我遇到了以下問題。
You are given the root of a binary tree with n nodes.
Each node is uniquely assigned a value from 1 to n.
You are also given an integer startValue representing
the value of the start node s,
and a different integer destValue representing
the value of the destination node t.
Find the shortest path starting from node s and ending at node t.
Generate step-by-step directions of such path as a string consisting of only the
uppercase letters 'L', 'R', and 'U'. Each letter indicates a specific direction:
'L' means to go from a node to its left child node.
'R' means to go from a node to its right child node.
'U' means to go from a node to its parent node.
Return the step-by-step directions of the shortest path from node s to node t
示例 1:
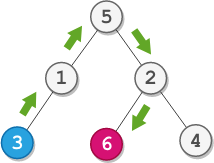
Input: root = [5,1,2,3,null,6,4], startValue = 3, destValue = 6
Output: "UURL"
Explanation: The shortest path is: 3 → 1 → 5 → 2 → 6.
示例 2:
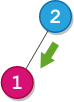
Input: root = [2,1], startValue = 2, destValue = 1
Output: "L"
Explanation: The shortest path is: 2 → 1.
我通過找到最不共同的祖先然后進行深度優先搜索來找到元素來創建解決方案,就像這樣:-
# Definition for a binary tree node.
# class TreeNode(object):
# def __init__(self, val=0, left=None, right=None):
# self.val = val
# self.left = left
# self.right = right
class Solution(object):
def getDirections(self, root, startValue, destValue):
"""
:type root: Optional[TreeNode]
:type startValue: int
:type destValue: int
:rtype: str
"""
def lca(root):
if root == None or root.val == startValue or root.val == destValue:
return root
left = lca(root.left)
right = lca(root.right)
if left and right:
return root
return left or right
def dfs(root, value, path):
if root == None:
return ""
if root.val == value:
return path
return dfs(root.left, value, path "L") dfs(root.right, value, path "R")
root = lca(root)
return "U"*len(dfs(root, startValue, "")) dfs(root, destValue, "")
該解決方案運行良好,但是對于非常大的輸入,它會引發“超出記憶體限制”錯誤,誰能告訴我如何優化解決方案,或者我可能會做什么讓我進入它?
uj5u.com熱心網友回復:
超出記憶體限制的原因是dfs函式的引數。您的“路徑”變數是一個字串,可以與樹的高度一樣大(如果它不平衡,它可以是整棵樹的大小)。
通常這不是問題,但path "L"會為函式的每個遞回呼叫創建一個新字串。除了非常慢之外,這意味著您的記憶體使用量是O(n^2),其中n是樹中的節點數。
例如,如果您的最終路徑是"L" * 1000,您的呼叫堆疊dfs將如下所示:
Depth 0: dfs(root, path = "")
Depth 1: dfs(root.left, path = "L")
Depth 2: dfs(root.left.left, path = "LL")
...
Depth 999: path = "L"*999
Depth 1000: path = "L"*1000
盡管呼叫了所有這些變數path,但它們都是完全不同的字串,一次占用~(1000*1000)/2 = 500,000字符的總記憶體。有一百萬個節點,這就是半萬億個字符。
現在,這不會僅僅因為字串是不可變的。事實上,即使您使用串列(可變的),您仍然會遇到這個問題,因為path ["L"]仍然會被迫創建path.
為了解決這個問題,您需要path在函式外部存盤一個變數dfs,并且只從遞回dfs函式附加到它。這將確保您只使用O(n)空間。
def dfs(root, value, path):
if root is None:
return False
if root.val == value:
return True
if dfs(root.left, value, path):
path.append("L")
return True
elif dfs(root.right, value, path):
path.append("R")
return True
return False
root = lca(root)
start_to_root = []
dfs(root, startValue, start_to_root)
dest_to_root = []
dfs(root, destValue, dest_to_root)
return "U" * len(start_to_root) ''.join(reversed(dest_to_root))
轉載請註明出處,本文鏈接:https://www.uj5u.com/net/438331.html