我想爬取一個網站,但我在回圈低谷頁面時遇到問題。我想創建一個收集所有鏈接的系統,然后單擊每個鏈接并收集資料(在這種情況下為日期)。我寫了一個代碼,但我不斷收到這個錯誤:
StaleElementReferenceException: Message: stale element reference: element is not attached to the page document
(Session info: chrome=98.0.4758.109)
我試圖增加睡眠間隔,但結果是一樣的。該錯誤發生在第二次迭代之后(在第一個鏈接之后)。
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import requests
import time
# url for crawling
url = "https://bstger.weblaw.ch/?size=n_60_n"
# path to selenium
path = 'path to selenium'
driver = webdriver.Chrome(path)
driver.get(url)
time.sleep(4)
# click on search button
buttonClickSearch = driver.find_element_by_xpath('//*[@id="root"]/div/div/div[2]/div[1]/div/div[3]/form/div/input').click()
time.sleep(3)
# get all links
all_links = driver.find_elements_by_tag_name('li.sui-result div.sui-result__header a')
print(all_links)
print()
# loop trough links and crawl them
for link in all_links:
# click on link
print(link)
time.sleep(4)
click = link.click() # I GET THE ERROR HERE ON SECOND ITERATION
time.sleep(4)
# get date
date = driver.find_element_by_tag_name('div.filter-data button.wlclight13').text
day = date.split('.')[0]
month = date.split('.')[1]
year = date.split('.')[2]
date = year "-" month "-" day
print(date)
print()
# click on back button
back_button = driver.find_element_by_xpath('//*[@id="root"]/div/section[1]/div[1]/div[1]/a').click()
time.sleep(4)
#scroll
driver.execute_script("window.scrollTo(0, 200)")
uj5u.com熱心網友回復:
而不是元素獲取href值并用于driver.get()導航。
//獲取href值
all_links =[link.get_attribute('href') for link in driver.find_elements_by_css_selector('li.sui-result >.sui-result__header> a')]
print(all_links)
for link in all_links:
driver.get(link)
driver.refresh()
# get date
date = WebDriverWait(driver, 10).until(EC.visibility_of_element_located((By.CSS_SELECTOR, "div.filter-data button.wlclight13"))).text
day = date.split('.')[0]
month = date.split('.')[1]
year = date.split('.')[2]
date = year "-" month "-" day
print(date)
如果您想繼續使用您的代碼,您需要重新分配您的元素,如下所示。
all_links = driver.find_elements_by_tag_name('li.sui-result div.sui-result__header a')
print(all_links)
print()
# loop trough links and crawl them
for link in range(len(all_links)):
#Re-assined it again
all_links = driver.find_elements_by_tag_name('li.sui-result div.sui-result__header a')
# click on link
print(all_links[link])
time.sleep(4)
all_links[link].click()
time.sleep(4)
# get date
date = driver.find_element_by_tag_name('div.filter-data button.wlclight13').text
day = date.split('.')[0]
month = date.split('.')[1]
year = date.split('.')[2]
date = year "-" month "-" day
print(date)
print()
# click on back button
back_button = driver.find_element_by_xpath('//*[@id="root"]/div/section[1]/div[1]/div[1]/a').click()
time.sleep(4)
#scroll
driver.execute_script("window.scrollTo(0, 200)")
更新:
導航 url 不重繪 頁面。添加driver.refresh()以顯示日期。
all_links =[link.get_attribute('href') for link in driver.find_elements_by_css_selector('li.sui-result >.sui-result__header> a')]
print(all_links)
for link in all_links:
driver.get(link)
driver.refresh()
# get date
date = WebDriverWait(driver, 10).until(EC.visibility_of_element_located((By.CSS_SELECTOR, "div.filter-data button.wlclight13"))).text
day = date.split('.')[0]
month = date.split('.')[1]
year = date.split('.')[2]
date = year "-" month "-" day
print(date)
您需要匯入以下庫。
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
輸出:
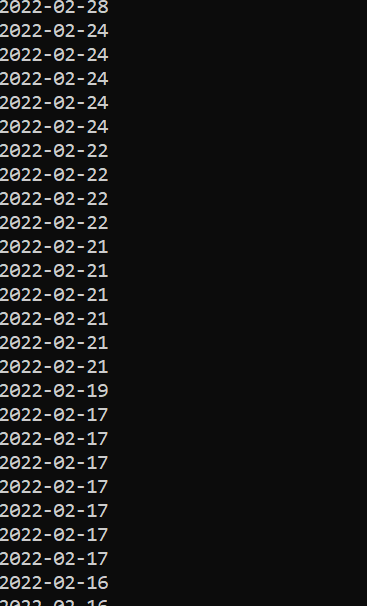
uj5u.com熱心網友回復:
如前所述,單擊后退按鈕是不穩定的。但可以使用“下一步”按鈕導航到其他鏈接。
最好應用一些顯式等待。
driver.get("https://bstger.weblaw.ch/?size=n_60_n")
wait = WebDriverWait(driver,30)
actions = ActionChains(driver)
buttonClickSearch = wait.until(EC.element_to_be_clickable((By.XPATH,"//input[@aria-label='search button']")))
actions.move_to_element(buttonClickSearch).click()
time.sleep(5)
all_links = driver.find_elements(By.XPATH,"//div[@class='sui-result__header']/a")
all_links[0].click() # Click on the First link.
for i in range(20):
...
next = wait.until(EC.element_to_be_clickable((By.XPATH,"//button[contains(@class,'next')]")))
next.click() # Click on next link for 20 iterations.
轉載請註明出處,本文鏈接:https://www.uj5u.com/net/436012.html
上一篇:使用Selenium和Python在每個請求上管理多個用戶代理
下一篇:從fo回圈添加到串列