問題
我正在嘗試標記圖表的左側,同時省略右側的注釋。
資料
這是我的庫和資料:
#### Libraries ####
library(tidyverse)
library(ggpubr)
library(plotly)
#### Dput ####
emlit <- structure(list(X = 1:20, Ethnicity = c("Asian (other than Chinese)",
"Filipino", "Indonesian", "Thai", "Japanese", "Korean", "South Asian",
"Indian", "Nepalese", "Pakistani", "Other South Asian", "Other Asian",
"White", "Mixed", "With Chinese parent", "Other mixed", "Others",
"All ethnic minorities", "All ethnic minorities, excluding\n foreign domestic helpers",
"Whole population"), Age_5.14 = c(65.8, 72.2, 69.4, 83.1, 26.6,
52.4, 67.4, 60.4, 69.5, 71.5, 92.5, 92, 34.8, 76.6, 84.2, 45.3,
51.3, 64.3, 64.3, 94.8), Age_15.24 = c(28.1, 29.2, 4.4, 72.9,
34.8, 50.3, 38.7, 41.4, 22.2, 54.3, 41.9, 64.7, 24.4, 82.9, 90.7,
37.4, 53.2, 40.6, 52.9, 96.9), Age_25.34 = c(4.5, 1.8, 4.6, 20,
17.2, 26.8, 6.6, 4.2, 6.4, 11.9, 12, 33.9, 15, 60.5, 82, 6.7,
11.2, 7.8, 21.8, 84.9), Age_35.44 = c(6.3, 2, 6.1, 35.7, 36.5,
25.5, 9.4, 6.2, 10.5, 10.1, 22.4, 35.7, 8.6, 63, 83.2, 4.5, 12.2,
9.5, 23.4, 84.6), Age_45.54 = c(8.1, 2.3, 8, 23.2, 43.4, 59.6,
7.5, 6.3, 3.9, 13.5, 28.3, 47.5, 13.1, 72.1, 84, 4.4, 22.4, 14.2,
27.7, 92.5), Age_55.64 = c(15.9, 4.4, 44, 27, 41.7, 52.8, 11.8,
7.4, 9.5, 2, 54.2, 39.6, 12.7, 75.3, 80.1, 2.6, 20.6, 25, 32.4,
94.8), Age_65. = c(31.1, 11.9, 82.6, 39, 46.4, 57, 9.5, 3.9,
NA, 11.4, 66.5, 74.5, 14.5, 80.5, 81, 57.5, 13.6, 42.7, 44, 82.3
), Age_Overall = c(10.1, 3.5, 6.4, 31.4, 35.1, 39.8, 20.4, 15.3,
16.4, 33.8, 30.4, 46.3, 15.4, 72.7, 83.9, 19.4, 19.8, 16.9, 35.2,
89.4)), class = "data.frame", row.names = c(NA, -20L))
我還為我的圖表旋轉了資料:
#### Pivot Data ####
emlitpivot <- emlit %>%
pivot_longer(cols = contains("Age"),
names_to = "Age_Range",
values_to = "Percent")
陰謀
到目前為止,這是我的情節,這是一個按年齡劃分讀寫能力的多面圖,左側的一些重要點有一些注釋:
#### EM vs all ####
# Order
order <- c("5-14", "15-24", "25-34", "35-44", "45-54", "55-64", "65 ", "Overall",
"5-14", "15-24", "25-34", "35-44", "45-54", "55-64", "65 ", "Overall")
# Plot
plot <- emlitpivot %>%
filter(Ethnicity %in% c("All ethnic minorities",
"Whole population")) %>%
ggbarplot(x="Age_Range",
y="Percent",
fill = "Ethnicity",
label = T,
palette = "jco",
facet.by = "Ethnicity",
title = "EM x Native Chinese Literacy by Age",
xlab = "Age Range",
ylab = "Literacy in Chinese (By Percent)",
caption = "*Data obtained from Census and Statistics Department Hong Kong SAR, 2016.")
theme_cleveland()
theme(axis.text.x = element_text(angle = 45,
hjust = .5,
vjust = .5),
legend.position = "none",
plot.caption = element_text(face = "italic"))
scale_x_discrete(labels=order)
geom_segment(aes(x = 3, y = 15, xend = 3, yend = 48))
geom_segment(aes(x = 1, y = 71, xend = 1, yend = 80))
geom_segment(aes(x = 7, y = 50, xend = 7, yend = 65))
annotate("text",
x=4,
y=53,
label = "Post-college workers can't read.")
annotate("text",
x=3.5,
y=85,
label = "School age supports seem to boost initial literacy.")
annotate("text",
x=6,
y=70,
label = "Increase due to generational literacy?")
# Print plot:
plot
但是,您可能會猜到問題所在:
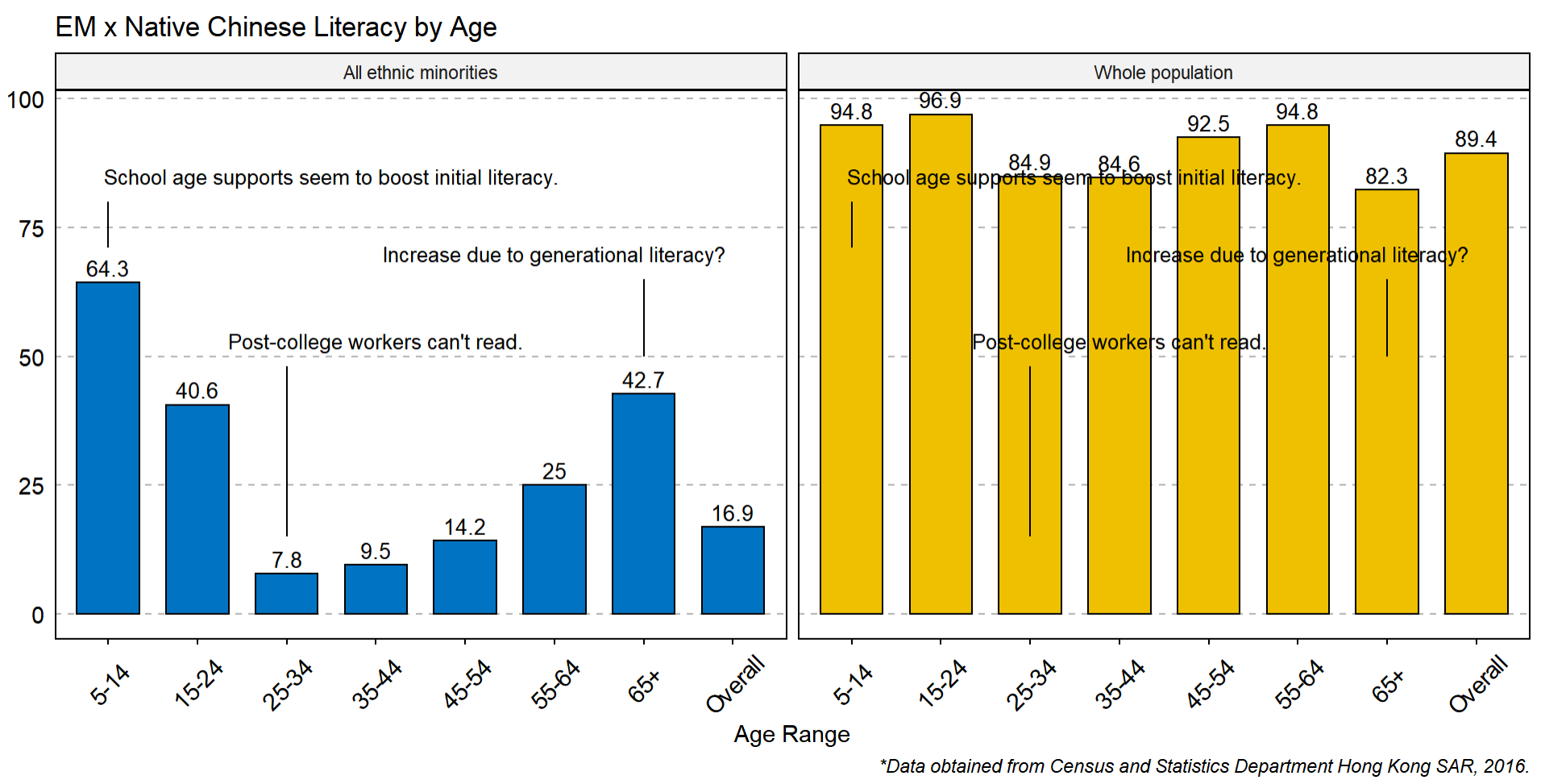
如何擺脫右側的注釋?我不確定是否有一種簡單的方法可以擺脫它們,但只在左側顯示文本會很有幫助。
uj5u.com熱心網友回復:
在這種情況下,我將使用geom_text而不是annotate,因為它允許您擁有subset您的資料。
library(tidyverse)
library(ggpubr)
emlitpivot %>%
filter(Ethnicity %in% c(
"All ethnic minorities",
"Whole population"
)) %>%
ggbarplot(
x = "Age_Range",
y = "Percent",
fill = "Ethnicity",
label = T,
palette = "jco",
facet.by = "Ethnicity",
title = "EM x Native Chinese Literacy by Age",
xlab = "Age Range",
ylab = "Literacy in Chinese (By Percent)",
caption = "*Data obtained from Census and Statistics Department Hong Kong SAR, 2016."
)
theme_cleveland()
theme(
axis.text.x = element_text(
angle = 45,
hjust = .5,
vjust = .5
),
legend.position = "none",
plot.caption = element_text(face = "italic")
)
scale_x_discrete(labels = order)
geom_segment(data = subset(emlitpivot, Ethnicity == "All ethnic minorities"), aes(x = 3, y = 15, xend = 3, yend = 48))
geom_segment(data = subset(emlitpivot, Ethnicity == "All ethnic minorities"), aes(x = 1, y = 71, xend = 1, yend = 80))
geom_segment(data = subset(emlitpivot, Ethnicity == "All ethnic minorities"), aes(x = 7, y = 50, xend = 7, yend = 65))
geom_text(data = subset(emlitpivot, Ethnicity == "All ethnic minorities"), aes(4, 53), label = "Post-college workers can't read.", check_overlap = T)
geom_text(data = subset(emlitpivot, Ethnicity == "All ethnic minorities"), aes(3.5, 85), label = "School age supports seem to boost initial literacy.", check_overlap = T)
geom_text(data = subset(emlitpivot, Ethnicity == "All ethnic minorities"), aes(6, 70), label = "Increase due to generational literacy?", check_overlap = T)
uj5u.com熱心網友回復:
在第二個方面更新洗掉行:
使用您的文本標簽和位置創建一個資料框并將其添加到繪圖中,以洗掉線條執行相同的程序:
df for text = ann_text df for lines = segm
ann_text <- data.frame(x = c(4, 3.5, 6),
y = c(53, 85, 70),
lab = c("Post-college workers can't read.", "School age supports seem to boost initial literacy.",
"Increase due to generational literacy?"),
Ethnicity = rep("All ethnic minorities", 3))
segm <- data.frame(x = c(3,1,7),
y = c(15, 71, 50),
xend = c(3,1,7),
yend = c(48,80,65),
Ethnicity = rep("All ethnic minorities", 3))
plot1 <- plot
geom_text(
data = ann_text,
mapping = aes(x = x, y = y, label = lab)
)
plot1 geom_segment(
data = segm,
mapping = aes(x = x, y = y, xend = xend, yend = yend)
)
從您的代碼中洗掉以下內容:
annotate("text",
x=4,
y=53,
label = "Post-college workers can't read.")
annotate("text",
x=3.5,
y=85,
label = "School age supports seem to boost initial literacy.")
annotate("text",
x=6,
y=70,
label = "Increase due to generational literacy?")
轉載請註明出處,本文鏈接:https://www.uj5u.com/net/438209.html
標籤:r ggplot2 tidyverse 注释 ggpubr
上一篇:從json到物件飛鏢