我一直在嘗試抓取一個網站,例如下面的網站。在頁腳有一堆他們社交媒體的鏈接,其中LinkedIn URL是我關注的焦點。有沒有辦法只使用正則運算式或 Python 中可用的任何其他庫來找出該鏈接。
這是我迄今為止嘗試過的 -
import requests
from bs4 import BeautifulSoup
url = "https://www.southcoast.org/"
req = requests.get(url)
soup = BeautifulSoup(reqs.text,"html.parser")
for link in soup.find_all('a'):
print(link.get('href'))
但我正在獲取所有 URL,而不是我正在尋找的那個。
注意:我希望有一個動態代碼,我也可以將它用于其他站點。
提前感謝您的建議/幫助。
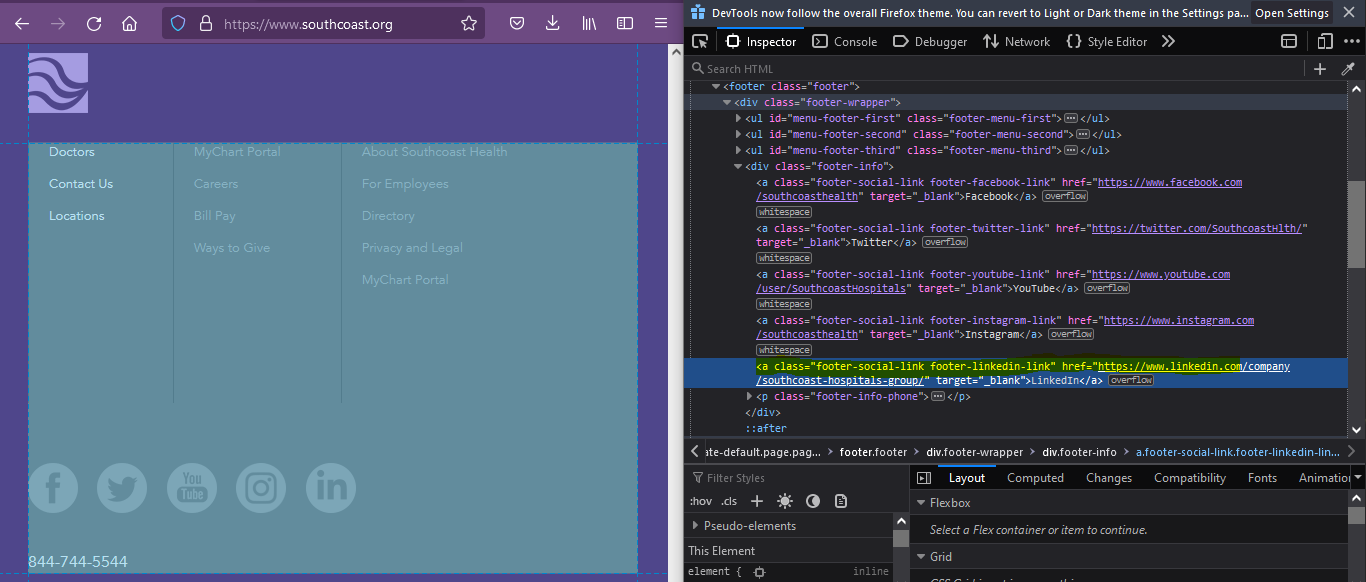
uj5u.com熱心網友回復:
一種方法是在屬性值中使用css selectors和查找字串:linkedin.com/company/href
soup.select_one('a[href*="linkedin.com/company/"]')['href']
例子
import requests
from bs4 import BeautifulSoup
url = "https://www.southcoast.org/"
req = requests.get(url)
soup = BeautifulSoup(req.text,"html.parser")
# single (first) link
link = e['href'] if(e := soup.select_one('a[href*="linkedin.com/company/"]')) else None
# multiple links
links = [link['href'] for link in soup.select('a[href*="linkedin.com/company/"]')]
轉載請註明出處,本文鏈接:https://www.uj5u.com/net/455153.html
標籤:Python python-3.x 正则表达式 网页抓取 美丽的汤
上一篇:抓取時需要幫助獲取tr值