網站上的資料量(頁數)不斷變化,我需要刮掉所有回圈通過分頁的頁面。網站:https://monentreprise.bj/page/annonces
我試過的代碼:
xpath= "//*[@id='yw3']/li[12]/a"
while True:
next_page = driver.find_elements(By.XPATH,xpath)
if len(next_page) < 1:
print("No more pages")
break
else:
WebDriverWait(driver, 10).until(EC.element_to_be_clickable((By.XPATH, xpath))).click()
print('ok')
ok連續列印
uj5u.com熱心網友回復:
這里有幾個問題:
//*[@id='yw3']/li[12]/a不是next分頁按鈕的正確定位器。- 此處到達最后一頁狀態的更好指示是驗證此基于 css_locator 的元素是否
.pagination .next包含disabled類。 - 在單擊下一頁按鈕之前,您必須向下滾動頁面
- 單擊分頁按鈕后,您必須添加延遲。否則這將不起作用。
這段代碼對我有用:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import time
driver = webdriver.Chrome()
my_url = "https://monentreprise.bj/page/annonces"
driver.get(my_url)
next_page_parent = '.pagination .next'
next_page_parent_arrow = '.pagination .next a'
while True:
driver.execute_script("window.scrollTo(0, document.body.scrollHeight)")
time.sleep(0.5)
parent = driver.find_element(By.CSS_SELECTOR,next_page_parent)
class_name = parent.get_attribute("class")
if "disabled" in class_name:
print("No more pages")
break
else:
WebDriverWait(driver, 10).until(EC.element_to_be_clickable((By.CSS_SELECTOR, next_page_parent_arrow))).click()
time.sleep(1.5)
print('ok')
輸出是:
ok
ok
ok
ok
ok
ok
ok
ok
ok
ok
ok
ok
ok
No more pages
uj5u.com熱心網友回復:
因為條件if len(next_page)<1始終為 False。
例如,我嘗試了網址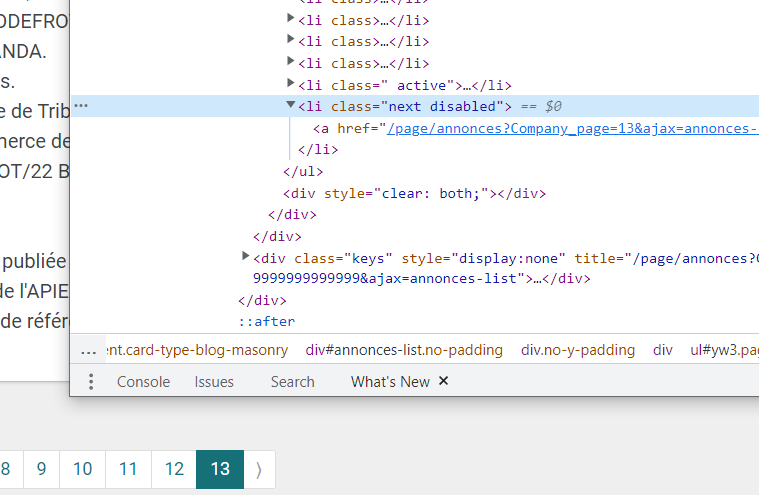
轉載請註明出處,本文鏈接:https://www.uj5u.com/net/444795.html