我正在嘗試將 SQL 結果替換為帶有 asterix、* 的所有中間值。所有的結果都是文字。我正在使用 SSMS。4-5個字母的單詞,應該只顯示1個字母開頭,1個字母到結尾。6個字母以上,它應該只顯示2個字母開頭,2個字母結尾。1-3 個字母,不可替換。
例如:(我現在使用 - 而不是 * 所以它不會使文本變粗)。
“香蕉”6個字母應該變成ba--na
“假”5個字母應該變成F---e
"a" 保持不變
“Selin 是蔬菜,香蕉是水果”變成“S---n 是 ve-----le,ba--na 是 f---t”。
到目前為止,我所做的就是在@之后為電子郵件制作這個。但現在我希望它發生在結果的每一個字上。
我做了什么:
DECLARE @String VARCHAR(100) = '[email protected]'
SELECT STUFF(STUFF(@STring,
CHARINDEX('@',@String) 2,
(CHARINDEX('.',@String, CHARINDEX('@',@String))-CHARINDEX('@',@String)-3),
REPLICATE('*',CHARINDEX('.',@String, CHARINDEX('@',@String))-CHARINDEX('@',@String)))
,2
,CHARINDEX('@',@String)-3
,REPLICATE('*',CHARINDEX('@',@String)-3))```
- 代替 -
我嘗試了掩碼方法
Select
--select first character from Email and use replicate
SUBSTRING(Sxolia,1,1) REPLICATE('*',5)
--function to put asterisks
SUBSTRING(Sxolia,CHARINDEX('@',Sxolia),len(Sxolia)-CHARINDEX('@',Sxolia) 1)
--at this statement i select this part @gmail,com and to first part to become like this A*****@gmail.com
as Emailmask
From [mytable]
結果 B***** Bana 是水果
和
declare @str nvarchar(max)
select @str = '123456'
select '****' substring(@str, 5, len(@str) - 3)
結果:****56
不是我要找的。
我應該如何看待這個?
uj5u.com熱心網友回復:
如果我必須在 SQL Server 中處理這個問題,我會將每個單詞作為一行進行操作,但是使用string_split不是(當前)一個選項,因為它不能保證排序。
下面使用 json 將字串拆分為一個陣列,并提供一個key值用于排序,這允許單詞以正確的順序聚合:
select t.Sentence,
String_Agg( masked, ' ') within group(order by seq) Masked
from t
cross apply (
select seq, [value] word,
case
when l<=3 then [value]
when l<=5 then Stuff([value],2,l-2,Replicate('*',l-2))
else
Stuff([value],3,l-4,Replicate('*',l-4))
end Masked
from (
select j.[value], 1 Convert(tinyint,j.[key]) Seq
from OpenJson(Concat('["',replace(t.Sentence,' ', '","'),'"]')) j
)w
cross apply (values(Len([value])))x(l)
)w
group by t.Sentence;
查看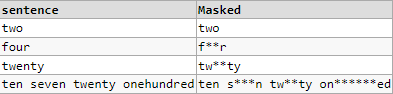
uj5u.com熱心網友回復:
我不確定電子郵件是如何適應這一切的,因為您要的是文字掩碼,所以我假設您確實想要這個。使用分而治之來實作這一點,因此首先實作一個運算式,該運算式將針對最簡單的情況(例如單個單詞)執行此操作。然后,如果您需要將它用于電子郵件,只需按照您認為合適的方式拆分電子郵件,然后應用相同的運算式。
運算式本身相當簡單:
SELECT *
FROM (VALUES
('banana'),
('selin'),
('vegetable')
) words(word)
CROSS
APPLY (SELECT CASE
WHEN ln BETWEEN 4 AND 5
THEN LEFT(word, 1) REPLICATE('*', ln-2) RIGHT(word, 1)
WHEN ln >= 6
THEN LEFT(word, 2) REPLICATE('*', ln-4) RIGHT(word, 2)
ELSE word
END as result
FROM (VALUES (LEN(words.word))) x(ln)
) calc
這已經提供了預期的結果。如果您有權限,您可以從中定義一個函式,并像這樣使用它:
SELECT *
FROM (VALUES
('banana'),
('selin'),
('vegetable')
) words(word)
CROSS
APPLY fnMaskWord(word)
這是一個關于 dbfiddle 的作業演示,它包括創建函式的陳述句。
uj5u.com熱心網友回復:
擴展幾個答案:
select case when len(@String) <= 3 then @String
when len(@String) > 3 AND len(@String) <= 5 then
substring(@String, 1, 2)
REPLICATE('*', Len(@String) - 2)
substring(@String, Len(@String) - 1, 2)
when len(@String) >= 6 then
substring(@String, 1, 2)
REPLICATE('*', Len(@String) - 2)
substring(@String, Len(@String) - 1, 2)
else 'unrecognized length!'
如果字串的長度小于等于 3,則回傳字串。
如果字串的長度大于 3 且小于或等于 5,則從位置 1 開始創建一個子字串,然后將 * 復制字串的長度 -2,最后從字串末尾添加另一個子字串 -1 . 如果結果超過 6 個字符,則類似。其他無法識別的長度!
希望這有助于了解發生了什么!
uj5u.com熱心網友回復:
也許這可以幫助
declare @t table (word varchar(50))
insert into @t values ('banana'), ('selin'), ('vegetable')
select case when len(t.word) < 3 then t.word
else left(t.word, 1) -- take first char from left
replicate('*', Len(t.word) - 2) -- fill middle with *
right(t.word, 1) -- take last char from right
end
from @t t
這回傳
| 第 1 列 |
|---|
| b****a |
| s***l |
| v*******e |
如果您想在 len > 5 時左右保留 2 個字符,那么也許這個
select case when len(t.word) < 3 then t.word
when len(t.word) < 6 then
left(t.word, 1)
replicate('*', len(t.word) - 2)
right(t.word, 1)
else left(t.word, 2)
replicate('*', len(t.word) - 4)
right(t.word, 2)
end
from @t t
結果
| 第 1 列 |
|---|
| 巴**娜 |
| s***l |
| ve*****le |
編輯:如果有一個完整的句子怎么辦?
那么我們首先將句子拆分為單詞,
然后將各個單詞重新組合在一起,同時將 ** 放入其中
declare @t table (word varchar(50))
insert into @t values ('banana'), ('selin'), ('vegetable'), ('Banana is a fruit')
select t.word,
-- put the words back togheter into the sentence, and ** them while we are at it
( select string_agg(case when len(value) < 3 then value
when len(value) < 6 then
left(value, 1)
replicate('*', len(value) - 2)
right(value, 1)
else left(value, 2)
replicate('*', len(value) - 4)
right(value, 2)
end,
' ')
)
from @t t
cross apply string_split(t.word, ' ') s -- split the sentence into words
group by t.word
結果是
word COLUMN1
---- -------
banana ba**na
Banana is a fruit Ba**na is a f***t
selin s***n
vegetable ve*****le
轉載請註明出處,本文鏈接:https://www.uj5u.com/net/447888.html
上一篇:違反復合鍵中的唯一鍵約束?
下一篇:客戶余額老化報告