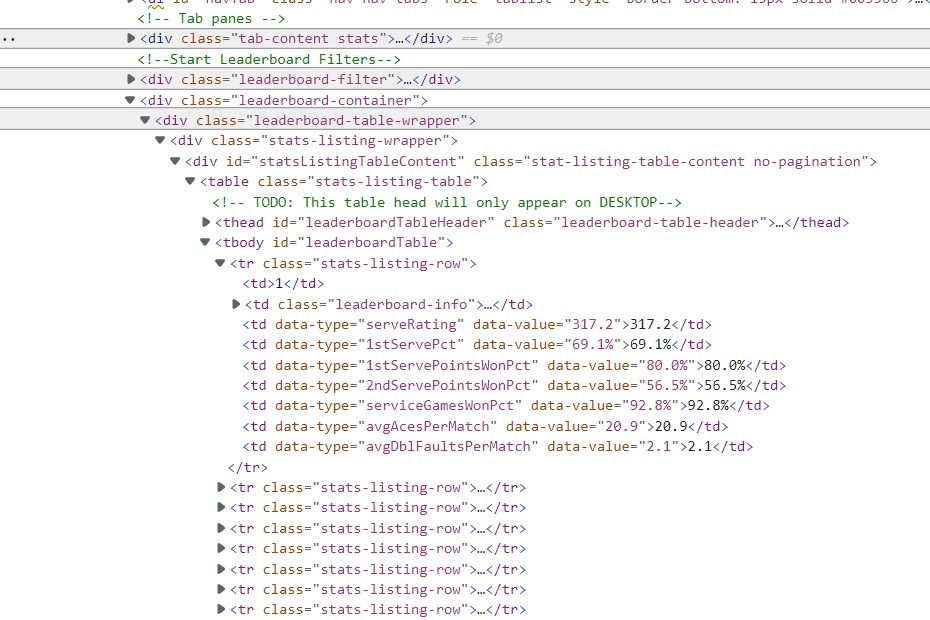
我正在嘗試從該站點抓取主表:
如何訪問 html 的其余部分?當我搜索湯時,它似乎不在那里。我還附上了我要訪問的 html 的影像。任何幫助表示贊賞。謝謝!
uj5u.com熱心網友回復:
有一個 ajax 請求可以獲取該資料,但是它被 cloudcraper 阻止了。有一個包可以繞過它,但似乎不適用于該站點。
您現在需要做的是使用 Selenium 之類的東西來允許首先呈現頁面,然后提取資料。
from selenium import webdriver
import pandas as pd
browser = webdriver.Chrome('C:/chromedriver_win32/chromedriver.exe')
browser.get("https://www.atptour.com/en/stats/leaderboard?boardType=serve&timeFrame=52Week&surface=all&versusRank=all&formerNo1=false")
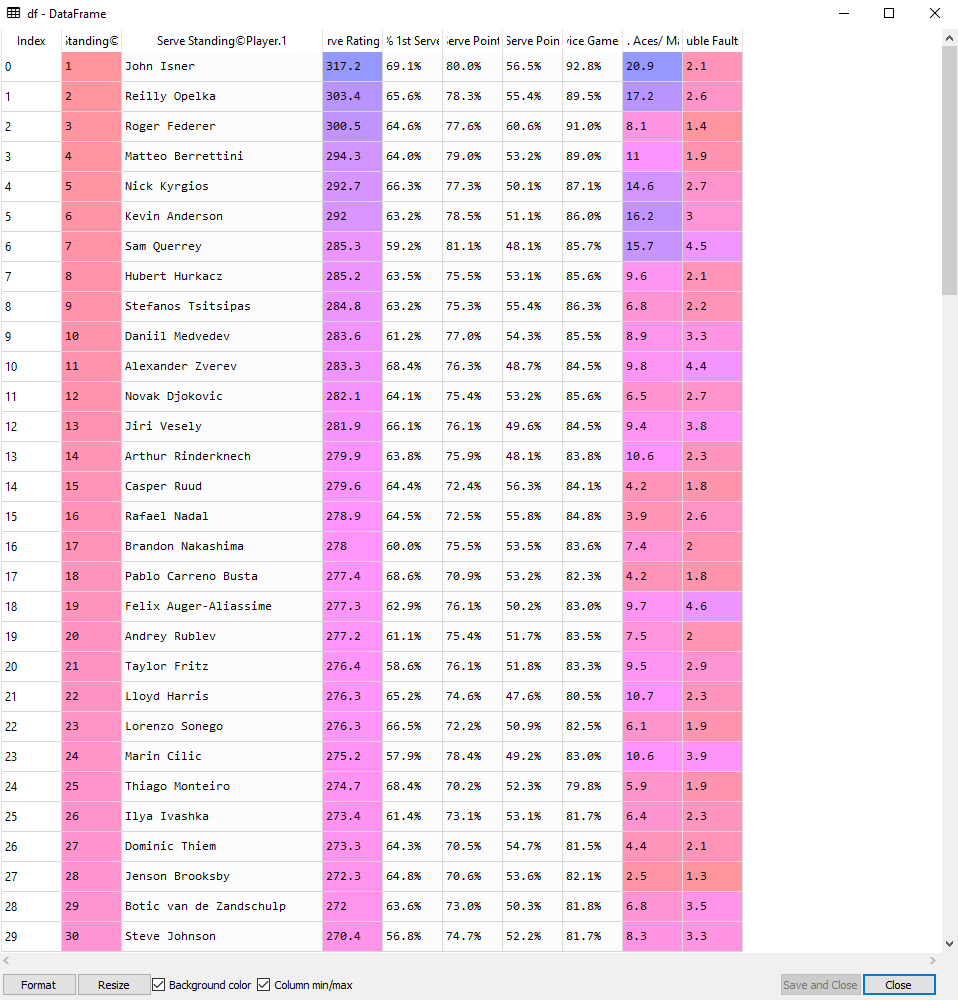
df= pd.read_html(browser.page_source, header=0)[0]
browser.close()
輸出:
uj5u.com熱心網友回復:
您的代碼按預期作業。您正在決議的 HTML 表下沒有任何資料。
$ wget https://www.atptour.com/en/stats/leaderboard\?boardType\=serve\&timeFrame\=52Week\&surface\=all\&versusRank\=all\&formerNo1\=false -O page.html
$ grep -C 3 'leaderboardTable' page.html
class="stat-listing-table-content no-pagination">
<table class="stats-listing-table">
<!-- TODO: This table head will only appear on DESKTOP-->
<thead id="leaderboardTableHeader" class="leaderboard-table-header">
</thead>
<tbody id="leaderboardTable"></tbody>
</table>
</div>
您已經顯示了包含資料的開發人員視圖的螢屏截圖。我猜想有一個 Javascript在加載并放入行后修改 HTML。您的瀏覽器能夠運行此 Javascript,因此您會看到這些行。requests當然不運行任何腳本,它只下載 HTML。
您可以在瀏覽器中“另存為”以獲取重新使用的 HTML,或者您將不得不使用更高級的 Web 模塊,例如可以運行腳本的 Selenium。
轉載請註明出處,本文鏈接:https://www.uj5u.com/net/455138.html
上一篇:使用美麗的湯查找資料