我會盡量直截了當,如何格式化這個輸出?
import requests
import pandas as pd
from bs4 import BeautifulSoup
import json
headers = {
'access-control-allow-credentials': 'true',
'access-control-allow-headers': 'Content-Type',
'content-type': 'application/json; charset=utf-8',
'referer': 'https://www.giga.com.vc/padaria?initialMap=c&initialQuery=padaria&map=category-1&page=2',
'accept': '*/*',
'accept-encoding': 'gzip, deflate, br',
'x-request-id': '24af6e1c94114c5488296d68ef93daf2',
'x-vtex-cache-status': 'EXPIRED',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.84 Safari/537.36'
}
req = requests.get(f'https://www.giga.com.vc/padaria?initialMap=c&initialQuery=padaria&map=category-1&page=1', headers=headers)
# print(req)
soup = BeautifulSoup(req.content, 'lxml')
soup_script = soup.find_all('script')[14].text
print(soup_script)
收到的輸出:
{"Product:sp-139989":{"cacheId":"sp-139989","productId":"139989","description":"Bolinho sabor Duplo Chocolate Bauducco é irresistível. Sua Fórmula é enriquecida com vitaminas e cálcio, ótimo para ser levado na lancheira dos pequenos, na bolsa ou na mochila. O Sabor Baunilha e Morango é a perfeita combina??o entre massa de baunilha e recheio de morango, um bolinho fofinho e delicioso!","productName":"Bolinho sabor Baunilha e Morango Bauducco 40G","productReference":"223184","linkText":"mini-bolo-de-baunilha-e-morango-bauducco-40g","bra..
期望的輸出:productId、productName、description、ean、price、specificationGroups 以及我可以通過代碼輕松檢索到的東西。
謝謝。
uj5u.com熱心網友回復:
可能的解決方案如下:
import requests
import pandas as pd
from bs4 import BeautifulSoup
import json
import re
# set to show all columns
pd.set_option('display.max_columns', None)
headers = {
'access-control-allow-credentials': 'true',
'access-control-allow-headers': 'Content-Type',
'content-type': 'application/json; charset=utf-8',
'referer': 'https://www.giga.com.vc/padaria?initialMap=c&initialQuery=padaria&map=category-1&page=2',
'accept': '*/*',
'accept-encoding': 'gzip, deflate, br',
'x-request-id': '24af6e1c94114c5488296d68ef93daf2',
'x-vtex-cache-status': 'EXPIRED',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.84 Safari/537.36'
}
req = requests.get(f'https://www.giga.com.vc/padaria?initialMap=c&initialQuery=padaria&map=category-1&page=1', headers=headers)
soup = BeautifulSoup(req.content, 'lxml')
soup_script = soup.find_all('script')[14].text
data = json.loads(soup_script)
# save raw data to file
with open("data.json", "w", encoding="utf-8") as file:
file.write(json.dumps(data))
# read raw data from file
with open("data.json", "r", encoding="utf-8") as file:
data = json.load(file)
# cleanup raw data
re_pattern_key_filter = r'sp-\d{6}'
re_pattern_key_rename = r'(.*?)(sp-\d{6})(.*?)$'
# filter out trash data and cleanup keys in dictionary
raw_target_data = [(re.sub(re_pattern_key_rename, r'\2', key), value) for key, value in data.items() if re.search(re_pattern_key_filter, key)]
# merge data to product_id nested dict
raw_product_id_data = {}
for key, value in raw_target_data:
raw_product_id_data.setdefault(key, []).append(value)
# merge data to product_id dict
product_data = {}
for key, value in raw_product_id_data.items():
product_data[key] = [{k: v for d in value for k, v in d.items()}]
# create dataframe for each product and add to list
all_dfs = []
for k, v in product_data.items():
df = pd.json_normalize(v)
all_dfs.append(df)
# merge product dataframes into one
df = pd.concat(all_dfs).reset_index(drop=True)
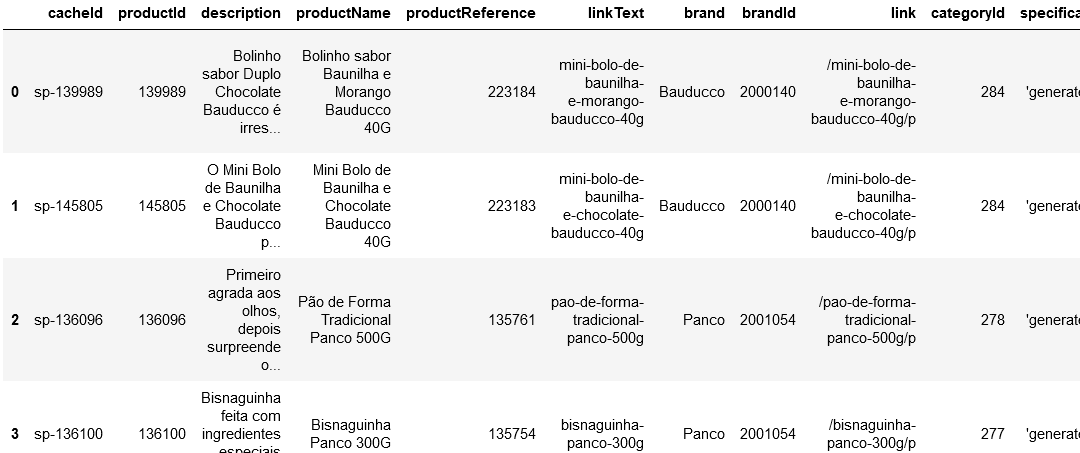
df.head()
退貨
轉載請註明出處,本文鏈接:https://www.uj5u.com/net/455146.html
上一篇:使用waitForSelector()時出現Puppeteer超時錯誤
下一篇:Python請求網頁抓取API