我有一個熊貓資料框,我想對其進行分組并為 col1 的每個值創建列,它們應該包含 col2 的值。和示例資料框:
data = {'item_id': {0: 2, 1: 2, 2: 2, 3: 3, 4: 3},
'feature_category_id': {0: 56, 1: 62, 2: 68, 3: 56, 4: 72},
'feature_value_id': {0: 365, 1: 801, 2: 351, 3: 802, 4: 75}}
df = pd.DataFrame(data)
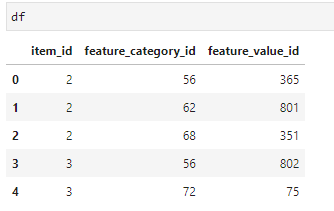
我想按 item_id 分組,創建與 feature_category_id 一樣多的列,并用 feature_value_id 填充它們。
該示例的結果 df 如下所示:
data = {'item_id': {0: 2, 1: 3},
'feature_56': {0: 801, 1: 802},
'feature_62': {0: 365, 1: None},
'feature_68': {0: 351, 1: None},
'feature_72': {0: None, 1: 75},}
df = pd.DataFrame(data)
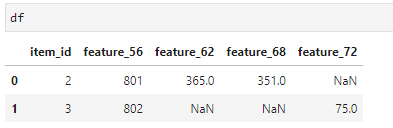
某個 item_id 不存在的特征(但至少一個 item_id 存在)是 NaN。
哪個是執行此操作的最佳操作?
uj5u.com熱心網友回復:
您正在尋找的是熊貓pivot()功能。它完全符合您的要求:
# Change df shape
result = df.pivot(index="item_id", columns="feature_category_id")
# Change the axis labels
result.columns = ["feature_" str(x[1]) for x in result.columns]
result = result.reset_index()
輸出:
item_id feature_56 feature_62 feature_68 feature_72
0 2 365.0 801.0 351.0 NaN
1 3 802.0 NaN NaN 75.0
轉載請註明出處,本文鏈接:https://www.uj5u.com/net/439390.html
上一篇:在多列值之間創建新列
下一篇:如何洗掉超過一定列數的行