我希望在資料框中的列內以累積方式連接值。但是,該列將按另一列中的值進行磁區/分組。
我已經能夠使用以下代碼從上到下執行此操作:
df['Col_to_cum_Concat']=[y.CUM_CONCAT_TOP.tolist()[:z 1] for x, y in df.groupby('Group_Col')for z in range(len(y))]
df['Col_to_cum_Concat'] = df['Col_to_cum_Concat'].astype(str).str.lower()
有沒有更簡單的方法可以從組內的最后一行到第一行?
例子:
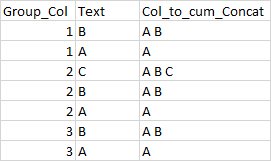
我已經嘗試了下面的代碼,但并不完全正常。
df['Col_to_cum_Concat']=[y.CUM_CONCAT_TOP.tolist()[z:] for x, y in df.groupby('Group_Col')for z in range(len(y))]
df['Col_to_cum_Concat'] = df['Col_to_cum_Concat'].astype(str).str.lower()
另外,如果這是一個愚蠢的問題,我提前道歉。我仍然是 Python 的新手。
uj5u.com熱心網友回復:
您可以按Group_Col和為每個組分組,反向Text并使用cumsum累積連接:
df['Col_to_cum_Concat'] = df.Text.groupby(df.Group_Col).transform(lambda g: g[::-1].add(' ').cumsum()).str.rstrip()
df
Group_Col Text Col_to_cum_Concat
0 1 B A B
1 1 A A
2 2 C A B C
3 2 B A B
4 2 A A
5 3 B A B
6 3 A A
資料:
df = pd.DataFrame({'Group_Col': [1,1,2,2,2,3,3], 'Text': ['B', 'A', 'C', 'B', 'A', 'B', 'A']})
轉載請註明出處,本文鏈接:https://www.uj5u.com/net/412440.html
標籤:
上一篇:使用首先處理的年份創建新變數