我正在使用str.join(讓我們稱之為加入的列col_str)和groupby(讓我們稱之為分組的 col col_a)的組合來按行匯總資料。
col_str, 可能包含nan值。不出所料,正如str.join 
為了緩解這種情況,我嘗試轉換col_str為字串(例如 df['col_str'] = df['col_str'].astype(str))。但是,空值現在實際上有一個字串nan值,因此被認為是非空的。
現在不僅str.join包括nan字串,而且依賴于這些 nan 的腳本上的其他計算也被破壞了。
為了解決這個問題,我考慮只轉換非空值,如下所示:
df['col_str'] = np.where(pd.isnull(df['col_str']), df['col_str'],
df['col_str'].astype(str))
但現在str.join再次回傳空值:-(
所以,我嘗試fillna('')了,甚至dropna()。沒有人為我提供了預期的結果。
你在這里得到了惡性回圈,對吧?
astype(str)=>nan連接中的字串和計算被破壞 保持原樣 =>join.str回傳空結果。
謝謝你的協助!
編輯:資料是從 csv 讀取的。樣本:
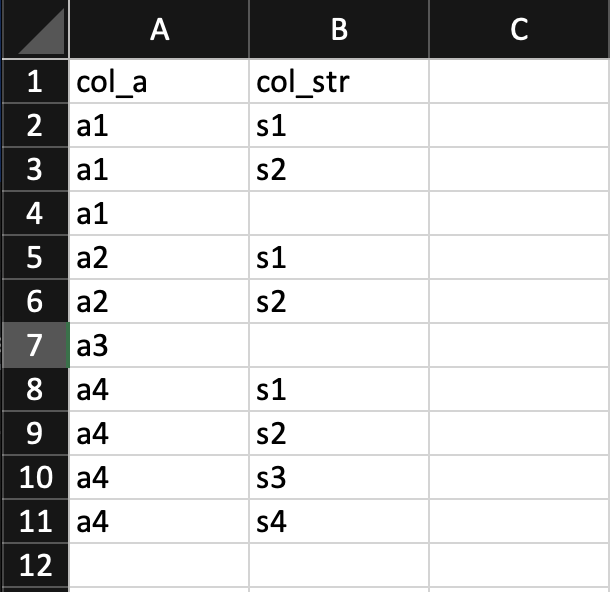
要測驗的代碼 -
df = pd.read_csv('/Users/goidelg/Downloads/sample_data.csv', low_memory=False)
print("---Original DF ---")
print(df)
print("---Joining NaNs as NaN---")
print(df.join(df['col_a'].map(df.groupby('col_a')['col_str'].unique().str.join(', ')).rename('strings_concat')))
print("---Convertin col to str---")
df['col_str'] = df['col_str'].astype(str)
print(df.join(df['col_a'].map(df.groupby('col_a')['col_str'].unique().str.join(', ')).rename('strings_concat')))
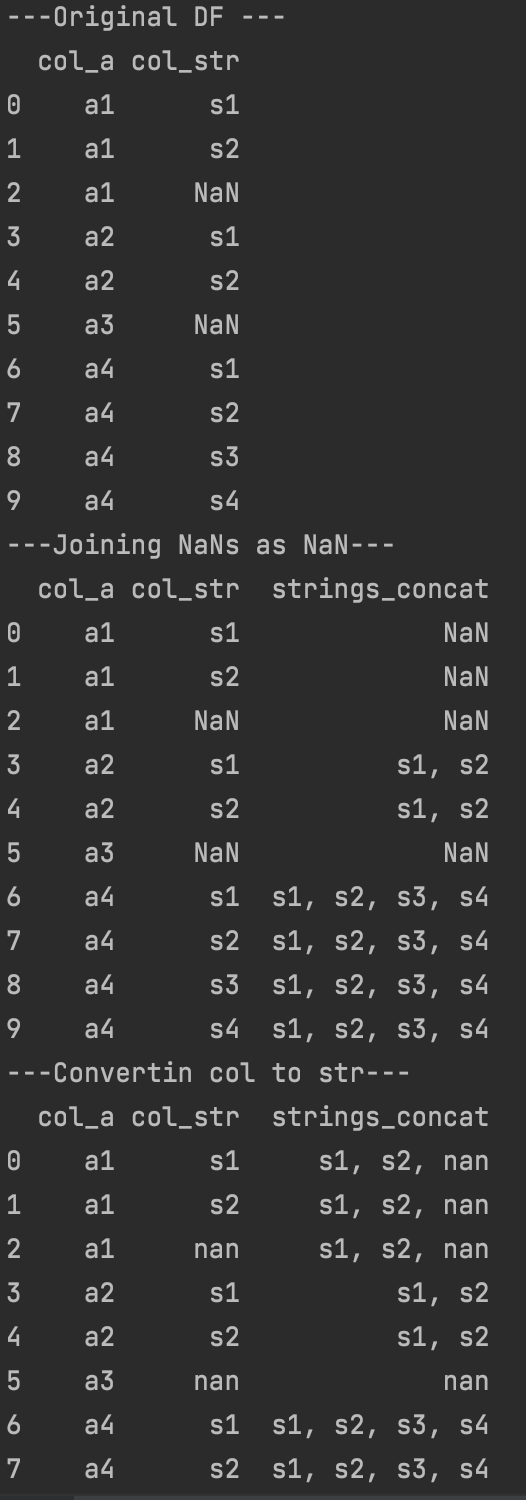
腳本的結果:
uj5u.com熱心網友回復:
DataFrame.dropna首先通過或Series.notnain洗掉缺失值boolean indexing:
df = pd.DataFrame({'col_a':[1,2,3,4,1,2,3,4,1,2],
'col_str':['a','b','c','d',np.nan, np.nan, np.nan, np.nan,'a', 's']})
df1 = (df.join(df['col_a'].map(df[df['col_str'].notna()]
.groupby('col_a')['col_str'].unique()
.str.join(', ')). rename('labels')))
print (df1)
col_a col_str labels
0 1 a a
1 2 b b, s
2 3 c c
3 4 d d
4 1 NaN a
5 2 NaN b, s
6 3 NaN c
7 4 NaN d
8 1 a a
9 2 s b, s
df2 = (df.join(df['col_a'].map(df.dropna(subset=['col_str'])
.groupby('col_a')['col_str']
.unique().str.join(', ')).rename('labels')))
print (df2)
col_a col_str labels
0 1 a a
1 2 b b, s
2 3 c c
3 4 d d
4 1 NaN a
5 2 NaN b, s
6 3 NaN c
7 4 NaN d
8 1 a a
9 2 s b, s
轉載請註明出處,本文鏈接:https://www.uj5u.com/net/449604.html