有沒有辦法通過第一個資料幀中的一行與第二個資料幀中的每一行連接來連接兩個資料幀,如果它們共享一個詞?
例如:
companies1 <- data.frame(company_name = c("Walmart", "Amazon", "Apple", "CVS Health", "UnitedHealth Group", "Berkshire Hathaway", "Alphabet"))
companies2 <- data.frame(company_name = "Walmart Stores", "Walmart Inc", "Amazon Web Services", "Amazon Alexa", "Apple", "Apple Products", "CVS Health", "UnitedHealth Group", "Berkshire Hathaway", "Berkshire Hathaway Asset Management", "Meta"))
我想匹配這些,然后回傳左右列之間的每一個可能的匹配,如下所示:
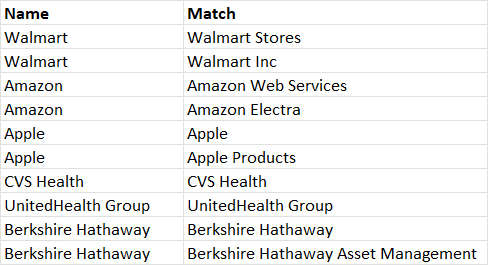
我已經嘗試過諸如fuzzymatch 和stringdist 之類的包,但為了匹配這些似乎只回傳最佳匹配。然而,由于我正在做的匹配不如上面的那么整潔而且更大,我的計劃是找到可能的匹配,然后給他們一個距離分數(例如使用 Jaro-Winkler 距離),此時我'必須手動選擇正確的匹配項(如果有)。
uj5u.com熱心網友回復:
與fuzzy_join:
library(fuzzyjoin)
fuzzy_join(companies2, companies1, match_fun = stringr::str_detect)
company_name.x company_name.y
1 Walmart Stores Walmart
2 Walmart Inc Walmart
3 Amazon Web Services Amazon
4 Amazon Alexa Amazon
5 Apple Apple
6 Apple Products Apple
7 CVS Health CVS Health
8 UnitedHealth Group UnitedHealth Group
9 Berkshire Hathaway Berkshire Hathaway
10 Berkshire Hathaway Asset Management Berkshire Hathaway
或者,如果您想尊重列的順序:
fuzzy_join(companies1, companies2, match_fun = function(x, y) stringr::str_detect(y, x))
company_name.x company_name.y
1 Walmart Walmart Stores
2 Walmart Walmart Inc
3 Amazon Amazon Web Services
4 Amazon Amazon Alexa
5 Apple Apple
6 Apple Apple Products
7 CVS Health CVS Health
8 UnitedHealth Group UnitedHealth Group
9 Berkshire Hathaway Berkshire Hathaway
10 Berkshire Hathaway Berkshire Hathaway Asset Management
轉載請註明出處,本文鏈接:https://www.uj5u.com/net/449614.html