之前在《基于樹狀位壓縮陣列的字符集合》中介紹了一種利用位壓縮陣列來減少空間占用和提高集合操作效率的字符集合 CharSet,
實際測驗下來,CharSet 的耗時只有 HashSet<char> 的 50%~80%,而集合操作的耗時更是只有 10%,舊文章里最后的測驗結論有問題,應該是誤使用 Debug 包來做性能測驗導致的,最新的測驗分別測驗了下列五個場景的性能,并調整了測驗的回圈次數使得 HashSet<char> 耗時接近,便于對比:
- 單字符操作:包含 70%
Add呼叫和 30%Remove呼叫, - 小范圍操作:包含 70%
Add呼叫和 30%Remove呼叫,范圍長度 1~10) - 大范圍操作:包含 70%
Add呼叫和 30%Remove呼叫,范圍長度 1~100) - 查找操作:
Contains呼叫, - 集合操作:
UnionWith、ExceptWith,SymmetricExceptWith和IntersectWith呼叫,
結果如圖 1 所示:
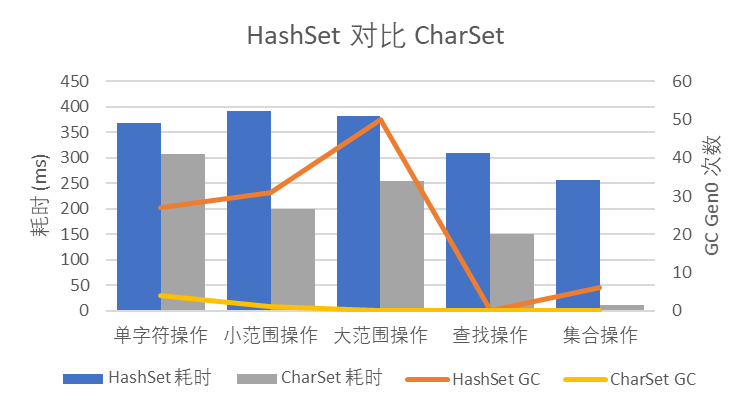
圖 1 HashSet 對比 CharSet
可以看到,CharSet 的性能優于 HashSet<char>,特別是集合操作,位壓縮資料可以批量進行集合操作,大大提高了性能,并且由于 CharSet 的記憶體消耗基本是固定的,GC 壓力也遠遠小于 HashSet<char>,
但是在實際使用程序中,涉及 Unicode 范圍的邏輯很少會對單個字符做操作,更多的是對字符范圍做操作,之前在《判斷字符寬度》中整理的寬字符范圍就是一個很好的例子,這里用到了 45 個字符范圍,大部分范圍長度小于 10,但最大的一個字符范圍達到了 22224 個字符,具體的字符范圍統計情況可以參見下圖,
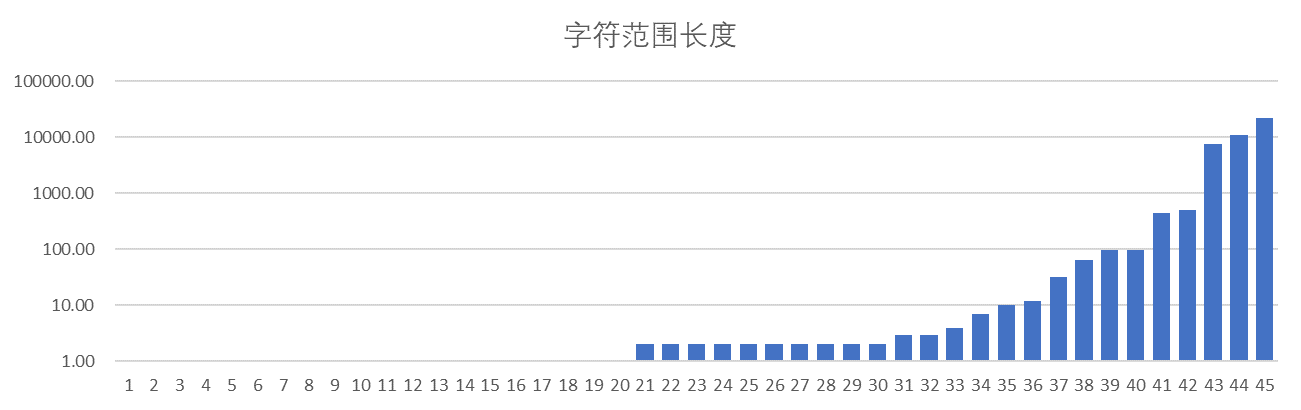
圖 2 字符范圍統計
對于這類大范圍字符操作,雖然 CharSet 的效率還是比較高的,但與其他操作仍然處在在同一個水平,
基于平衡二叉樹的字符集合
那么應該如何在范圍操作這種常見場景下進行優化呢?一種想法是拋棄位壓縮陣列,直接將基于范圍操作重新實作一套字符集合,這里選用了 AVL 樹作為底層資料結構,與紅黑樹相比實作更為簡單,性能也差別不大,
將字符范圍的起始值作為 AVL 樹的鍵,結束值作為相應節點的值,實作了一個 RangeCharSet,
但可惜的是,實測下來這樣的實作性能并不高,如圖 3 所示,RangeCharSet 的性能基本都明顯差于 HashSet<char>,GC 壓力也很高;只有作為優化目的的大范圍操作性能明顯極高,耗時只有 HashSet<char> 的 23%,
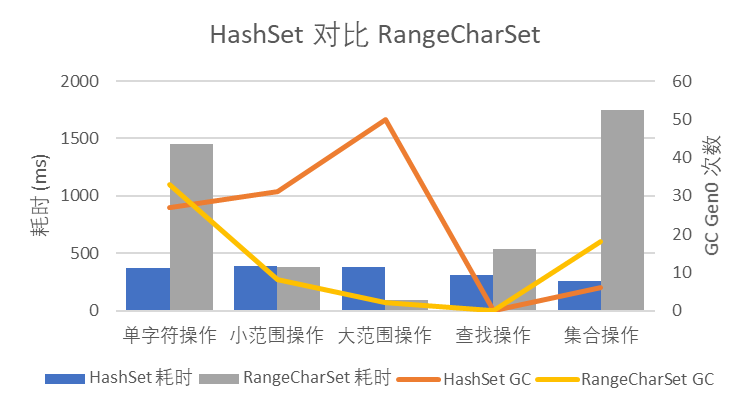
圖 3 HashSet 對比 RangeCharSet
不過 RangeCharSet 的性能還是高于同樣基于平衡二叉樹的 SortedSet<char>,說明這里的瓶頸在于平衡二叉樹,性能還是比不上哈希表的,
優化的基于樹狀位壓縮陣列的字符集合
第一條路走不通,只好再回來優化 CharSet 了,字符范圍操作的性能不理想,原因在于需要對字符范圍做遍歷,越大的字符范圍,這里的消耗就越大,
如何避免這里的遍歷行為?可以同樣利用位操作來進行批量操作,例如,需要將 \x05 到 \x32 范圍內的所有位置置 1,可以直接通過 $(1 << 32) << 2 - (1 << 5)$ 計算出位掩碼,再通過或操作實作置 1,
如果操作涉及到了陣列內的多個位置,也是同樣的操作,這樣字符的遍歷次數可以減少到原先的 1/64(將 ulong 作為存盤單位),即使是完整 char 范圍的操作,也只需要 1024 次操作,
同時,之前允許將 CharSet 第二層陣列設定為 null 來表示陣列范圍的所有位置都是 0,那么可以考慮通過將第二層陣列設定為 [] 來表示陣列范圍的所有值都是 1,就可以快速處理一些長度大于 1024(第二層陣列可以容納的字符數)的連續的 0 或 1,這樣最大回圈次數可以進一步減少到不超過 100,
在應用以上兩類優化后,CharSet 的判斷邏輯更為復雜,單字符操作和查找操作性能都有下降;集合操作性能基本持平;范圍操作性能得到了極大提升,
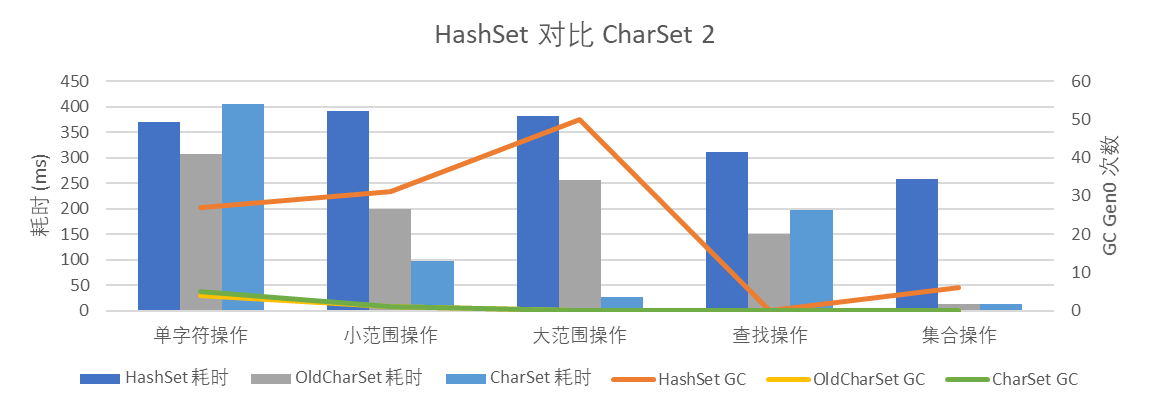
圖 4 HashSet 對比 CharSet 2
新的 CharSet 減少了大范圍連續 1 場景的記憶體消耗,也利用 ArrayPool 實作記憶體復用,整體對記憶體更為友好,
以前面提到的寬字符范圍為例:
- 字符范圍包含 42274 個字符,按
char[]存盤需要 82.6KB, CharSet只會包含 16 個底層陣列,其他部分由于全為0或1而沒有額外的記憶體消耗,總記憶體消耗約為 2.5KB,RangeCharSet包含 45 個 AVL 節點,總記憶體消耗約為 1.4KB,- 按只包含字符范圍起止的
char[],需要 180B,這樣的壓縮表示下,二分查找進行匹配的性能略高于RangeCharSet,約為CharSet的 2.5 倍,只適合包含少量字符范圍的簡單的場景,
總的來說,CharSet 在提供高性能的同時并不需要消耗過多記憶體,可以完全取代任何用到 HashSet<char> 的場景,只有在極限優化記憶體的只讀場景,才需要考慮是否使用只包含字符范圍起止的 char[] 來代替,
CharSet 的所有代碼可以在這里找到,
作者:CYJB
出處:http://www.cnblogs.com/cyjb/
GitHub:https://github.com/CYJB/
本文著作權歸作者和博客園共有,歡迎轉載,但未經作者同意必須保留此段宣告,且在文章頁面明顯位置給出原文連接,否則保留追究法律責任的權利,
轉載請註明出處,本文鏈接:https://www.uj5u.com/net/464934.html
標籤:C#