我正在使用 Oracle 中的示例模式之一 - 訂單輸入,表 - 產品資訊。
我注意到我的 Regex 函式中的范圍運算式沒有按預期作業。
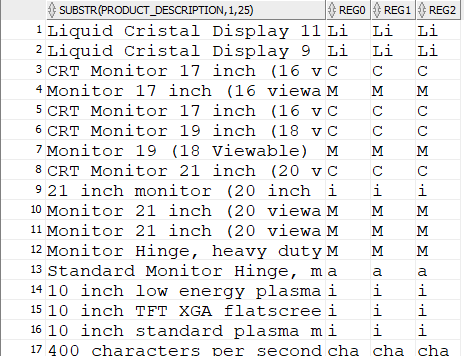
有誰知道為什么下面代碼的結果也包括小寫字母?輸出顯示在圖片上。好像是編碼的問題?通常,AZ 在 az 之前,這里的編碼似乎混合了大寫和小寫字母......
select substr(product_description, 1, 25),
regexp_substr(product_description, '[A-M] ') as reg0,
regexp_substr(product_description, '[A-M] ', 1, 1,'i') as reg1,
regexp_substr(product_description, '[A-M] ', 1, 1,'c') as reg2
from product_information;
uj5u.com熱心網友回復:
檔案說 Oracle“解釋 NLS_SORT 引數指定的范圍運算式以確定給定范圍涵蓋的排序規則元素”。
使用默認的 BINARY 排序規則和一些(簡化的)示例資料,您的查詢給出:
| SUBSTR(PRODUCT_DESCRIPTION,1,25) | 暫存器0 | REG1 | REG2 |
|---|---|---|---|
| 液體 ... | 大號 | 李 | 大號 |
| 陰極射線管... | C | C | C |
| 監視器 ... | 米 | 米 | 米 |
| 10英寸... | 空值 | 一世 | 空值 |
例如,將 NLS_SORT 更改為波蘭語(根據您的個人資料猜測)相同的查詢會得到您所看到的內容:
| SUBSTR(PRODUCT_DESCRIPTION,1,25) | 暫存器0 | REG1 | REG2 |
|---|---|---|---|
| 液體 ... | 李 | 李 | 李 |
| 陰極射線管... | C | C | C |
| 監視器 ... | 米 | 米 | 米 |
| 10英寸... | 一世 | 一世 | 一世 |
正如@LukStorms 指出的那樣,您可以通過collate binary在函式呼叫中指定來覆寫會話設定,至少在最近的版本中(我相信是 12.2 ):
select substr(product_description, 1, 25),
regexp_substr(product_description collate binary, '[A-M] ') as reg0,
regexp_substr(product_description collate binary, '[A-M] ', 1, 1,'i') as reg1,
regexp_substr(product_description collate binary, '[A-M] ', 1, 1,'c') as reg2
from product_information;
db<>fiddle演示,包括會話設定覆寫。
有關排序規則的解釋以及二進制和語言排序規則之間的區別,請參閱同一檔案的前面部分。您關于“通常,AZ 在 az 之前”的宣告反映了二進制排序規則的作業方式,至少對于那些 ASCII 范圍:
一種對字符資料進行排序的方法是基于字符編碼方案定義的字符的數值。這稱為二進制排序規則。二進制排序規則是最快的排序型別。由于 ASCII 和 EBCDIC 標準將字母 A 到 Z 定義為升序數值,因此它對英文字母產生了合理的結果。
使用語言整理比這更復雜。
轉載請註明出處,本文鏈接:https://www.uj5u.com/net/410151.html
標籤: