目前我的資料集如下:
| ID | 價值 |
|---|---|
| 1 | str1/value1,str2/value21,value22,value23,str3/value31,value32 |
| 2 | str4/value4,str5/value51,value52,value53,str6/value61,value62 |
我想先用逗號(',')分割資料,然后在('/')上分割資料,但我想用逗號保留'/'之后的所有出現。此外,我需要將它們拆分為行值。
輸出應該是:
| ID | 字串 | 價值 |
|---|---|---|
| 1 | str1 | 價值1 |
| 1 | str2 | 價值21,價值22,價值23 |
| 1 | str3 | 價值31,價值32 |
| 2 | str4 | 價值4 |
| 2 | str5 | 價值51,價值52,價值53 |
| 2 | str6 | 值61,值62 |
請有人可以幫助我以有效的方式做到這一點,而不是為每次出現回圈它。
uj5u.com熱心網友回復:
IIUC,您可以使用帶有正則運算式的雙重拆分:
df['str'] = df['value'].str.split(r',(?=[^/,] /)')
df = df.explode('str')
df[['str', 'value']] = df['str'].str.split('/', expand=True)
輸出:
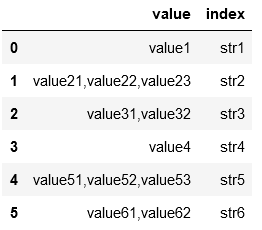
ID value str
0 1 value1 str1
0 1 value21,value22,value23 str2
0 1 value31,value32 str3
1 2 value4 str4
1 2 value51,value52,value53 str5
1 2 value61,value62 str6
或者,生成一個新的資料幀,extractall并命名為捕獲組 a join:
df2 = (df[['ID']]
.join(df['value']
.str.extractall(r'(?P<str>[^,/] )/(?P<value>[^/] ?)(?=,[^,] /|$)')
.droplevel(1))
)
輸出:
ID str value
0 1 str1 value1
0 1 str2 value21,value22,value23
0 1 str3 value31,value32
1 2 str4 value4
1 2 str5 value51,value52,value53
1 2 str6 value61,value62
轉載請註明出處,本文鏈接:https://www.uj5u.com/net/453378.html