我正在使用 pyspark==2.3.1。我已經使用 pandas 對資料進行了資料預處理,現在我想將我的預處理函式從 pandas 轉換為 pyspark。但是,在使用 pyspark 讀取資料 CSV 檔案時,許多值變成了實際上具有某些值的列的空值。如果我嘗試對此資料框執行任何操作,那么它會將列的值與其他列交換。我還嘗試了不同版本的 pyspark。請讓我知道我做錯了什么。謝謝
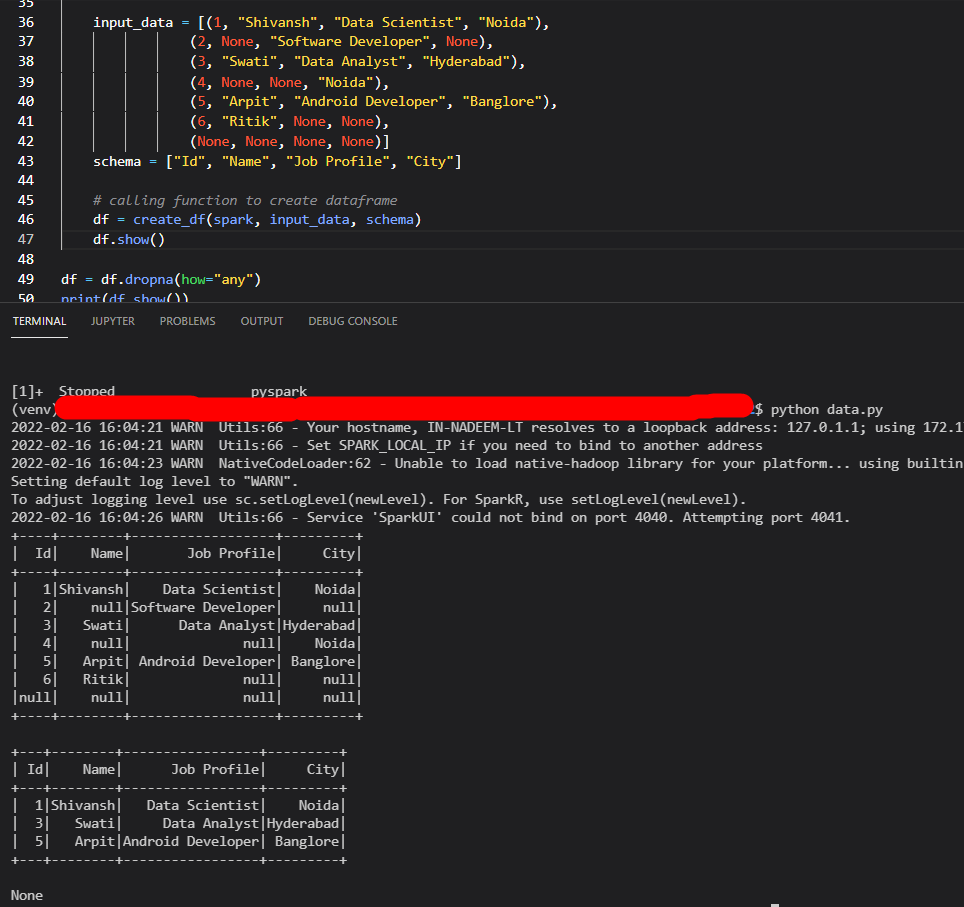
來自 pyspark 的結果:

“property_type”列的值為 null,但實際資料框有一些值而不是 null。
CSV 檔案:
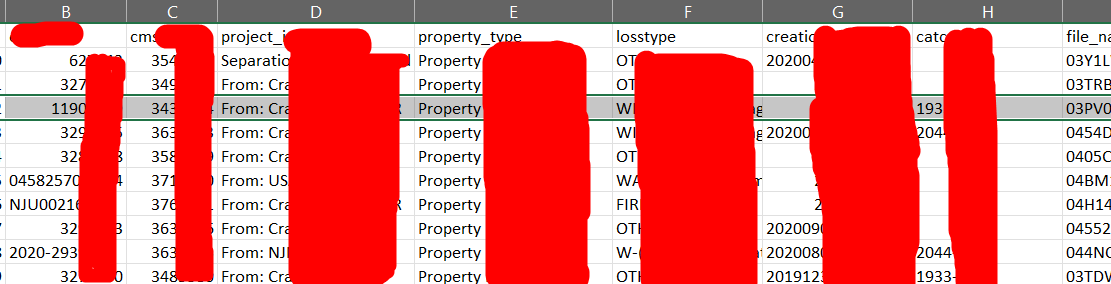
但是 pyspark 在小型資料集上運行良好。IE
uj5u.com熱心網友回復:
在我們中,我們遇到了類似的問題。您需要檢查的事項
- 檢查您的資料是否為“ [雙引號] pypark 會將其視為分隔符,并且資料看起來格式不正確
- 檢查您的 csv 資料是否為多行我們通過提及以下配置來處理這種情況
spark.read.options(header=True, inferSchema=True, escape='"').option("multiline",'true').csv(schema_file_location)
uj5u.com熱心網友回復:
您是否僅限于使用 CSV 檔案格式?試試鑲木地板。只需將 DataFrame 保存在 pandas 中,.to_parquet()而不是.to_csv(). Spark 非常適合這種格式。
轉載請註明出處,本文鏈接:https://www.uj5u.com/net/429927.html