driver = webdriver.Chrome()
URL= ['https://makemyhomevn.com/collections/ghe-an-cafe/products/ghe-go-tron']
driver.get(URL)
sleep(1)
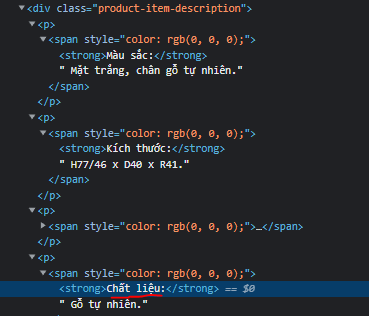
des = driver.find_element_by_xpath('//div[@class="product-item-description"]//strong/following sibling::text()[1]')
print(des)
我希望我的結果是 'G? t? nhiên',我嘗試了很多方法,但在 'Ch?t li?u:' 之后無法獲得文本。
uj5u.com熱心網友回復:
您可以使用整個跨度文本.get_attribute('innerText'),然后使用以下內容split function from Python:
driver.maximize_window()
wait = WebDriverWait(driver, 20)
driver.get("https://makemyhomevn.com/collections/ghe-an-cafe/products/ghe-go-tron")
time.sleep(1)
entire_span = wait.until(EC.visibility_of_element_located((By.XPATH, "//strong[text()='Ch?t li?u:']/..")))
entire_span_splitted = entire_span.get_attribute('innerText').split(":")
#print(entire_span_splitted[0])
print(entire_span_splitted[1])
進口:
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
輸出:
G? t? nhiên.
轉載請註明出處,本文鏈接:https://www.uj5u.com/net/480836.html