我有一個如下所示的資料集:
val df = Seq("samb id 12", "car id 13", "lxu id 88").toDF("list")
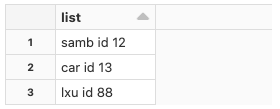
我想創建一個列,該列將是一個僅包含 Id 之后的值的字串。結果將是這樣的:
val df_result = Seq(("samb id 12",12), ("car id 13",13), ("lxu id 88",88)).toDF("list", "id_value")

為此,我正在嘗試使用substring. 對于提取子字串的起始位置的引數,我正在嘗試使用定位。但它給了我一個錯誤,說它應該是 Int 而不是列型別。
我正在嘗試的是:
df
.withColumn("id_value", substring($"list", locate("id", $"list") 2, 2))
我得到的錯誤是:
error: type mismatch;
found : org.apache.spark.sql.Column
required: Int
.withColumn("id_value", substring($"list", locate("id", $"list") 2, 2))
^
如何解決此問題并繼續使用 locate() 作為引數?
更新 更新以舉一個例子,其中@wBob 答案不適用于我的真實世界資料:我的資料確實比上面的例子復雜一點。
它是這樣的:
val df = Seq(":option car, lorem :ipsum: :ison, ID R21234, llor ip", "lst ID X49329xas ipsum :ion: ip_s-")

這些值是很長的字串,沒有特定的模式。
在字串中的某個地方,它始終是部分寫入的ID XXXXX。XXXXX 有所不同,但總是相同的大小(5 個字符)并且總是在ID .
在這種模式下,我既不能使用也split不能regexp_extract得到一些東西。
uj5u.com熱心網友回復:
目前尚不清楚您是否想要串列中的第三個專案或第一個數字,但這里有幾個示例應該會有所幫助:
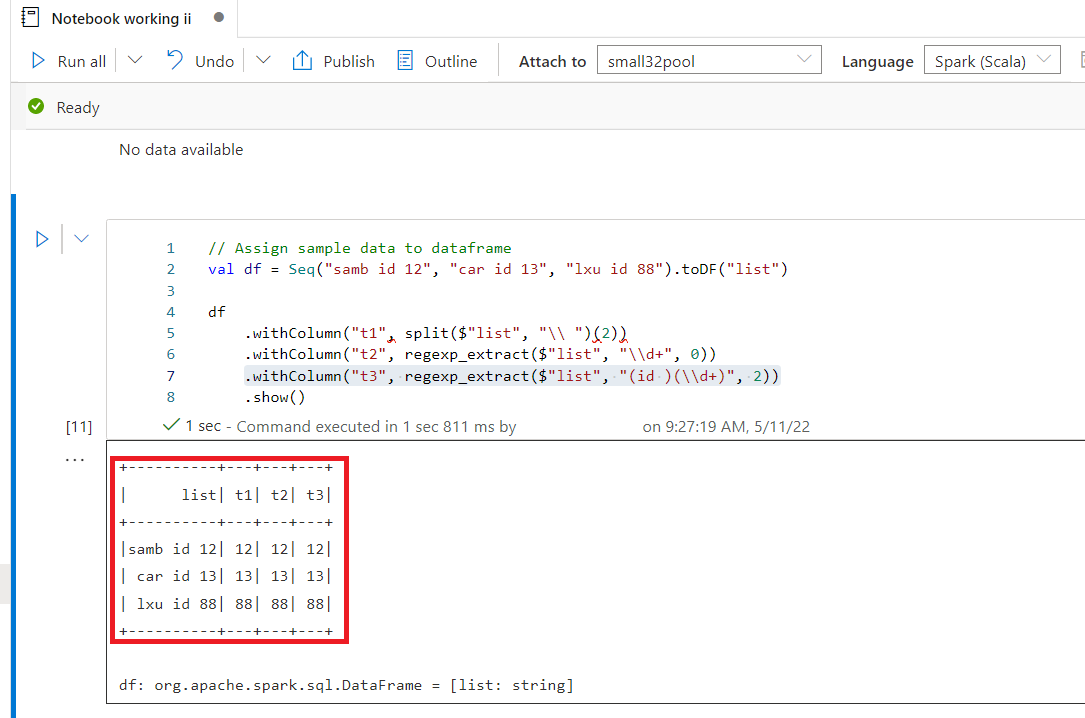
// Assign sample data to dataframe
val df = Seq("samb id 12", "car id 13", "lxu id 88").toDF("list")
df
.withColumn("t1", split($"list", "\\ ")(2))
.withColumn("t2", regexp_extract($"list", "\\d ", 0))
.withColumn("t3", regexp_extract($"list", "(id )(\\d )", 2))
.withColumn("t4", regexp_extract($"list", "ID [A-Z](\\d{5})", 1))
.show()
您可以使用split和regexp_extractwith之類的函式withColumn根據現有值創建新列。 split根據您傳入的分隔符將串列拆分為一個陣列。我在這里使用了空間,用兩個斜杠轉義來拆分陣列。該陣列是從零開始的,因此指定2獲取陣列中的第三項。 regexp_extract使用正則運算式從字串中提取。在這里,我使用\\d了 which 代表數字并且 與數字 1 或多次匹配。第三列 ,t3再次使用regexp_extract類似的 RegEx 運算式,但使用括號對部分進行分組并2從 regex 中獲取第二組,即(\\d ). 注意我在正則運算式中使用了額外的斜杠來轉義\d.
我的結果:
如果您的真實資料更復雜,請發布一些此代碼不起作用的簡單示例并解釋原因。
轉載請註明出處,本文鏈接:https://www.uj5u.com/net/477950.html
標籤:斯卡拉 阿帕奇火花 apache-spark-sql 数据块
下一篇:PHPAPI主檔案