我有一個向量ranks,其值從 -6 到 6,我想根據值區間(例如 (2, Inf) [2, 1.25) 等包括該區間中的值數量,以及上一個間隔中的那些。換句話說,對于值的區間 (2, Inf) 我想獲得這個區間中的值加上前一個區間中的值的數量。
為此,我使用了一種非常原始的方法:
xmin <- c(0, sum(ranks>2),
sum(ranks>2) sum(ranks>1.25),
sum(ranks>2) sum(ranks>1.25) sum(ranks>0.75),
sum(ranks>2) sum(ranks>1.25) sum(ranks>0.5) sum(ranks>0.25))
xmax <- c(c(sum(ranks>2),
sum(ranks>2) sum(ranks>1.25),
sum(ranks>2) sum(ranks>1.25) sum(ranks>0.75),
sum(ranks>2) sum(ranks>1.25) sum(ranks>0.5) sum(ranks>0.25))-1,
length(ranks))
其中 xmin 是每個間隔的開始,xmax 是每個間隔的結束。但我相信有一種更好的直接方法可以做到這一點。
總的來說,我想找到在這個間隔中分開的值: Inf、2、1、0.5、0、-0.5、-1、-2、-Inf
PS:我將使用這些來注釋 ggplot2 中的 x 軸,如下所示(參見從紅色到藍色的色標,這些是具有特定 x 和 y 分隔符的矩形)

uj5u.com熱心網友回復:
嘗試這個:
c(1, 1, 2, 3, 2, 1, 4, 2, 5, 6, 2, 5, 3) %>%
cut(c(0, 2, 4, 6)) %>%
table() %>%
cumsum()
(0,2] (2,4] (4,6]
7 10 13
UPD:剛剛注意到 - 你正在反向安排你的間隔。我認為最簡單的方法是將表格轉換為數字并在ingrev之前將其 ersecumsum
uj5u.com熱心網友回復:
我可能仍然誤解了,但最后只是計算每個區間有多少個基因,對嗎?
基本上你是在重新發明一個堆疊條。
library(ggplot2)
# random data
set.seed(1)
rank <- sample(-6:6, 11000, replace = T)
# vector of your cuts
my_cuts <- c(-Inf, -2, -1, -0.5, 0, 0.5, 1, 2, Inf)
## make a data frame and cut the ranks
genes <- data.frame(rank)
genes$cuts <- cut(genes$rank, my_cuts)
## just use geom_bar
ggplot(genes)
geom_bar(aes(y = 1, fill = cuts))
## now you can simply use one of the scale functions
scale_fill_brewer(palette = "Reds")
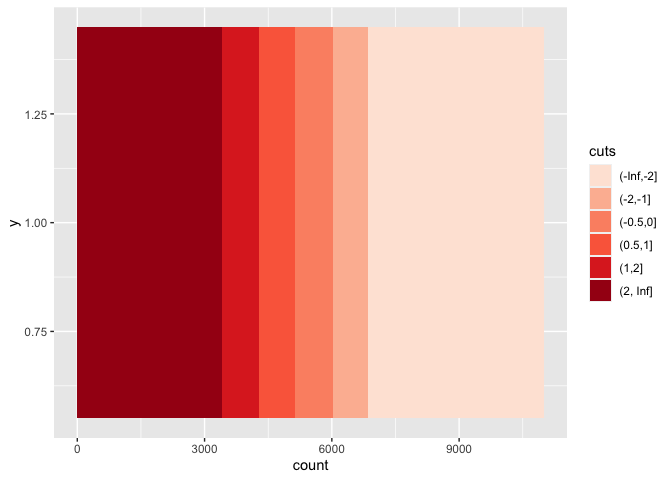
由reprex 包于 2022-05-31 創建(v2.0.1)
轉載請註明出處,本文鏈接:https://www.uj5u.com/net/483764.html
下一篇:編輯邊際效應圖中置信區間的外觀