這是對該問題的第三次編輯(以防萬一,請留在下面的執行緒中):
以下代碼制作了一些示例資料框,選擇標題中帶有“_areaX”的資料框并列出它們。然后,目標是將串列中的資料框組合成 1 個資料框。它幾乎可以作業...
Area1 <- 100
Area2 <- 200
Area3 <- 300
Zone <- 3
a1_areaX <- data.frame(Area1)
a2_areaX <- data.frame(Area2)
a3_areaX <- data.frame(Area3)
a_zoneX <- data.frame(Zone)
library(dplyr)
pattern = "_areaX"
df_list <- mget(ls(envir = globalenv(), pattern = pattern))
big_data = bind_rows(df_list, .id = "FileName")
問題是新創建的資料框如下所示:
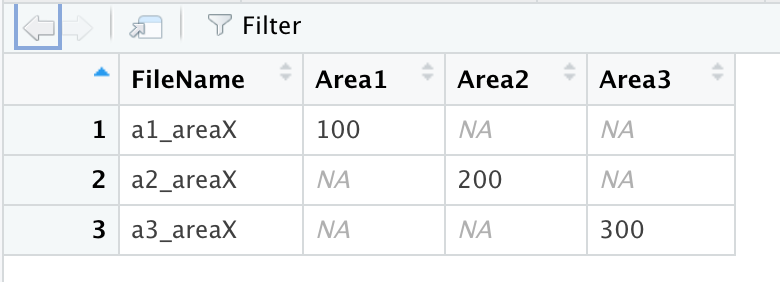
我需要它看起來像這樣:
| 檔案名 | 面積測量 |
|---|---|
| a1_areaX | 100 |
| a2_areaX | 200 |
| a3_areaX | 300 |
以下是我之前提出這個問題的嘗試。從第一個版本編輯:
我將 csv 檔案匯入到 R Global Env 中,看起來像這樣(我會分享實際檔案,但這里似乎沒有辦法做到這一點):
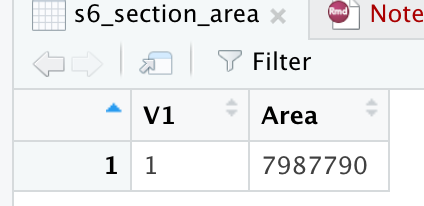
它們都有一個名字,上面那個叫做“s6_section_area”。其中有很多(具有不同的名稱),我使用以下代碼將它們全部放在一個串列中:
pattern = "section_area"
section_area_list <- list(mget(grep(pattern,ls(globalenv()), value = TRUE), globalenv()))
Now I want a new data frame that looks like this, put together from the data frames in the above made list.
| File Name | Area measurement |
|---|---|
| a1_section_area | a number |
| a2_section_area | another number |
| many more | more numbers |
So, the first column should list the name of the original file and the second column the measurement provided in that file.
Hope this is clearer - Not sure how else to provide reproducible example without sharing the actual files (which doesn't seem to be an option).
addition to edit: Using this code
section_area_data <- bind_rows(section_area_list, .id = "FileName")
I get (it goes on and on to the right)

I'm after a table that looks like the sample above, left column is file name with a list of file names going down. Right column is the measurement for that file name (taken from original file).
uj5u.com熱心網友回復:
請注意,在您的資料框串列 ( df_list) 中,所有列都有不同的名稱 ( Area1, Area2, Area3),而在您的輸出資料框中,它們都已合并為一列。因此,您需要將不同的列名稱更改為相同的名稱并將資料框系結在一起。
library(dplyr)
library(purrr)
result <- map_df(df_list, ~.x %>%
rename_with(~"Area", contains('Area')), .id = 'FileName')
result
# FileName Area
#1 a1_areaX 100
#2 a2_areaX 200
#3 a3_areaX 300
uj5u.com熱心網友回復:
謝謝大家的建議。最后,我能夠將這些建議和更多思考結合起來,并提出了這個,效果很好。
library("dplyr")
pattern = "section_area"
section_area_list <- mget(ls(envir = globalenv(), pattern = pattern))
section_area_data <- bind_rows(section_area_list, .id = "FileName") %>%
select(-V1)
因此,一堆 csv 檔案被匯入到 R Global Env 中。一個名稱以“section_area”結尾的所有檔案的串列。這些檔案被系結到一個大資料框中,檔案名作為一列,值(在這種情況下為面積測量)在另一列中(原始 csv 檔案中有一個無意義的列,稱為“V1”,我洗掉了它)。
這是許多 csv 檔案之一看起來像 示例 csv 檔案的內容
這是最終資料框的布局(大約 150 行) 最終資料框
轉載請註明出處,本文鏈接:https://www.uj5u.com/net/412443.html
標籤:
上一篇:將DataFrame表(面板資料?)轉換為時間序列的Python代碼?
下一篇:如何解開完全融化的桌子