我有一個我想從 WikiData 網站上抓取的 webid 串列。這里以兩個鏈接為例。
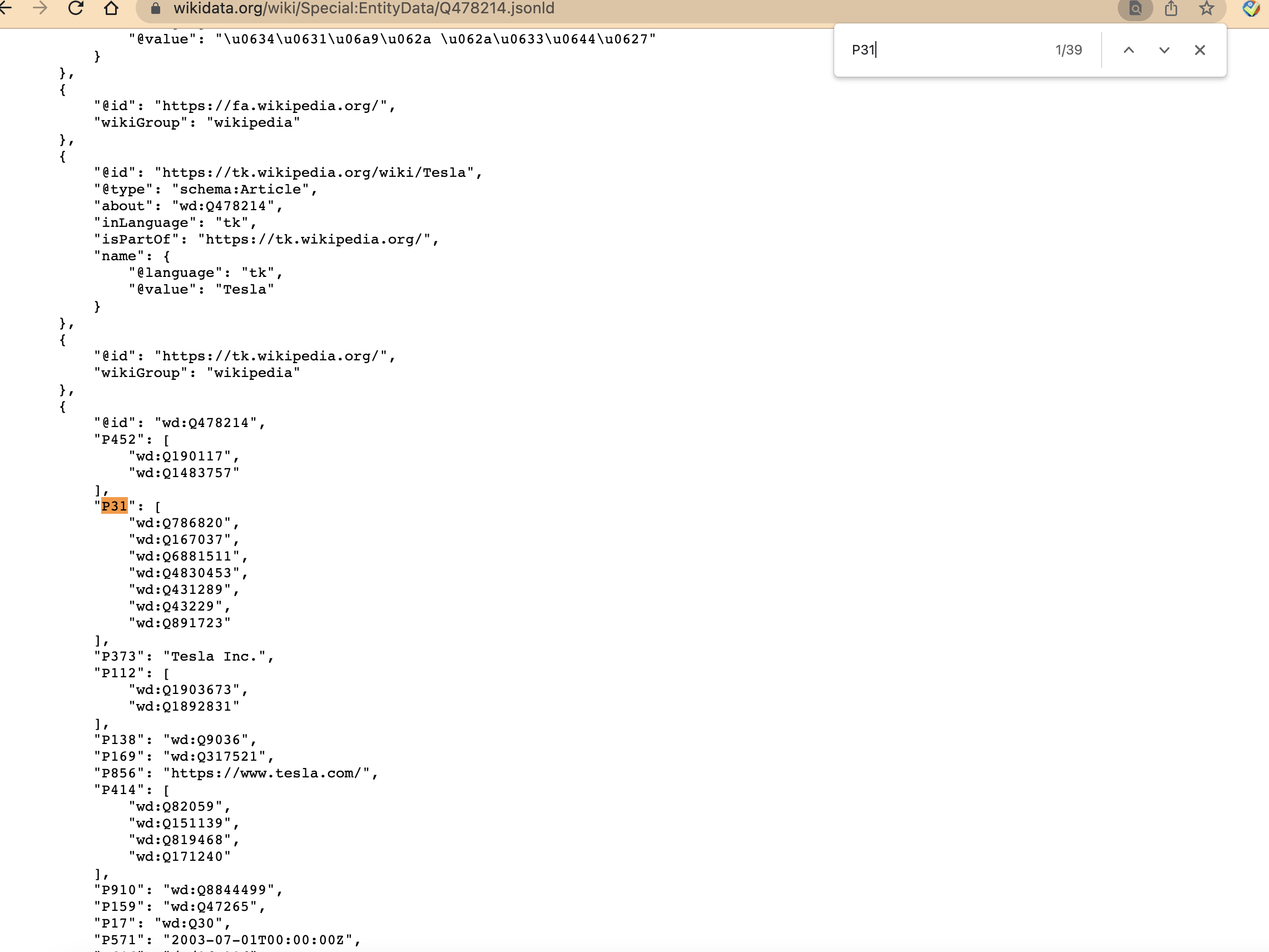 當我使用查找并輸入“P31”時,我只需要所有結果中的第一個結果。上圖說明了
當我使用查找并輸入“P31”時,我只需要所有結果中的第一個結果。上圖說明了
輸出將如下所示。
info = ['wd:Q5',
["wd:Q786820", "wd:Q167037", "wd:Q6881511","wd:Q4830453","wd:Q431289","wd:Q43229","wd:Q891723"],
]
lst = ["Q317521","Q478214"]
for q in range(len(lst)):
link =f'https://www.wikidata.org/wiki/Special:EntityData/{q}.jsonld'
page = requests.get(link)
soup = BeautifulSoup(page.text, 'html.parser')
在那之后,我不知道如何從第一組“P31”中提取資訊。我正在使用request, BeautifulSoup, and Selenium庫,但我想知道除了使用 XPath 或 Class 之外,還有什么更好的方法可以從 URL 中抓取/提取該資訊?
太感謝了!
uj5u.com熱心網友回復:
您只需要requests在收到 JSON 回應時。
您可以使用一個函式來回圈相關的 JSON 嵌套物件并在第一次出現目標鍵時退出,同時將關聯的值附加到您的串列中。
回圈變數應該是要添加到請求 url 中的 id。
import requests
lst = ["Q317521","Q478214"]
info = []
def get_first_p31(data):
for i in data['@graph']:
if 'P31' in i:
info.append(i['P31'])
break
with requests.Session() as s:
s.headers = {"User-Agent": "Safari/537.36"}
for q in lst:
link =f'https://www.wikidata.org/wiki/Special:EntityData/{q}.jsonld'
try:
r = s.get(link).json()
get_first_p31(r)
except:
print('failed with link: ', link)
轉載請註明出處,本文鏈接:https://www.uj5u.com/net/417501.html
標籤: