t1.id = t2.table1_ID
join table3 t3 on t1.id = t3.table1_ID
),
cte2 as (
select *
from table3 t3
join table4 t4 on t3.id = t4.table3_ID
join table5 t5 on t3.id = t5.table3_ID)
select t123.column1, t345.column2
from cte1 join cte2 on cte1.id = cte2.id
uj5u.com熱心網友回復:
您應該能夠完全加入您列出的關系層次結構,例如
select
t1.*,
t2.whatever,
t3.whatever3,
t4.whatever4,
t5.whatever5
from
table1 t1
join table2 t2
on t1.t2id = t2.id
join table3 t3
on t1.t3id = t3.id
join table4 t4
on t3.t4id = t4.id
join table5 t5
on t3.t5id = t5.id
那么,什么是困惑
uj5u.com熱心網友回復:
Meysam 的回答非常有效,但我看到手頭還有更多問題。
[編輯] 這個答案大多是一般性的,但也側重于 Snowflake-cloud-data-platform 標簽的角度。
通常,您可以有一個 SELECT 塊,并且 FROM JOIN 區域中的所有 TABLES 以及您喜歡的所有 WHERE,以現代形式,屬于 JOINS 而不是過濾器的 WHERE 被置于 ON,因此 Meysam 的回答.
SELECT
t1.thing,
t2.other_thing,
t4.extra_detail,
t5.one_last_thing
FROM table1 t1
JOIN table2 t2
ON t1.id = t2.table1_ID
JOIN table3 t3
ON t1.id = t3.table1_ID
JOIN table4 t4
ON t3.id = t4.table3_ID
JOIN table5 t5
ON t3.id = t5.table3_ID
現在你提到了一個可以在 table3 鏈上完成的 CTE,如果有這樣的優點:
WITH table_3_sub_chain_cte_of_merit AS (
SELECT
t3.table1_ID
t4.extra_detail,
t5.one_last_thing
FROM table3 t3
JOIN table4 t4
ON t3.id = t4.table3_ID
JOIN table5 t5
ON t3.id = t5.table3_ID
)
SELECT
t1.thing,
t2.other_thing,
cte3.extra_detail,
cte3.one_last_thing
FROM table1 t1
JOIN table2 t2
ON t1.id = t2.table1_ID
JOIN table_3_sub_chain_cte_of_merit cte3
ON t1.id = cte3.table1_ID
或者 CTE 子運算式可以移動到子選擇中,如果有優點的話,像這樣:
SELECT
t1.thing,
t2.other_thing,
cte3.extra_detail,
cte3.one_last_thing
FROM table1 t1
JOIN table2 t2
ON t1.id = t2.table1_ID
JOIN (
SELECT
t3.table1_ID
t4.extra_detail,
t5.one_last_thing
FROM table3 t3
JOIN table4 t4
ON t3.id = t4.table3_ID
JOIN table5 t5
ON t3.id = t5.table3_ID
)cte3
ON t1.id = cte3.table1_ID
現在有趣的部分,優點,我們為什么要做這些事情。
如果您只想從每張桌子上獲得一些價值并繼續前進,那么第一個版本應該可以很好地滿足您的需求。但是如果你在上面table3和下面做一些復雜的過濾器,或者你在下面和下面做一些昂貴的聚合table3,但是這些結果多次匹配table1,那么在 CTE 或子查詢中進行作業是有意義的。
現在為什么要在子查詢上使用 CTE,代碼的簡單答案是相同的。但是,如果你加入table1和table3多次,因為你每天計算成本,每周費用和每月費用,然后再建一次的費用(在CTE),然后加入這些結果可以節省大量的時間。但同時,有時 CTE 會減慢速度,因為一旦考慮到其他作業,看起來“昂貴的代碼”大部分都是免費的,因此我看到代碼在 Snowflake 上運行得更快,進行了 3 次大型聚合在子選擇中,因為它消除了資料路徑之間的同步成本,并且遠程資料讀取在兩者下都是相同的瓶頸。
另一方面,有時 CTE 會使代碼閱讀更清晰,因為您可以將運算式命名為有意義的東西,然后使用別名,因此 SQL 更具可讀性,但意圖被捕獲。無論如何,Snowflake 優化器都會重寫 SQL,其中一些可以并且通常是相同的。所以幫助人類更有價值。
在其他資料庫上,優化器可以通過連接的順序得到幫助,并且它們是嵌套的(或者我被告知),但我沒有在雪花上閱讀/見證這一點,但花了幾天時間重寫 SQL 以使其具有“相同的執行計劃”的另一種形式。
但是 CTE 在將過濾器推送到您想要它們的位置時可能非常大(數百行 SQL),以避免讀取非常大的資料,并且只進行全表處理以進行修剪。這種事情在查詢分析器中是可以發現的,但是 100 億行在塊之間進行了許多步驟,只是為了在管道中稍后命中一個過濾器,然后有 5000 行出來。
轉載請註明出處,本文鏈接:https://www.uj5u.com/net/406866.html
標籤:
上一篇:如何使用SQL獲取以下輸出?