我有一個如下所示的資料框
SHEET SUBJECT Listings for 2010 hi bla bla,,,,,,
order_number,,,,,,
Date,cust,region,Abr,Number,
12/01/2010,Company_Name,Somecity,Chi,36,
12/02/2010,Company_Name,Someothercity,Nyc,156,
df = pd.read_clipboard(sep=',')
從上面的資料框中,您可以看到第一兩行 ( narrative text) 只是描述,但標題/列名稱從第一行索引開始
所以,我嘗試了以下
df.columns = df.iloc[1] #assign actual column headers
df.drop(index=[0,1], inplace = True) #drop the actual column header row and also narrative text line from dataframe
# do some manipulation of data below (thanks to jezrael for the below code)
writer = pd.ExcelWriter('duck_data.xlsx',engine='xlsxwriter')
for (cust,reg), v in df.groupby(['cust','region']):
v.to_excel(writer, sheet_name=f"DATA_{cust}_{reg}",index=False)
writer.save()
以上僅在只有標題時才能正常作業,問題是無法保留敘述文本(例如:在我SHEET SUBJECT Listings for 2010 hi bla bla的order_number,,,,,,輸出 excel 檔案中(duck_data.xlsx)
如何在duck_data.xlsx(輸出檔案)的每個作業表中保留這兩個敘述性文本并存盤excel檔案第3個單元格的列標題?
我希望我的輸出如下所示。您可以看到輸出 excel 檔案的兩個作業表中的資料不同,但我保留了所有輸出 excel 檔案作業表的敘述文本和標題。
是否有根據生成的作業表數量將此文本復制到每張作業表?在每張紙中保留這些文本的任何其他方法/想法?
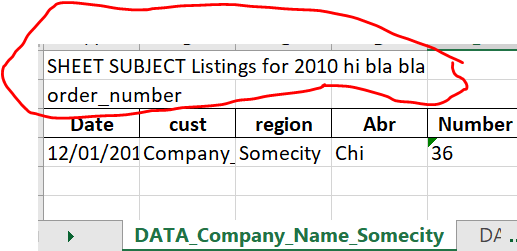

uj5u.com熱心網友回復:
采用:
#add text to variable from first column in original DataFrame
text = df.columns[0]
#add order no to variable by first value of first column
order_no = df.iloc[0,0]
df.columns = df.iloc[1] #assign actual column headers
df.drop(index=[0,1], inplace = True)
writer = pd.ExcelWriter('duck_data.xlsx',engine='xlsxwriter')
for (cust,reg), v in df.groupby(['cust','region']):
#strating row for write data is 2 (changed default 0)
v.to_excel(writer, sheet_name=f"DATA_{cust}_{reg}", index=False, startrow = 2)
workbook = writer.book
worksheet = writer.sheets[f"DATA_{cust}_{reg}"]
#to first cell in excel write text variable
worksheet.write(0, 0, text)
worksheet.write(1, 0, order_no)
writer.save()
轉載請註明出處,本文鏈接:https://www.uj5u.com/net/435752.html
標籤:Python 熊猫 数据框 打开pyxl 熊猫.excelwriter
上一篇:如何獲得輸入格式的隨機相似整數?