Elasticsearch使用系列-ES簡介和環境搭建
Elasticsearch使用系列-ES增刪查改基本操作+ik分詞
一、安裝可視化工具Kibana
ES是一個NoSql資料庫應用,和其他資料庫一樣,我們為了方便操作查看它,需要安裝一個可視化工具 Kibana,
官網:https://www.elastic.co/cn/downloads/kibana
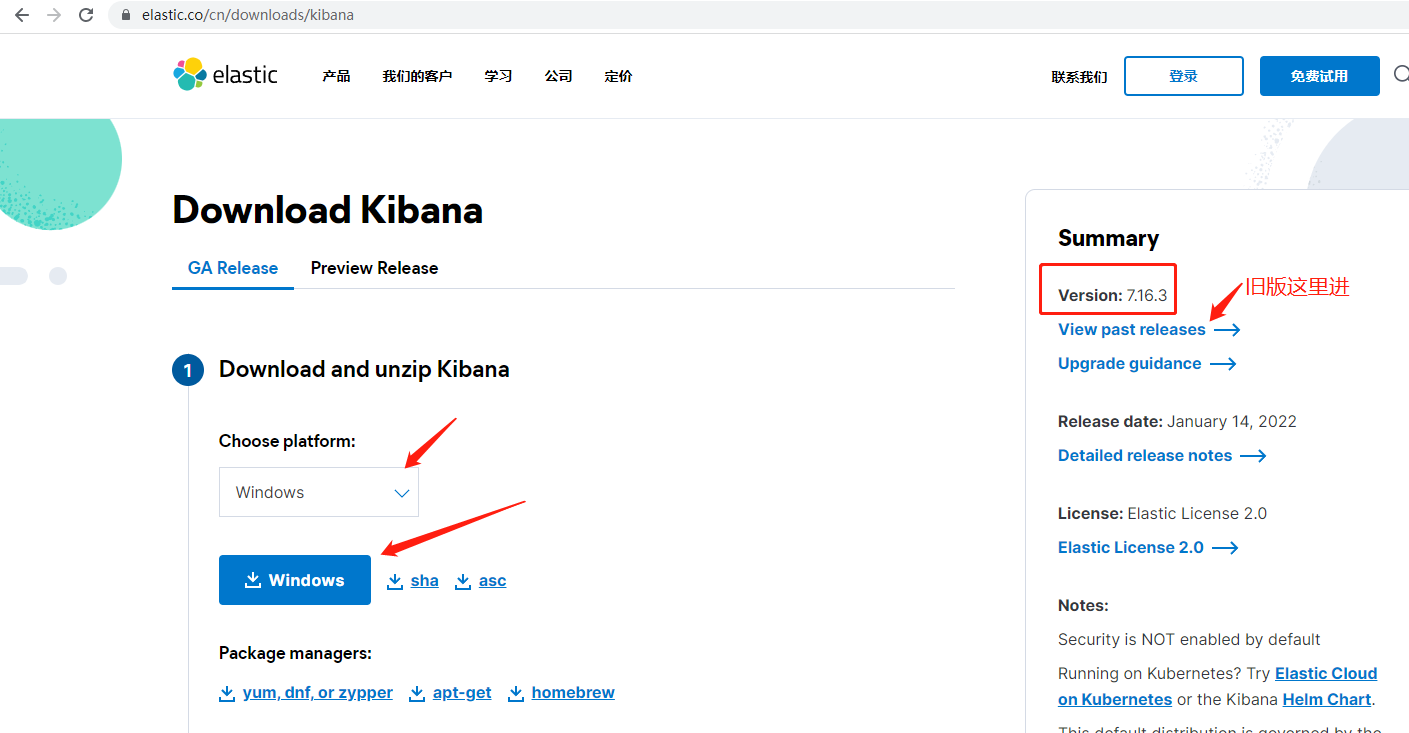
和前面安裝ES一樣,選中對應的環境下載,這里選擇windows環境,注意安裝的版本一定要和ES的版本一致,不然可能會啟動不起來,
解壓后進到config目錄下修改kibana.yml組態檔
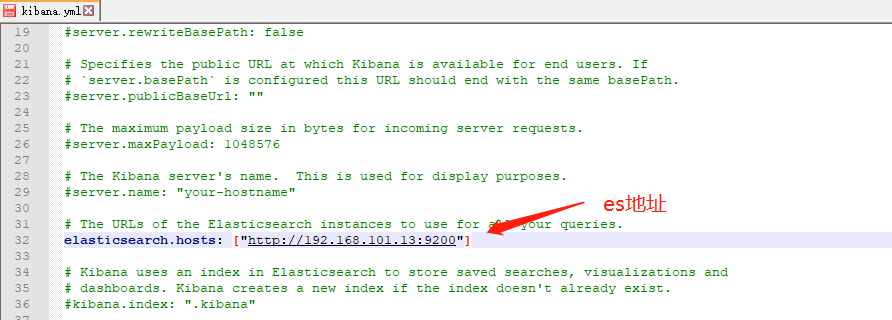
修改完配置,進入bin目錄,雙擊 kibana.bat 檔案啟動,
啟動后,打開kibana地址:http://localhost:5601/ ,出現下面界面就是安裝成功了,
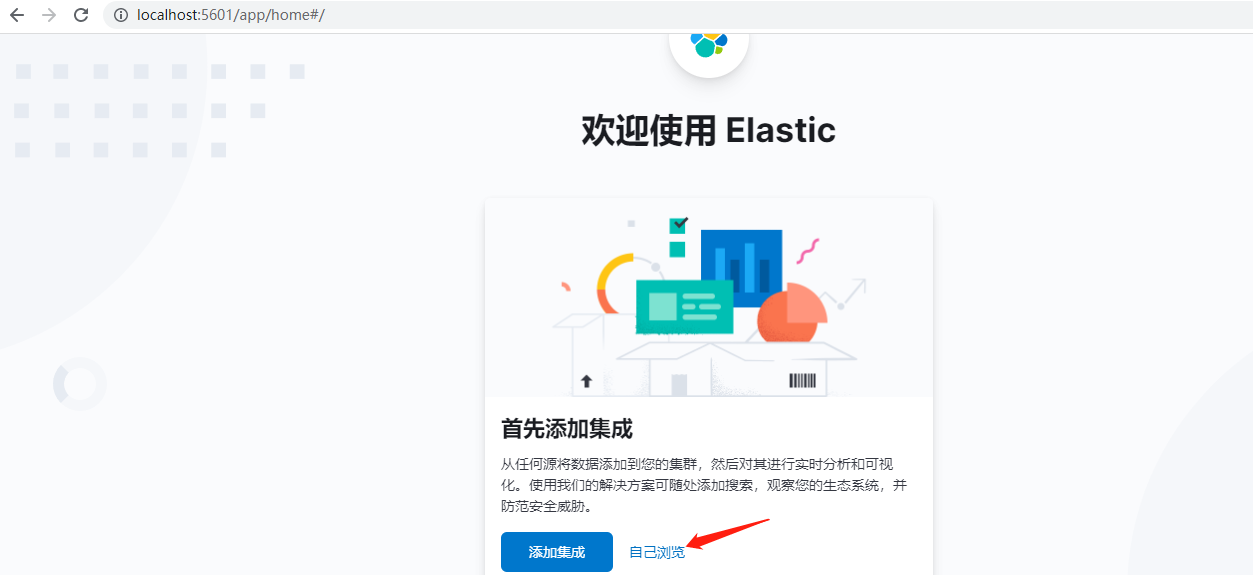
點自己瀏覽進入下面
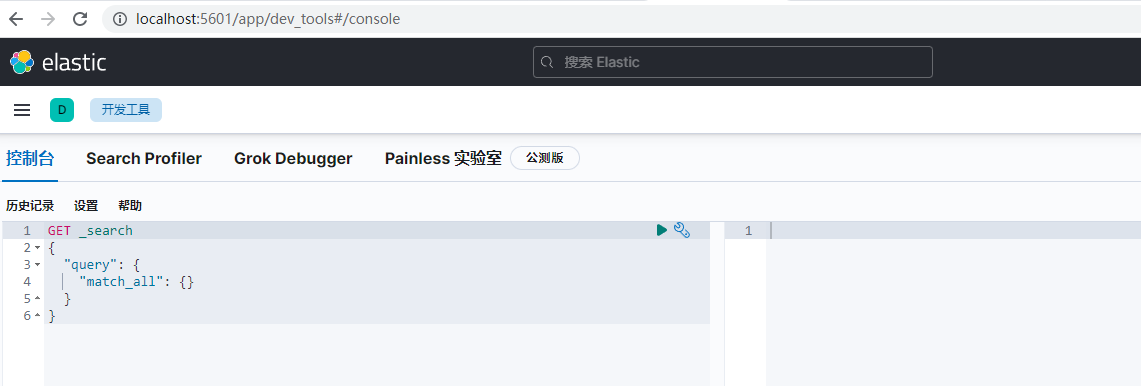
點開發工具進入操作ES的界面,我們ES就在下面界面操作,
二、ES資料結構和資料型別
1.ES資料結構
這里以Mysql作對比,ES7.0以前的結構是Index,Type,Document,ES7.0以后廢棄了Type,現在ES和Mysql的結構對比如下
| MySql | Elasitcsearch |
| database(資料庫) | Elasitcsearch(實體) |
| table(表) | index(索引) |
| row(行) | document(檔案) |
| column(列) | field(欄位) |
2.ES資料型別
- 字串:text,keyword (重點型別)
- 數值:long,integer,short,byte,double,float,half float,scaled float
- 日期型別:date
- 布爾型別:boolean
- 二進制型別:binary
- 等等,,,
這里的資料型別標紅的是ES的重點型別,其它的和平時開發的型別一樣,沒什么特別,
三、ES的增刪查改基本操作
| 請求方式 | url地址 | 描述 |
| PUT | http://localhost:9200/索引名稱 | 創建索引 |
| POST | http://local | |
1.創建索引,相當于資料庫創建表
PUT index


PUT user { "mappings" : { "properties" : { "age" : { "type" : "integer" }, "name" : { "type" : "text" }, "name2" : { "type" : "keyword" }, "name3" : { "type" : "text", "fields" : { "keyword" : { "type" : "keyword", "ignore_above" : 256 } } }, "hobby" : { "type" : "text" } } } }View Code
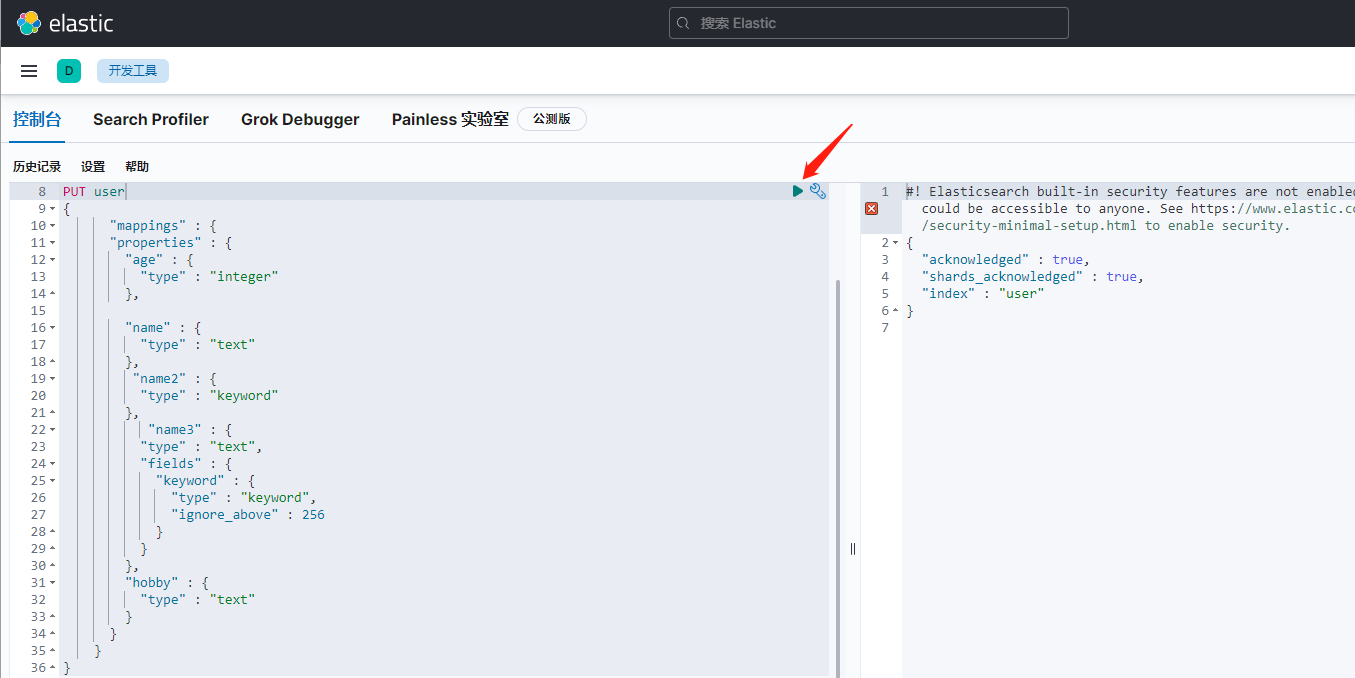
這里說一下kibana執行的原理,kibana執行的是http請求,前面的PUT為請求方式,還有POST,GET等,后面的user是索引名稱,因為kibana配置了es的資訊,
所以會自動帶上es的地址和埠,實際的請求為 PUT http://192.168.101.13:9200/user
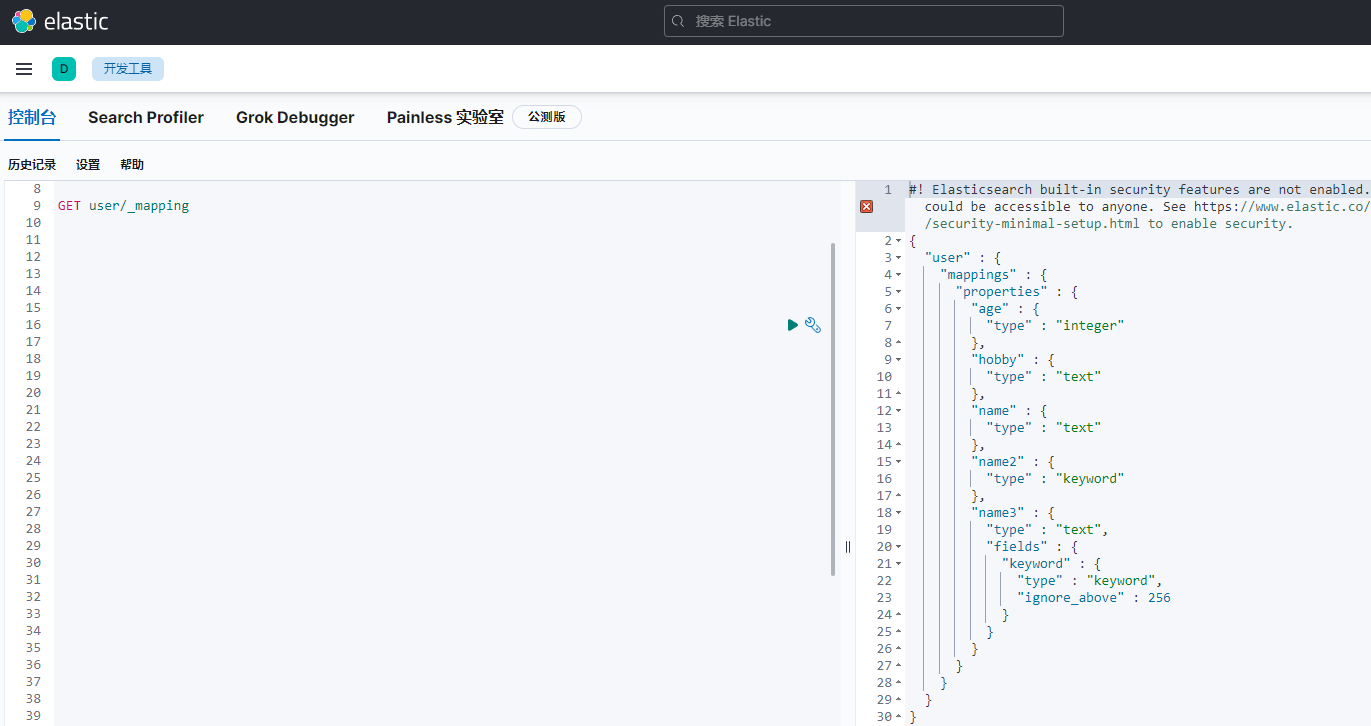
查看索引欄位資訊
GET index
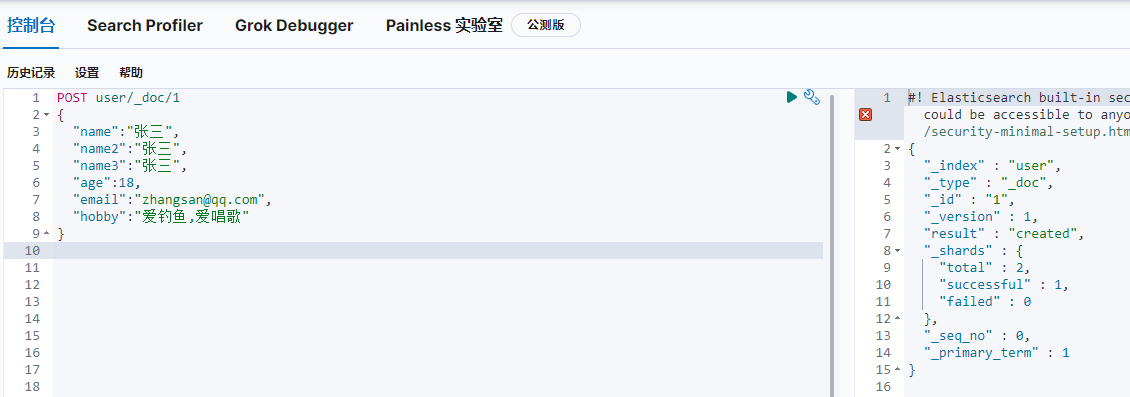
2.創建檔案,相當于資料庫插入資料記錄
POST index/_doc/id (index:索引名稱,_doc:固定,id:指定記錄id,不填會自動生成一個唯一id)
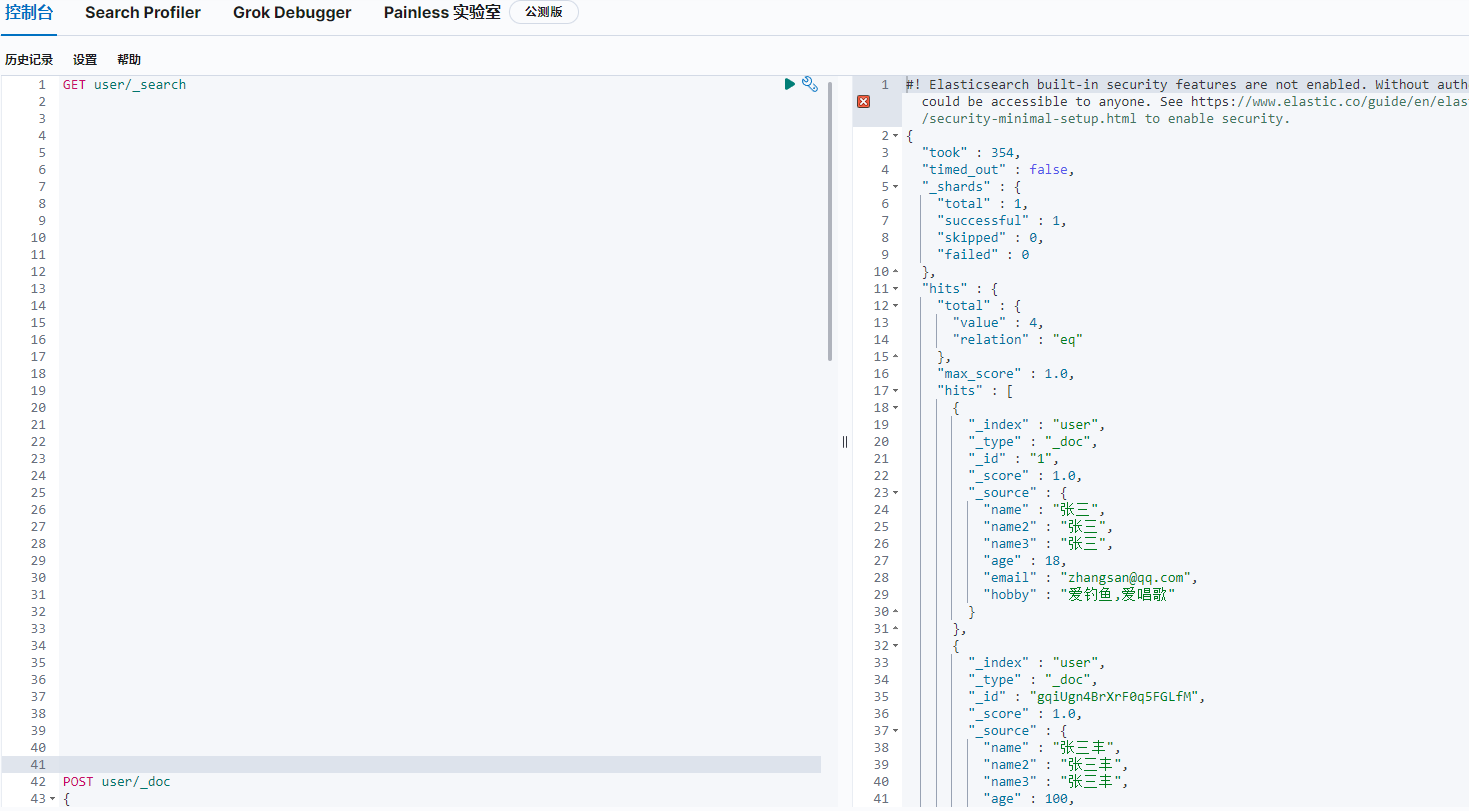
4.查詢
4.1查詢全部
GET index/_search
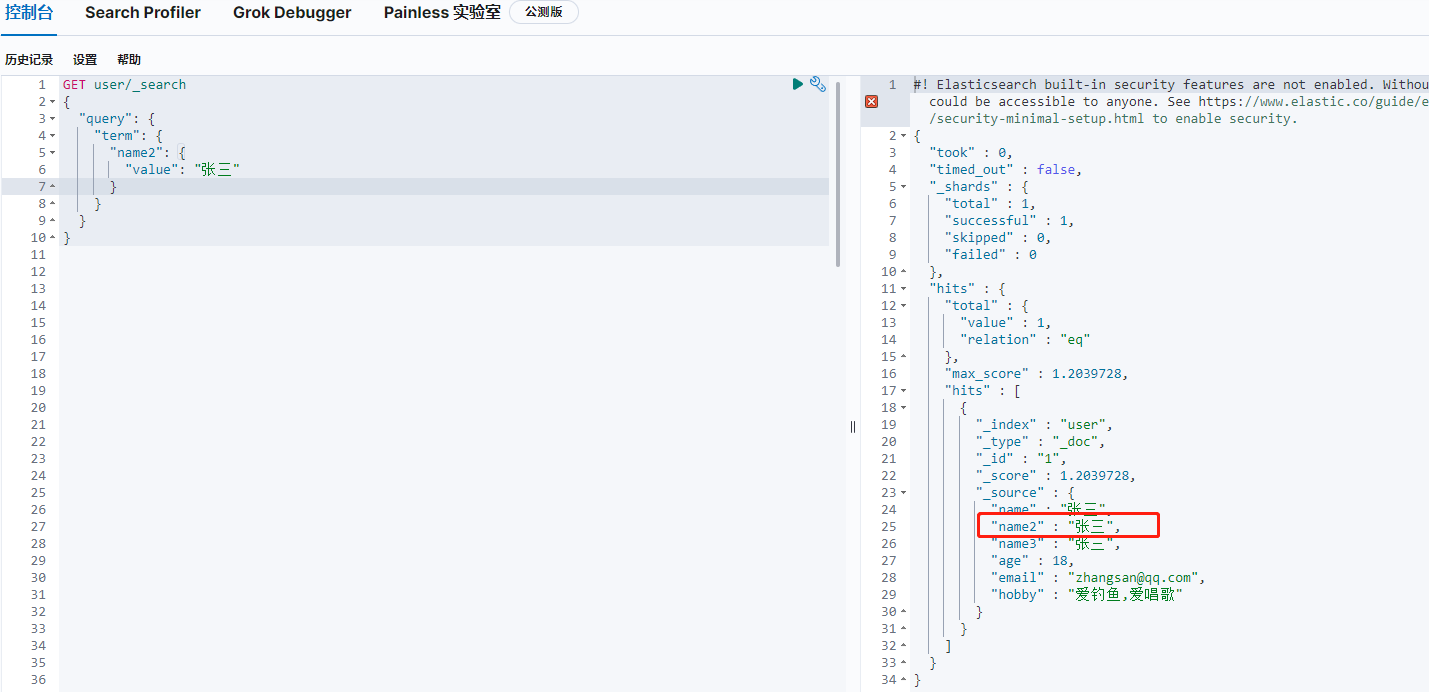
4.2按條件查詢
GET user/_search { "query": { "term": { "FIELD": { "value": "VALUE" } } } }
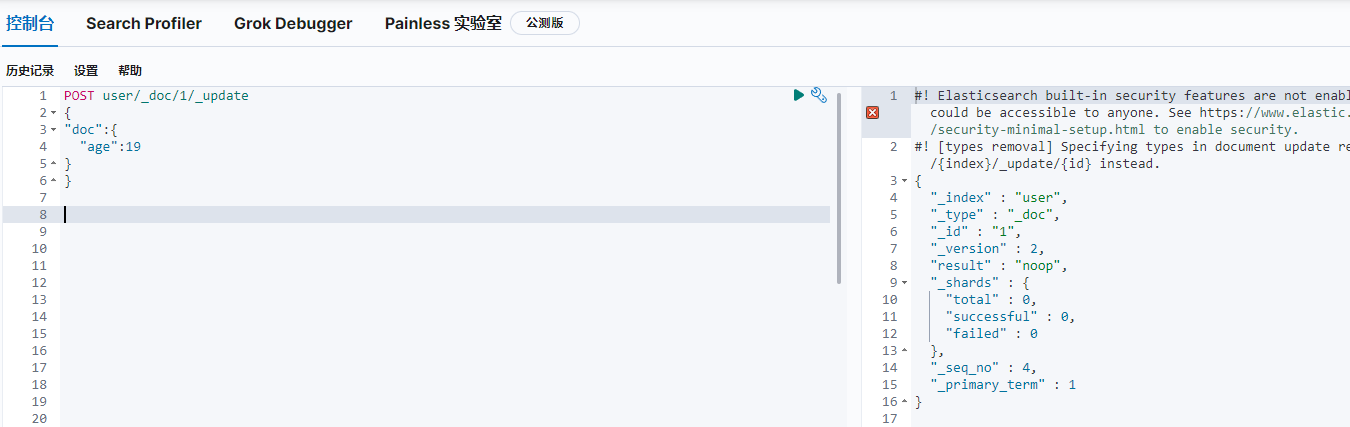
5.更新
對應sql陳述句:update user set age=19 where id=1
_doc,doc,_update:固定寫法
6.洗掉
6.1洗掉檔案(相當于洗掉一條資料)
對應sql陳述句: delete from user where id=1
DELETE user/_doc/1
6.2洗掉索引(相當于洗掉表)
對應sql陳述句:drop table user
DELETE user
四、全文索引和ik分詞
1.全文索引
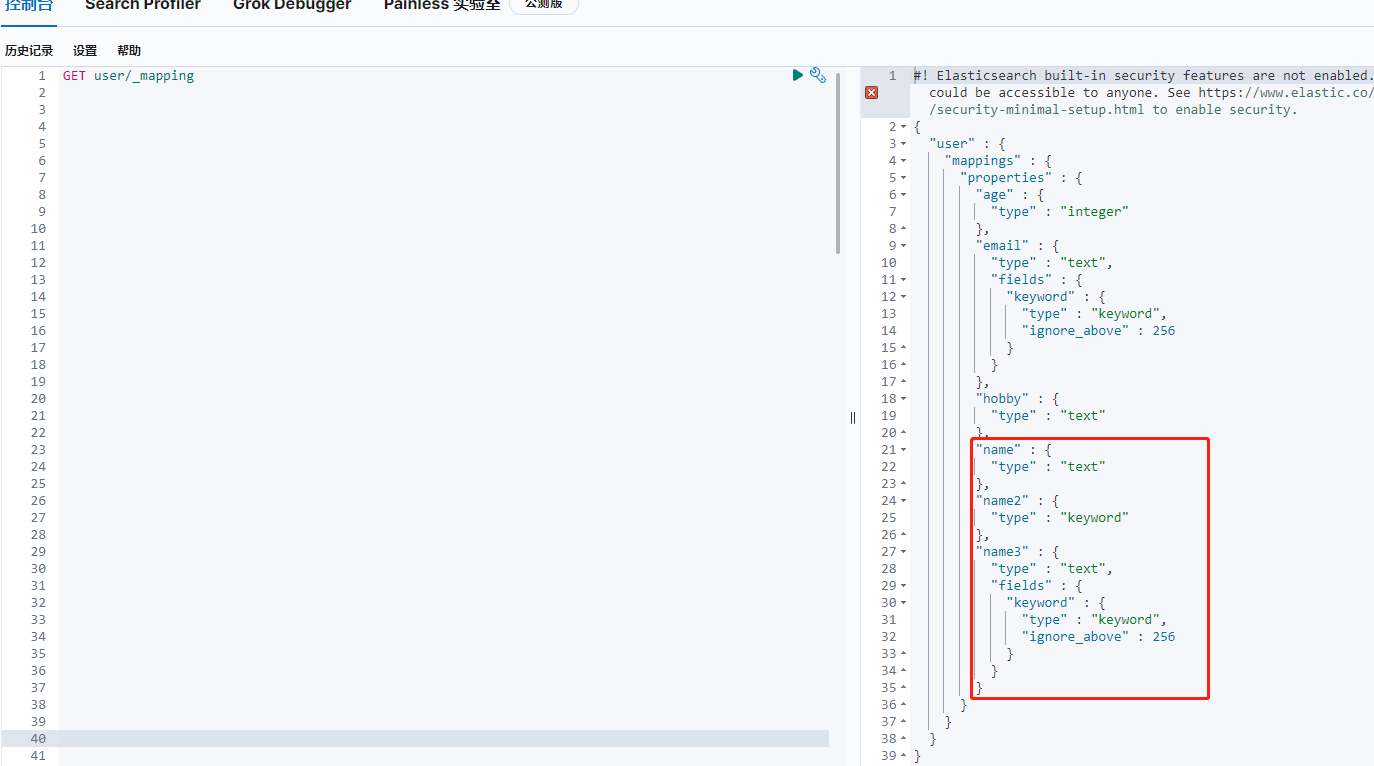
創建索引的時候我上面故意創建了name(text),name1(keyword),name2(text+keyword),然后資料型別也說了text,keyword是ES的重點型別,這里演示他們的區別,
- keyword型別:查詢時條件只能全匹配
- text型別:全文索引查詢,查詢時會先分詞,然后用分詞去匹配查詢
- keyword+text型別,一個欄位兩種型別,可以全匹配,也可以全文索引查詢
keyword查詢例子,name2(keyword)的查詢:
keyword的查詢用term,或terms(配置多個值)
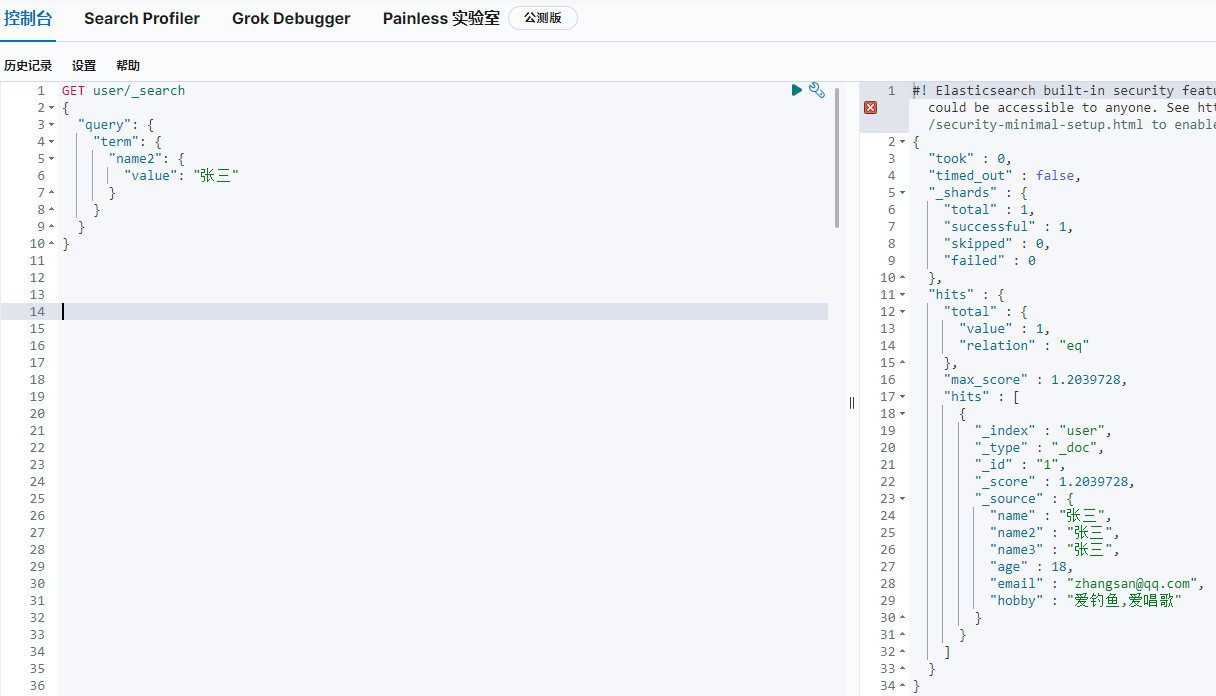
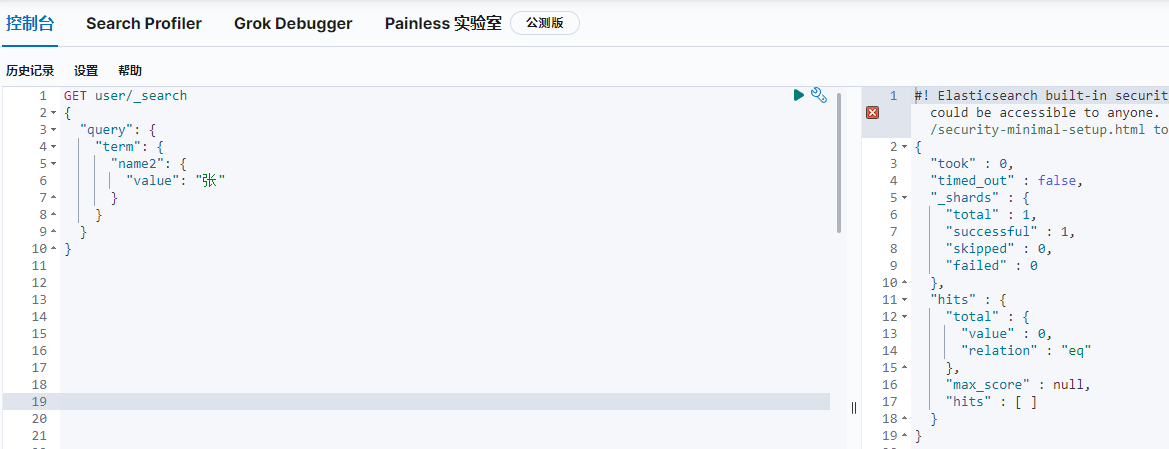
因為是全匹配,條件”張三“查到資料,條件”張“時查不到資料,
text查詢例子,name(text)的查詢
text的查詢用match
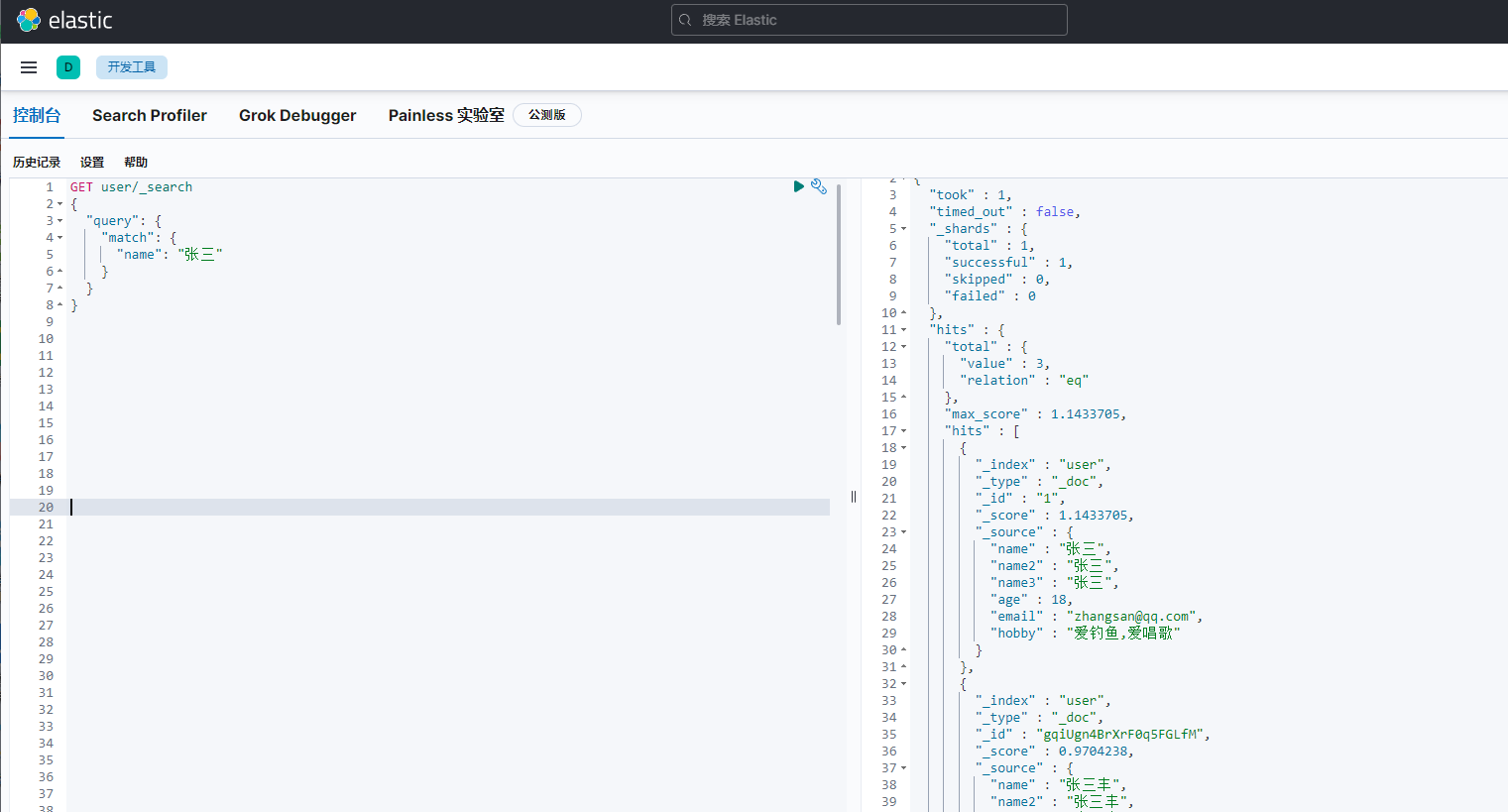
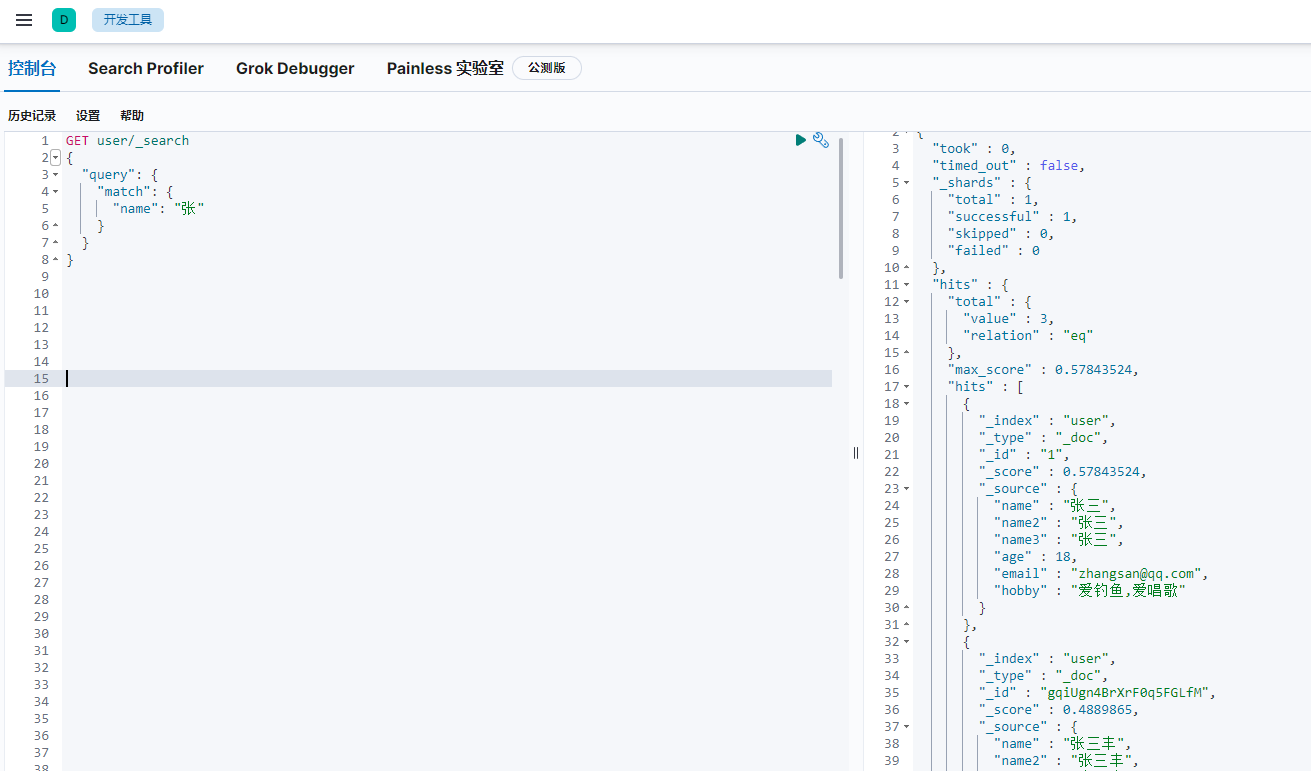
因為是全文索引分詞匹配,所以條件“張三”和條件“張”的,都把匹配到的資料都查詢出來了,
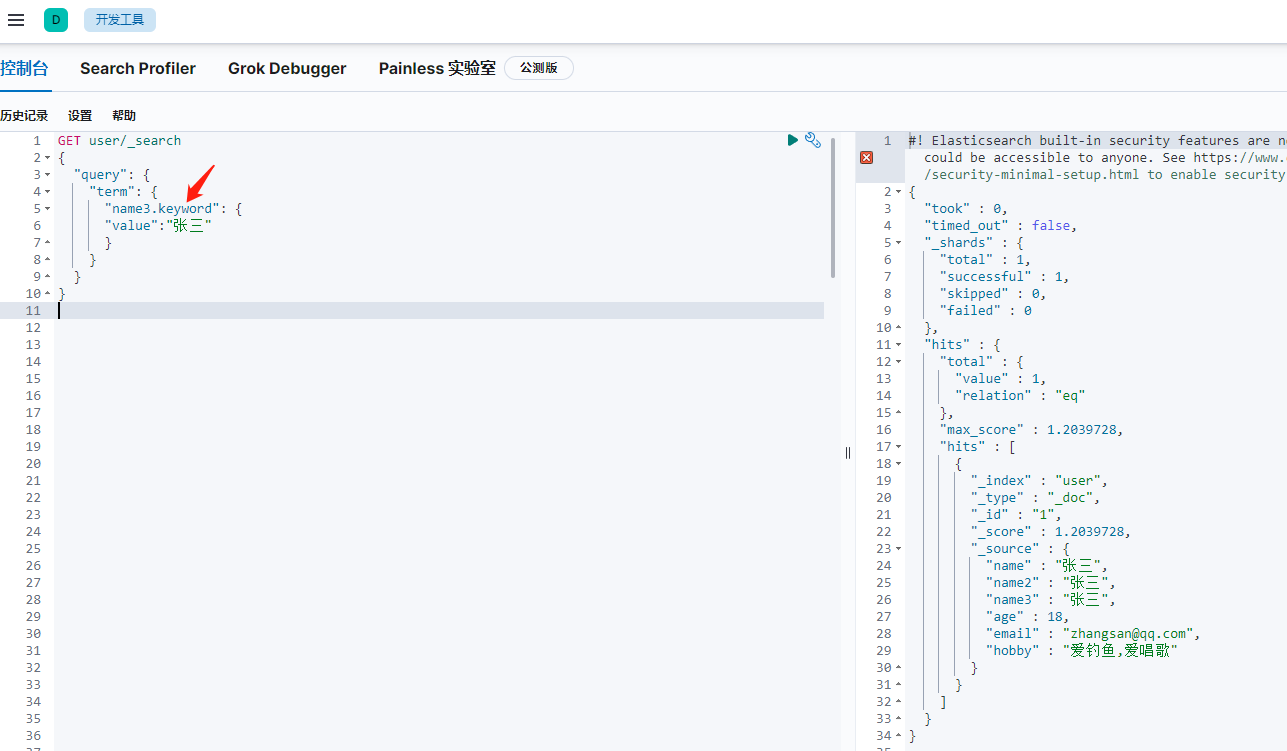
keyword+text查詢例子,name3(text+keyword)的查詢,
當只想查全匹配時,用term查詢
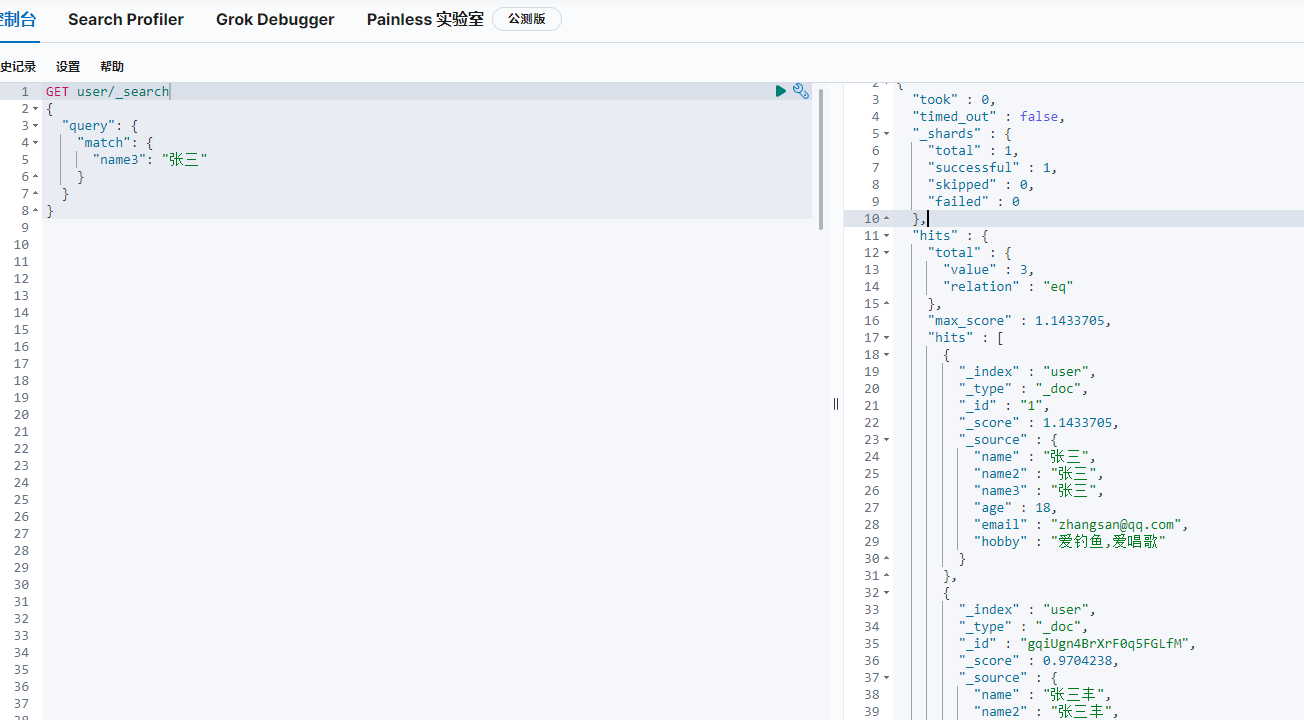
當想用全文索引查詢時,用match
2.ik分詞
1.什么是分詞?
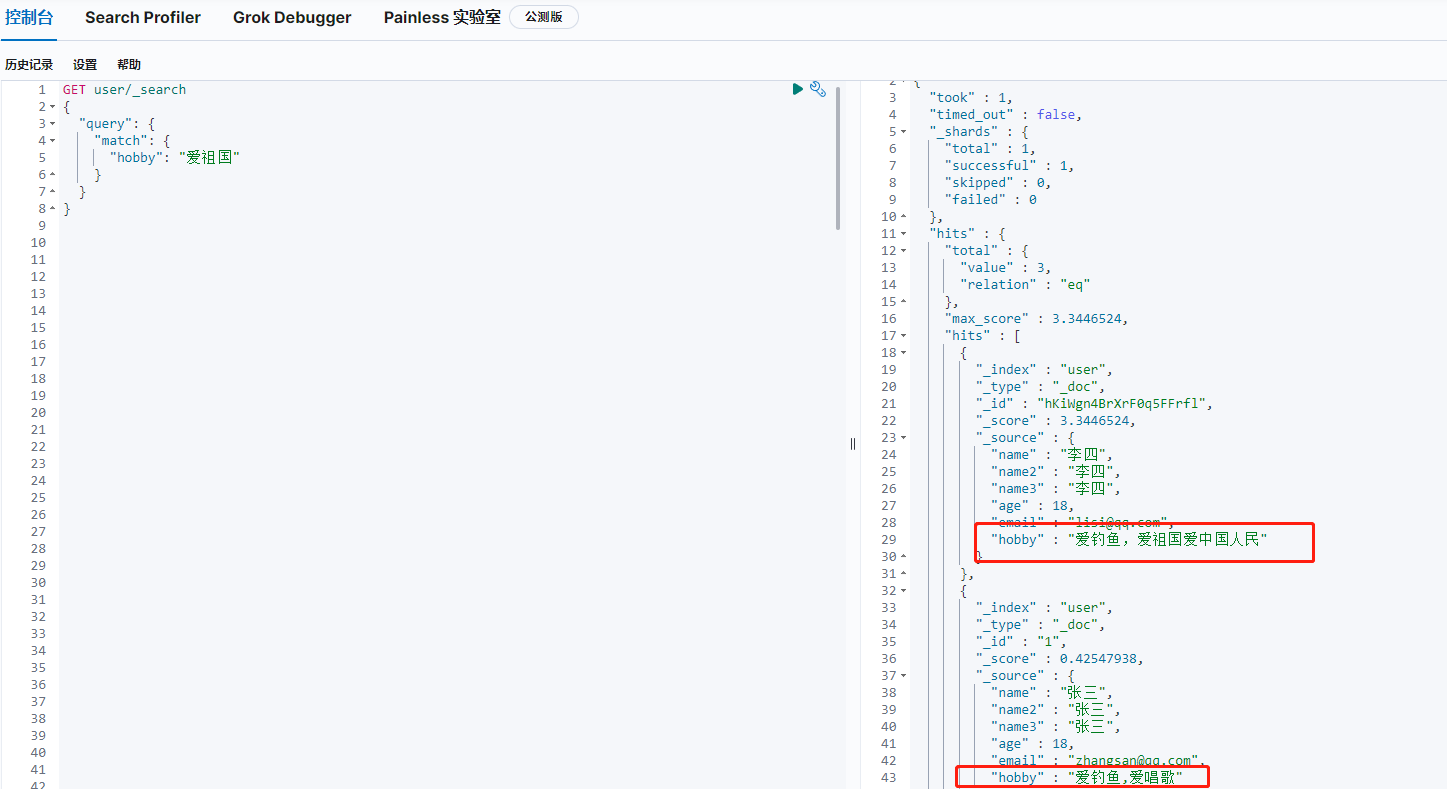
我搜的是愛祖國,為什么,“愛釣魚,愛唱歌"的都被搜出來了呢?
因為ES默認內置了一個分詞器standard,看下這個分詞器的分詞結果
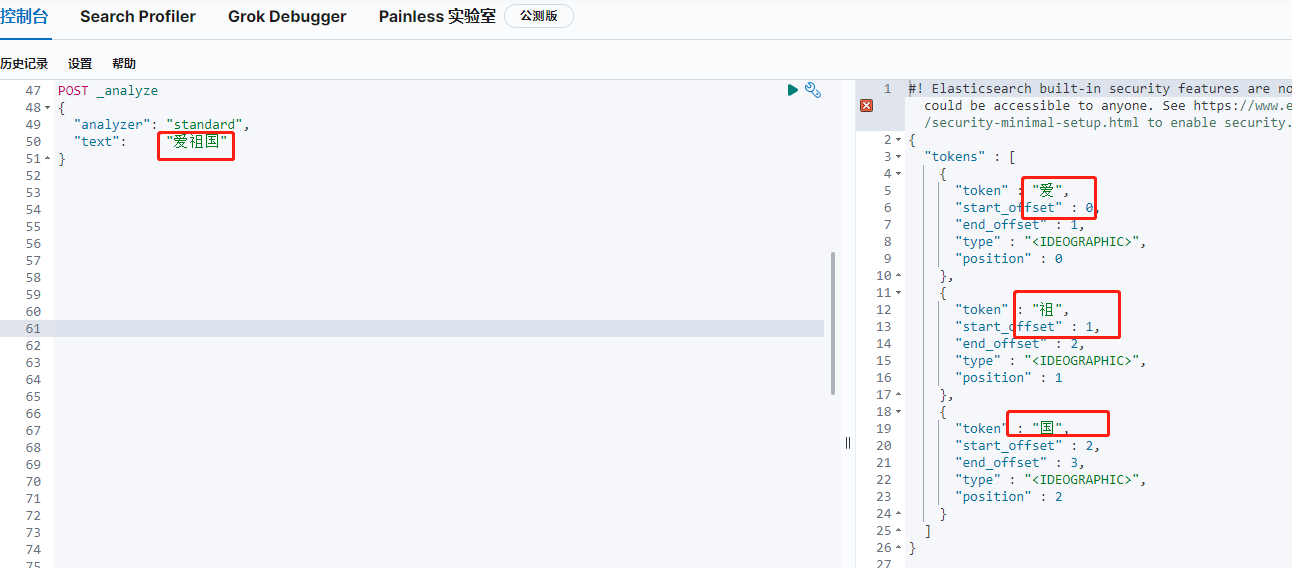
可以看到“愛祖國”的分詞結果為“愛,祖,國”,被拆分成了單個字,只要一個字匹配到就查出來,這樣的結果很多不是我們想要的,我們需要一款根據常用詞語的分詞器,這樣查到的結果會更準確,
這里就用到了ik分詞,ik分詞也是企業開發用的最多的,
2.ik分詞器插件安裝
官網下載:https://github.com/medcl/elasticsearch-analysis-ik/releases
下載的版本要和es一致,
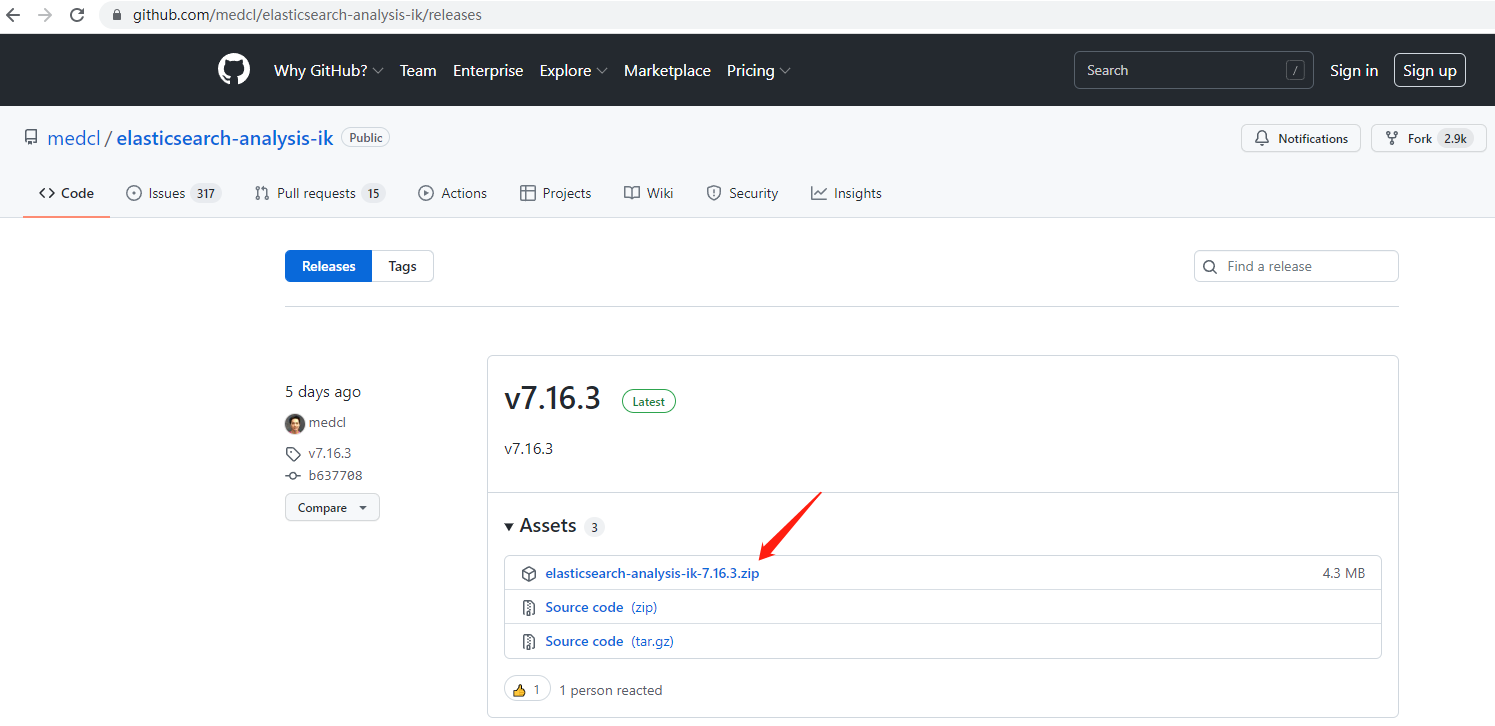
把檔案下載后,解壓復制到es部署檔案的plugins檔案夾下,并把檔案夾的名稱改為ik,必須要叫ik,windows,linux,docker(docker為掛載檔案夾的方式把檔案映射進去)一樣,
然后重啟es即可生效,
再看一下用ik分詞器的分詞結果,
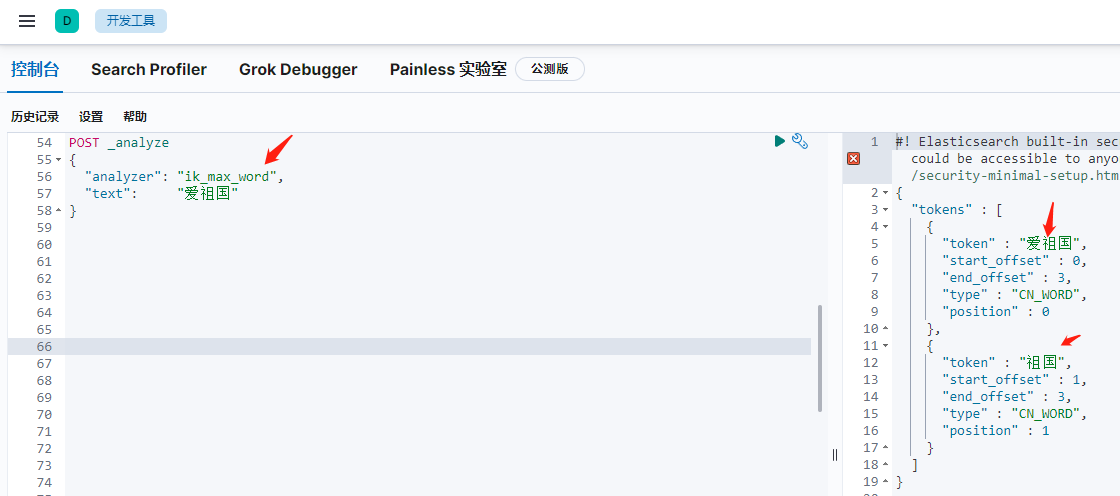
可以看到,已經是按常用詞語分詞了,
3.自定義詞組
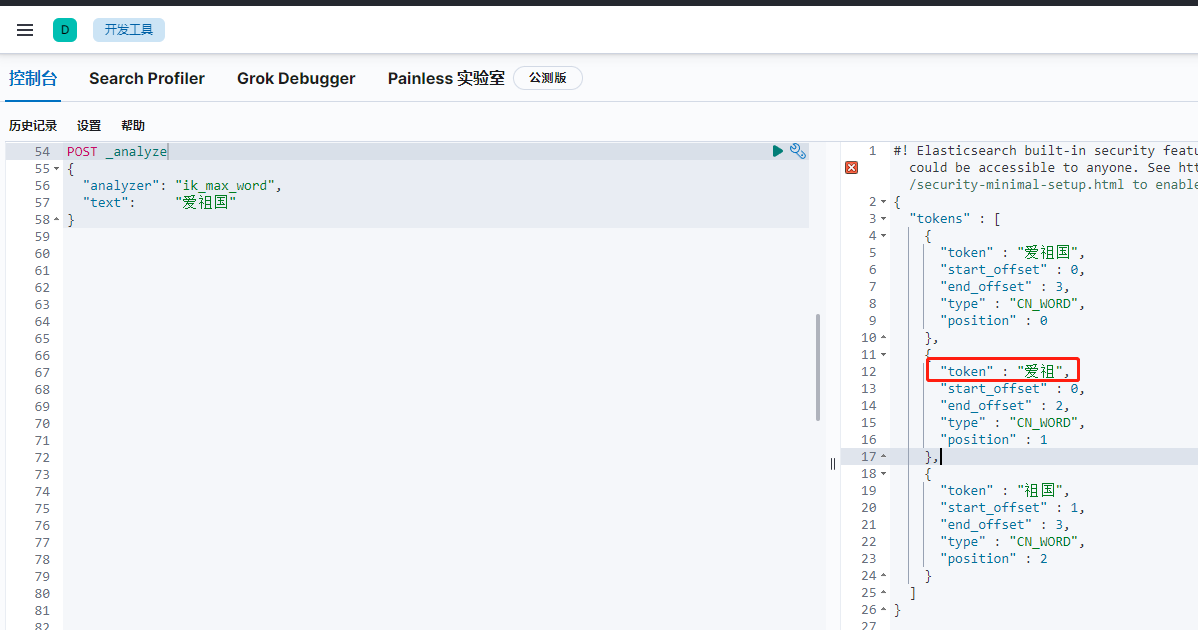
上面“愛祖國”,被分成“愛祖國,祖國”,假如我想“愛組”也是一個詞,現在這個詞沒被收怎么辦?
打開剛才的ik檔案夾下的config目錄
里面的.dic結尾的都是分詞,打開其中一個看一下,
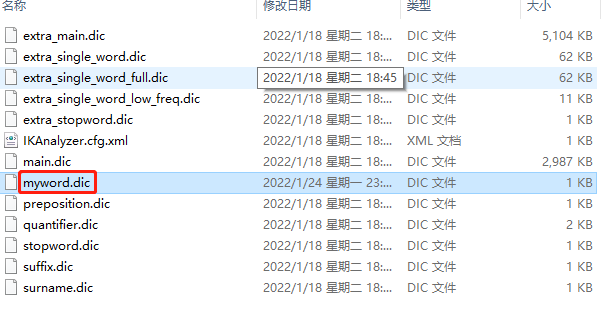
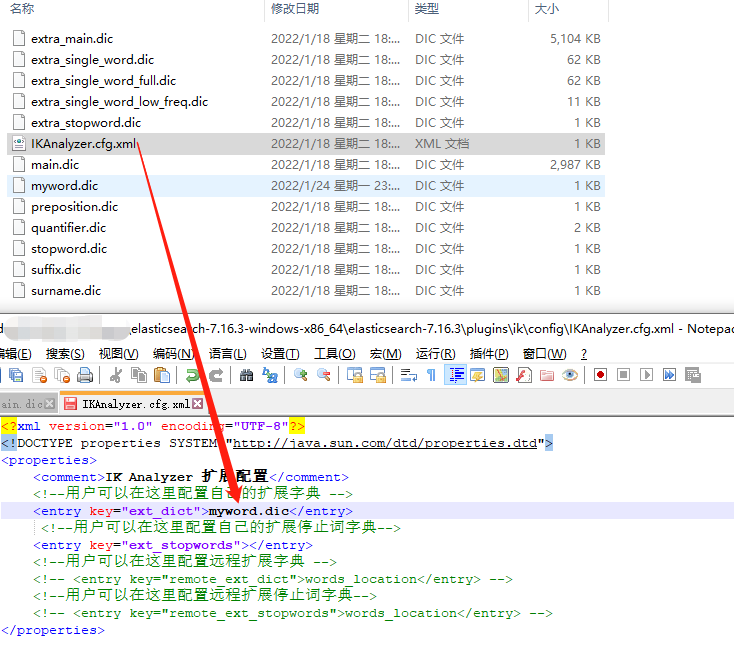
所以我們要自定義詞語,可以新建一個myword.dic
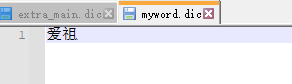
里面寫上想要的分詞
然后在IKAnalyzer.cfg.xml檔案加上剛才的檔案名
重啟es,再看一下分詞結果,
4.ik分詞怎么在索引中使用
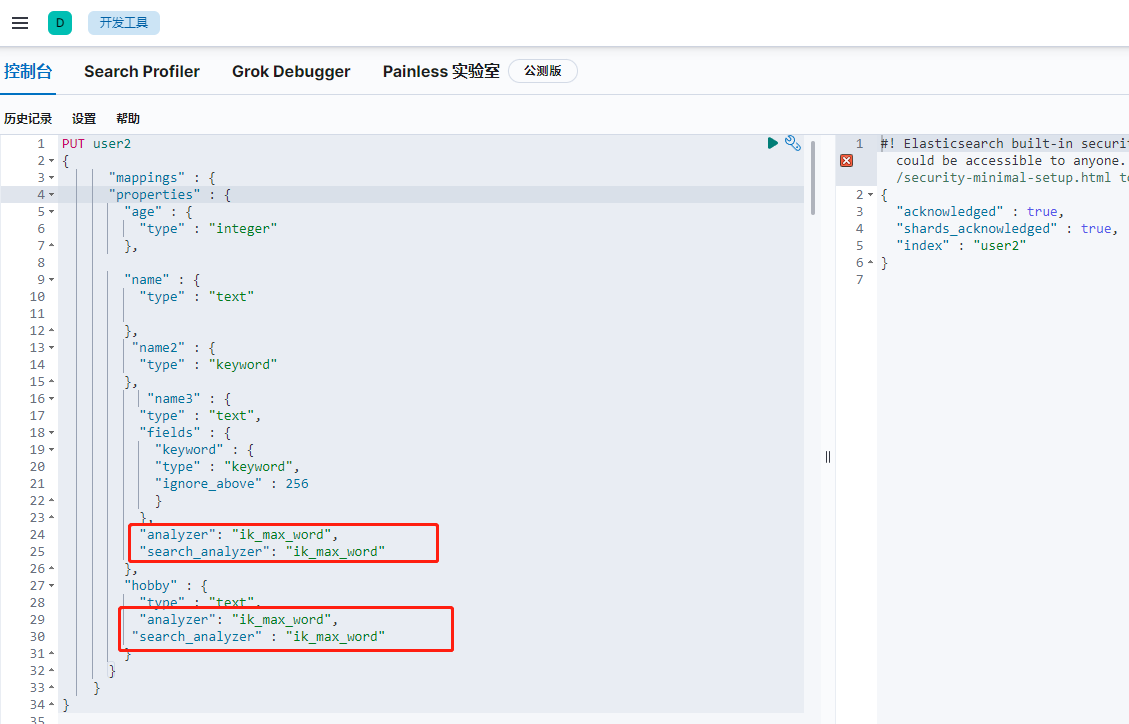
創建索引的時候,text型別如果沒指定使用分詞器,就會默認內置的分詞器,所以使用ik分詞器時,創建索引時需要指定,
PUT user2 { "mappings" : { "properties" : { "age" : { "type" : "integer" }, "name" : { "type" : "text" }, "name2" : { "type" : "keyword" }, "name3" : { "type" : "text", "fields" : { "keyword" : { "type" : "keyword", "ignore_above" : 256 } }, "analyzer": "ik_max_word", "search_analyzer": "ik_max_word" }, "hobby" : { "type" : "text", "analyzer": "ik_max_word", "search_analyzer" : "ik_max_word" } } } }View Code
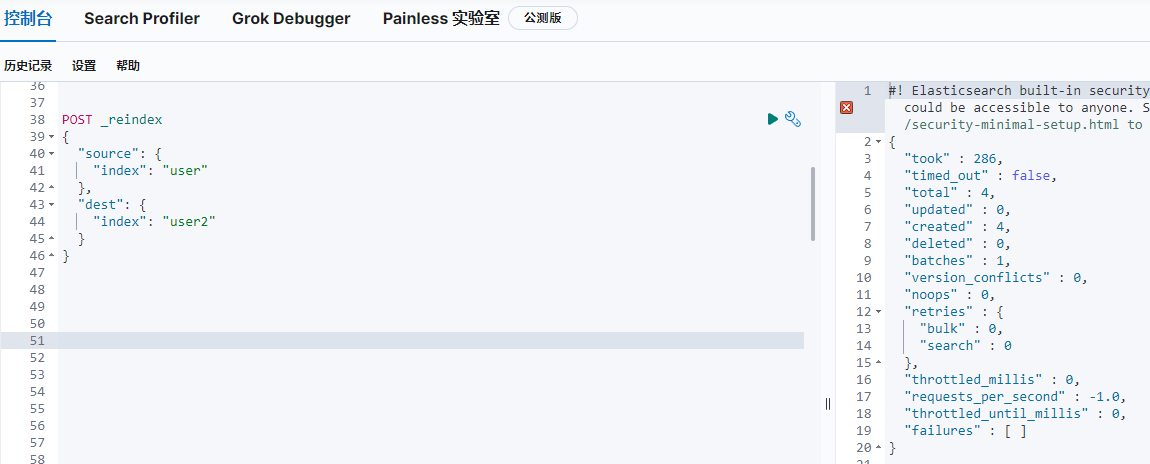
把user的資料復制到user2,
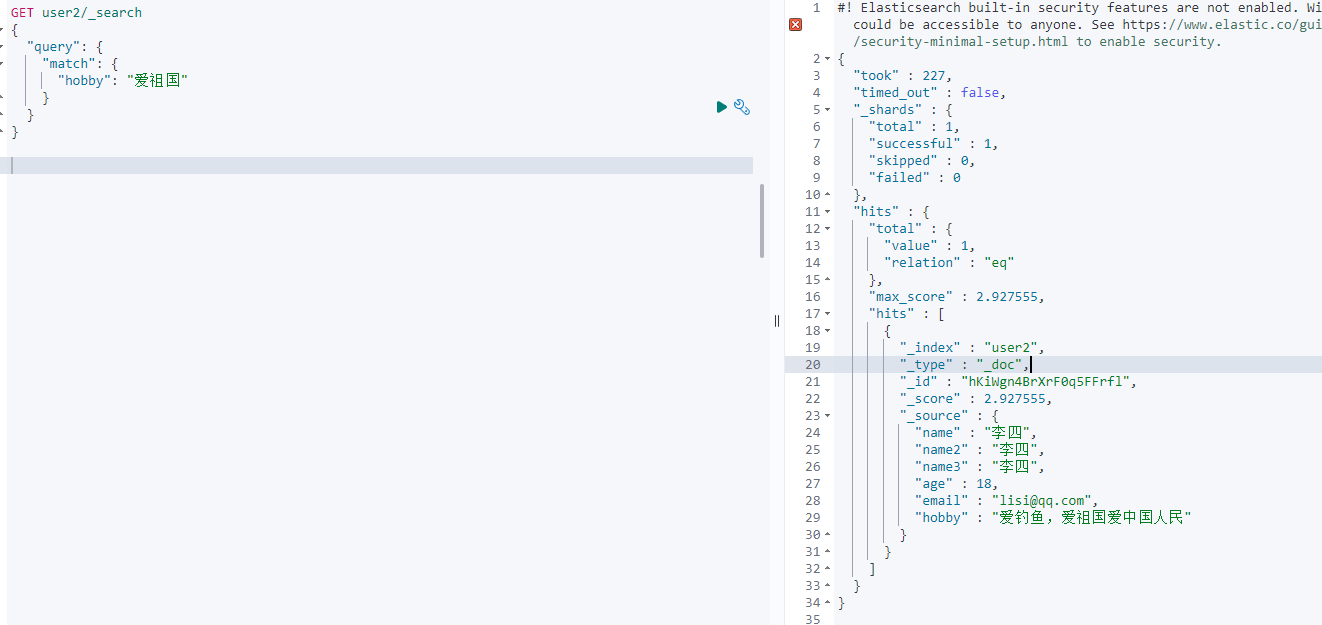
再次查詢“愛祖國”,得到一條想要的資料,沒有多余資料,證明ik分詞在索引中生效了,
轉載請註明出處,本文鏈接:https://www.uj5u.com/net/421261.html
標籤:.NET Core