我有這個代碼:
d = {'col1': [1, 2, 3, 4, 5, 6], 'col2': [7, 8, 9, 10, 11, 12], 'is_new_group': [True, False, False, True, False, False] }
pd.DataFrame(d)
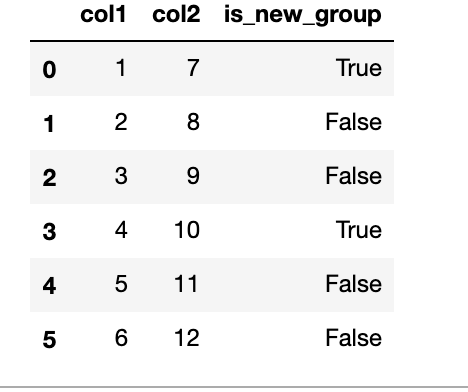
我想將資料分組。每個組將從第一行的索引處開始 where is_new_groupis True,并在新的is_new_group is時結束True
在這種情況下,它應該將資料分為 2 組:前 3 行和后 3 行:
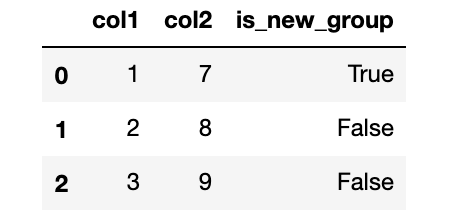
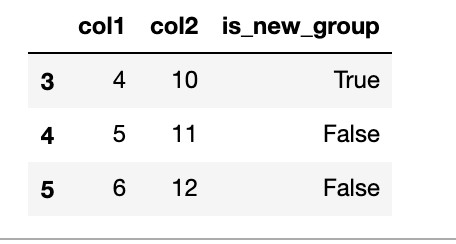
我找到了`pd.groupby```。
根據檔案,by引數:mapping, function, label, or list of labels.
但這是另一種情況。
如何根據需求對值進行分組?
uj5u.com熱心網友回復:
如果True是新組的指示符,您可以檢查它在哪里是真實的并用于cumsum創建您的組標簽。可以用來分組。
df.groupby(df.is_new_group.eq(True).cumsum())
uj5u.com熱心網友回復:
使用cumsum檢測每一個新的True。在 Python 中,True并在對它們執行計算時分別False轉換為1和0。
df.groupby(df.is_new_group.cumsum())
會做你想做的。
轉載請註明出處,本文鏈接:https://www.uj5u.com/net/409481.html
標籤:
上一篇:有沒有辦法遞回地對資料框進行子集化并將新資料框分配給唯一的變數名稱?[復制]
下一篇:列子集的條件行和dplyr