我有一個如下所示的資料框
df=pd.DataFrame({'subjects':['A','A','D','B','B','C'],
'B':['12','12','13','14','14','16'],
'C':[21,23,24,25,26,27]
})
df['r_no'] = df.groupby(['subjects','B']).cumcount() 1
現在,我只想選擇只有r_no = 1(而不是 r_no > 1)的行。
我嘗試了以下
df[df['subjects'].value_counts() == 1]
df.iloc[df['subjects'].value_counts() == 1:,]
df.ix[df['subjects'].value_counts() == 1:,]
df[(df['r_no'] == 1) & (df['r_no'] < 2)]
他們都沒有作業。
我希望我的輸出如下所示。
您可以看到subjects = A并被subjects = B排除在外,因為它們也有r_no> 1 的行。基本上,我想選擇在資料框中只有一條記錄的主題(r_no)
uj5u.com熱心網友回復:
IIUC,您想要做的只是為了保持大小為 1 的組:
df[df.groupby(['subjects','B'])['C'].transform(len).le(1)]
或者甚至只是保持具有唯一行的主題:
df[~df['subjects'].duplicated(keep=False)]
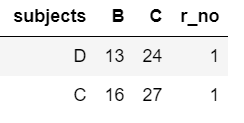
輸出:
subjects B C
2 D 13 24
5 C 16 27
uj5u.com熱心網友回復:
df[df.groupby('subjects')['r_no'].transform(lambda x: ~(x.ne(1).any()))]
subjects B C r_no
2 D 13 24 1
5 C 16 27 1
轉載請註明出處,本文鏈接:https://www.uj5u.com/net/409484.html
標籤:
下一篇:如何從資料框中提取非nan值