嘿,網路人,
我有一個正在創建“ show_monthly_temp ”的函式,我試圖在其中繪制一個帶有 12 個散點圖的圖形,其中每個子圖的目的在下一行中提到。
功能
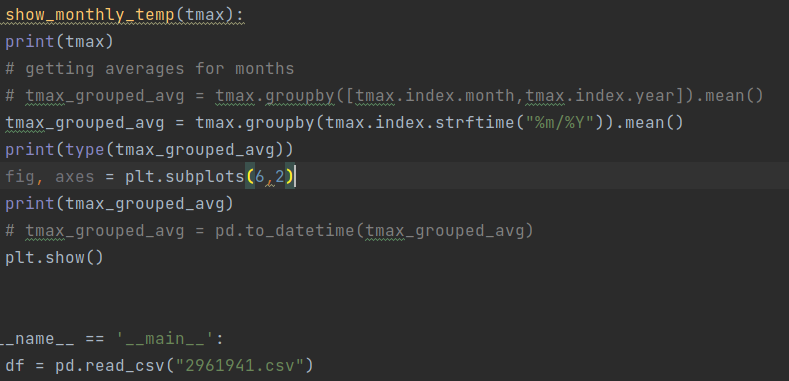
它列印以下內容(DATE 是一個日期時間物件):
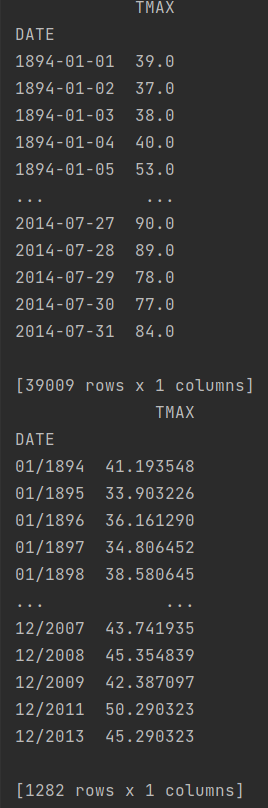
現在,我嘗試做的(未成功)是繪制 12 個子圖,代表采樣年份中一年中每個月的平均值。
關于我如何做到這一點的任何想法?
只是為了強調我的目標:
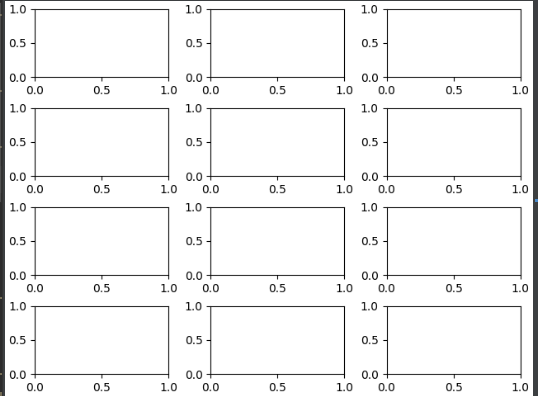
每個子圖是一個月,其中 Y 代表測量年份的溫度,X 代表樣本年份。
謝謝!:-)
完整代碼在這里:
import pandas as pd
from datetime import datetime
import numpy as np
import scipy as stats
import matplotlib.pyplot as plt
def show_monthly_temp(tmax):
print(tmax)
# getting averages for months
# tmax_grouped_avg = tmax.groupby([tmax.index.month,tmax.index.year]).mean()
tmax_grouped_avg = tmax.groupby(tmax.index.strftime("%m/%Y")).mean()
print(type(tmax_grouped_avg))
fig, axes = plt.subplots(6,2)
print(tmax_grouped_avg)
# tmax_grouped_avg = pd.to_datetime(tmax_grouped_avg)
plt.show()
if __name__ == '__main__':
df = pd.read_csv("2961941.csv")
# set date column as index, drop the 'DATE' column to avoid repititions create as datetime object
# speed up parsing using infer_datetime_format=True.
df.index = pd.to_datetime(df['DATE'], infer_datetime_format=True)
# create new tables
tmax = df.filter(['TMAX'], axis=1).dropna()
snow = df.filter(['SNOW']).dropna()
# count number of snow day samples - make sure at least >= 28
snow_grouped = snow.groupby(pd.Grouper(level='DATE', freq="M")).transform('count')
snow = (snow[snow_grouped['SNOW'] >= 28])
# count number of tmax day samples - make sure at least >= 28
tmax_grouped = tmax.groupby(pd.Grouper(level='DATE', freq="M")).transform('count')
tmax = (tmax[tmax_grouped['TMAX'] >= 28])
################ Until here - initialized data ###############
show_monthly_temp(tmax)
uj5u.com熱心網友回復:
如果我理解正確,你可以這樣做:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import calendar
# Fake data - generating 'tmax_grouped_avg'.
df = pd.DataFrame({'Date': pd.date_range('1990-10-01', '2023-05-01')})
df['TMAX'] = np.random.random((len(df)))*30
tmax_grouped_avg = df.groupby(df['Date'].dt.strftime('%m/%Y')).mean()
# New code here.
tmax_grouped_avg['datetime'] = pd.to_datetime(tmax_grouped_avg.index)
tmax_grouped_avg['Year'] = tmax_grouped_avg['datetime'].dt.year
groups = tmax_grouped_avg.groupby(tmax_grouped_avg['datetime'].dt.month)
f, axes = plt.subplots(nrows=3, ncols=4, figsize=(12, 6))
for (grp_id, grp_df), ax in zip(groups, axes.ravel()):
# Check if you want sharex and sharey.
grp_df.plot.scatter(ax=ax, x='Year', y='TMAX', title=f'{calendar.month_name[grp_id]}', legend=False,
sharey=True, sharex=True)
plt.suptitle('Maximum temperature for each month')
plt.tight_layout()
plt.show()
結果:
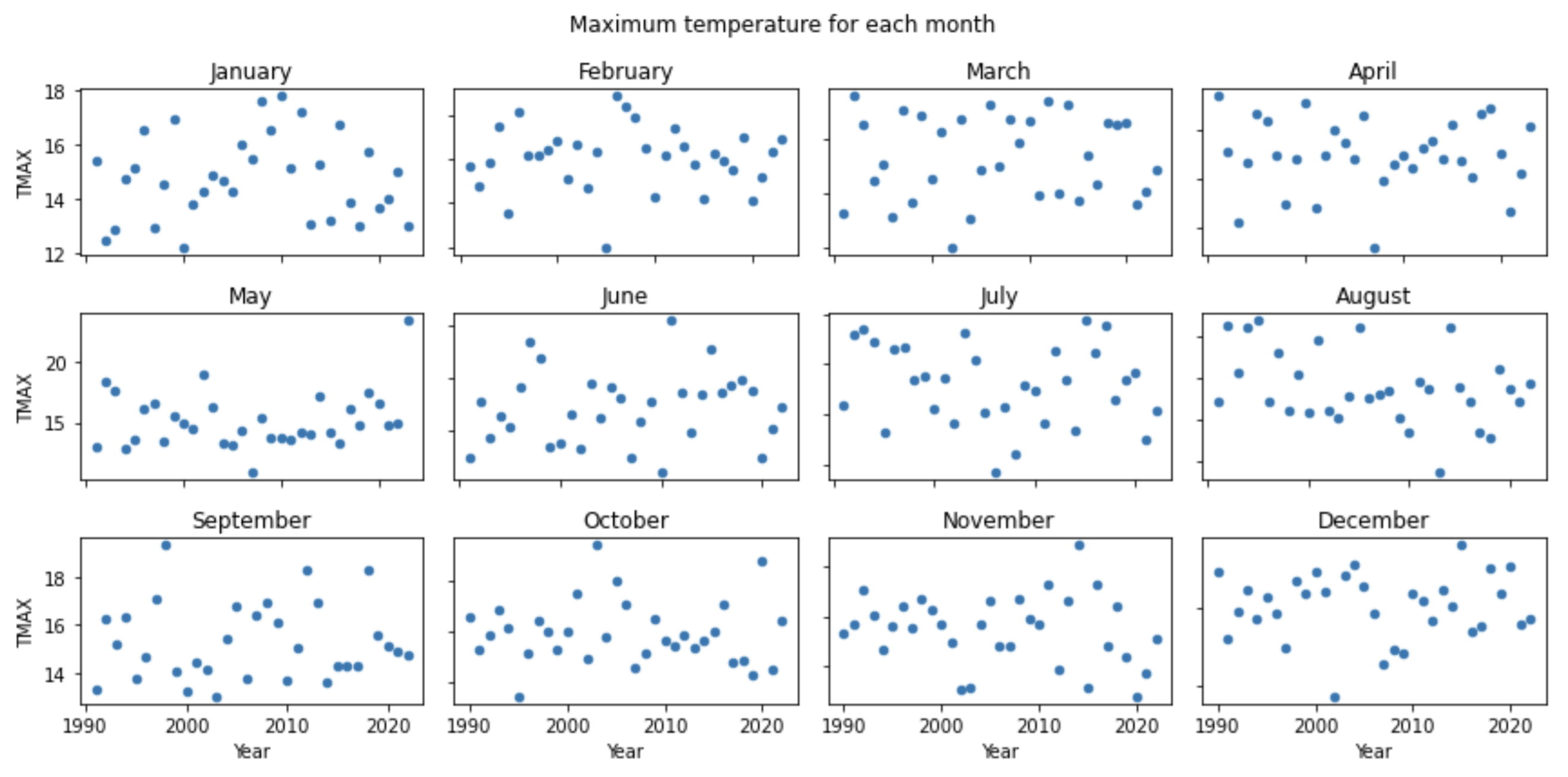
轉載請註明出處,本文鏈接:https://www.uj5u.com/net/478261.html
標籤:Python 熊猫 数据框 matplotlib
上一篇:在圖上標記點