盡管設法用假資料繪制了一個多斜率圖(參見下面的可重現示例),但我在設法使代碼適應我的真實資料時遇到了麻煩,并且由于密鑰冗余而不斷面臨錯誤。
首先,一些背景關系:我有一個包含許多“_x”和“_y”變數的資料集,它們是時間 1 和 2 的測量值 - 記錄在一個列中,因為每個條目都有一個 time1 和一個 time2- 我想繪制我的每個人的斜率,為每個變數(變數對)繪制一個圖。
在以下可重現的示例中,我已經設法 - 在一些幫助下 - 為一組變數執行此操作,沒有“_x”或“_y”列名。然而,當我嘗試使用選擇來調整此代碼時 - 為了只采用這些列而不是所有資料集 - 更改 colnames 以模仿示例,更改正則運算式等等等。我一直面臨鍵冗余錯誤。
“錯誤
spread():
!每行輸出必須由唯一的鍵組合標識。
鍵共享 195 行:”
我懷疑這是因為我的資料中確實有一些相同的值,但是對于列 ID,它不應該是一個問題,我不太明白我能做些什么來解決它。
foo 示例:
library(tidyverse)
Id <- rep(1:10)
a = c(5,10,15,12,13,25,12,13,11,9)
b = c(8,14,20,13,19,29,15,19,20,11)
c = c(10,14,20,1.5,9,21,13,21,11,10)
d = c(15,9,20,14,12,5,12,13,12,30)
group = as.factor( rep(1:2,each=5) )
data = data.frame(Id,a,b,c,d,group)
case_mapping <- data.frame(
key = c("a", "b", "c", "d"),
key2 = c("x1", "x2", "y1", "y2")
)
data %>%
gather(key, val, c(a:d)) %>%
left_join(case_mapping, by = "key") %>%
select(-key) %>%
extract(key2, into = c("key", "order"), "([a-z])([0-9])") %>%
spread(key, val) %>%
ggplot()
aes(x, y, group = Id, color = group) xlab("Age") #ggtitle(paste("Variable")
geom_point()
geom_line()
現在是我的資料示例。
library(tidyverse)
Id <- rep(1:10)
var1_x = c(5,10,15,12,13,25,12,13,11,9)
var2_x = c(8,14,20,13,19,29,NA,19,20,11) # just adding some nas.
var3_x = c(10,14,20,1.5,9,21,13,21,11,10)
var1_y = var1_x 3
var2_y = var2_x*2
var3_y = c(10,14,20,1.5,9,21,13,21,11,10) #same, just to see.
age1 = c(15,9,20,14,12,5,12,13,12,30)
age2 = c(18,19,24,16,15,9,16,19,14,37)
group = as.factor( rep(1:2,each=5) )
data = data.frame(Id,var1_x,var2_x,var3_x, var1_y,var2_y,var3_y,age1,age2,group)
現在,我是否應該創建一個 for 回圈,以便正確配對變數。首先,我們創建兩個字串,名稱分別為 _x 和 _y
sub_x = colnames(data)[2:4] # sub x
sub_y = colnames(data)[5:7] # suby
現在我們應該能夠實作 for 回圈了。
for( i in 1:length(sub_x)) {
# We define the matching keys.
case_mapping <- data.frame(
key = c(sub_x[i],sub_y[i], "age1", "age2"),
key2 = c("x1", "x2", "y1", "y2")
)
# And now we should be able to plot this.
data %>%
gather(key, val, c(!!sym(sub_x[i]), !!sym(sub_y[i]), age1,age2 )) %>%
left_join(case_mapping, by = "key") %>%
select(-key) %>%
extract(key2, into = c("key", "order"), "([a-z])([0-9])") %>%
spread(key, val) %>%
ggplot()
aes(x, y, group = Id, color = group)
xlab("Age")
geom_point()
geom_line()
}
然而,這并沒有給我任何結果,當我嘗試調整它時,它會由于聚集而引發錯誤。我希望你能啟發我,以了解我做錯了什么。
PD:對不起,如果我的語法不完全正確,但英語是我的第二語言。
編輯以澄清:
我打算為每個變數繪制類似的東西 - 如果有一種方法可以指示每個斜率的 ID,那會非常好,所以我不必從資料中查找它來查看它們對應的)
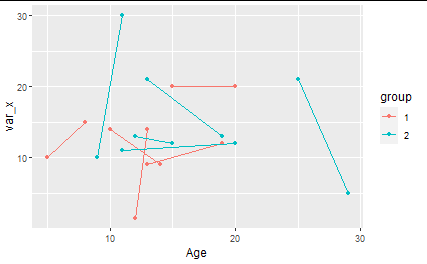
編輯 2 在 Tjebo 的幫助下,我有點“解決它”,但我仍然需要通過 dplyr 自動化從提供的 data_long1 構建這個 data_long2 。
data_long2 <- data.frame( Id = rep(data_long$Id,2), Group = rep(data_long$group,2), Var= rep(data_long$var,2) , Valueage= c(data_long$age1,data_long$age2), Valuevar= c(data_long$x,data_long$y) )
ggplot(data_long2)
## I've removed the grouping by ID, because there was only one observation per ID
aes(Valueage, Valuevar, color=Id)
geom_point()
geom_line(aes(group = Id))
# geom_line()
## you can for example facet by your new variable column
facet_grid(~Var)
#> Warning: Removed 1 rows containing missing values (geom_point).
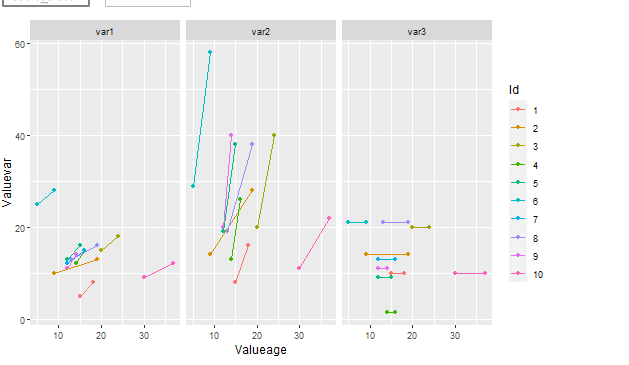
并將顏色更改為組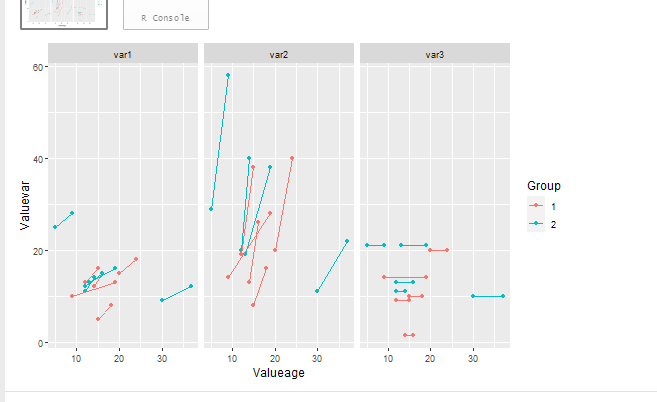
uj5u.com熱心網友回復:
我想你可能把事情復雜化了。據我了解,您很難重塑資料然后繪制所有變數,對嗎?
下面的一種方法利用新的 pivot_longer 進行重塑(它具有驚人的功能,尤其是在“多個聚會”方面),然后是刻面而不是回圈。
更新
您基本上需要旋轉更長的時間兩次
library(tidyverse)
Id <- rep(1:10)
var1_x = c(5,10,15,12,13,25,12,13,11,9)
var2_x = c(8,14,20,13,19,29,NA,19,20,11) # just adding some nas.
var3_x = c(10,14,20,1.5,9,21,13,21,11,10)
var1_y = var1_x 3
var2_y = var2_x*2
var3_y = c(10,14,20,1.5,9,21,13,21,11,10) #same, just to see.
age1 = c(15,9,20,14,12,5,12,13,12,30)
age2 = c(18,19,24,16,15,9,16,19,14,37)
group = as.factor( rep(1:2,each=5) )
data = data.frame(Id,var1_x,var2_x,var3_x, var1_y,var2_y,var3_y,age1,age2,group)
data_long <-
data %>%
## make use of the cool pivot_longer function
pivot_longer(cols = matches("_[x|y]"),
names_to = c("var", ".value"),
names_pattern = "(.*)_(.*)") %>%
## now make even longer! all y (currently confusingly called x and y) belong into one column
## and all x (currently called age1 and age2) in another column
## this is easier with a similar pattern in both, therefore renaming
## note the .value name is switched when compared with the first pivoting
rename(y1= x, y2 = y) %>%
pivot_longer(
matches(".*([1-2])"),
names_to = c(".value", "set"),
names_pattern = "(. )([0-9 ])"
)
ggplot(data_long)
## I've removed the grouping by ID, because there was only one observation per ID
aes(age, y, color = as.character(Id))
geom_point()
geom_line()
## you can for example facet by your new variable column
facet_grid(~var)
#> Warning: Removed 2 rows containing missing values (geom_point).
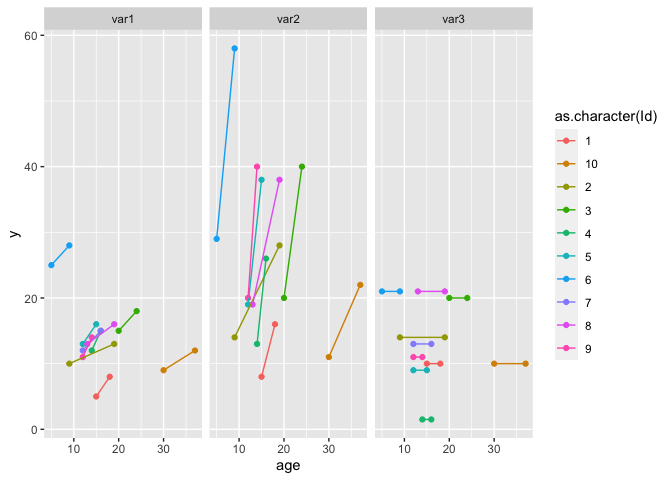
要在回圈中分別創建每個圖:
## split by your new variable and run a loop to create a list of plots
ls_p <- lapply(split(data_long, data_long$var), function(.x){
ggplot(.x)
## I've removed the grouping by ID, because there was only one observation per ID
aes(age, y, color = as.character(Id))
geom_point()
geom_line()
## you can for example facet by your new variable column
facet_grid(~var)
} )
## you can then either print them separately or all together, e.g. with patchwork
patchwork::wrap_plots(ls_p) patchwork::plot_layout(ncol = 1)
#> Warning: Removed 2 rows containing missing values (geom_point).
#> Warning: Removed 2 row(s) containing missing values (geom_path).
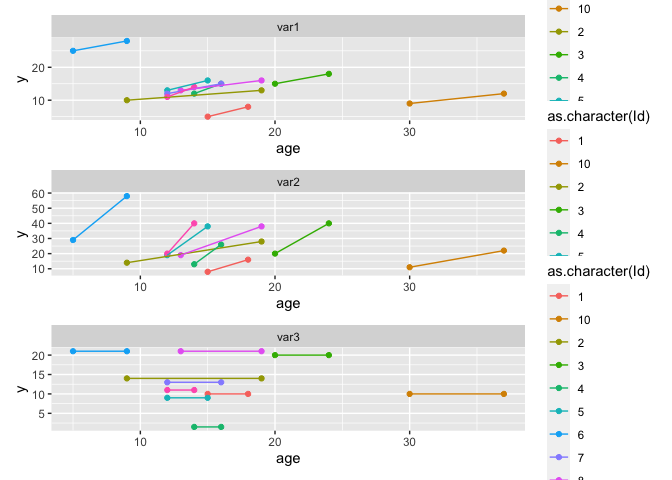
由reprex 包于 2022-05-31 創建(v2.0.1)
轉載請註明出處,本文鏈接:https://www.uj5u.com/net/483768.html