以下代碼檢查部分匹配并添加注釋以判斷部分匹配是否存在(效果很好!):
import pandas as pd
import numpy as np
x = {'Non-Suffix' : ['1234569', '1234554', '1234567', '1234568','Hello'], 'Suffix' : ['1234567:C', '1234568:VXCF', 'ABCDEFU', '1234569-01', '1234554-01:XC']}
x = pd.DataFrame({k: pd.Series(v) for k, v in x.items()})
x['"Non-Suffix" Partial Match in "Suffix"?'] = x['Non-Suffix'].apply(lambda v: x['Suffix'].str.contains(v).any()).replace({True: '--'}).replace({False: 'Add to Suffix'}).replace({np.nan: '--'})
x['"Suffix" Partial Match in "Non-Suffix"?'] = x['Suffix'].str.contains('|'.join(x['Non-Suffix'])).replace({True: '--'}).replace({False: 'Remove from Suffix'}).replace({np.nan: '--'})
x
#code breaks if anything is added to 'Suffix' column

但是,在實踐中,并不總是比較相同長度的列。事實上,大多數時候,會比較不同長度的列。如果我向Non-Suffix列 ( 'StackOverflowIsAwesome') 添加一個值,則代碼會中斷:
x = {'Non-Suffix' : ['1234569', '1234554', '1234567', '1234568','Hello'], 'Suffix' : ['1234567:C', '1234568:VXCF', 'ABCDEFU', '1234569-01', '1234554-01:XC','HelloAdele']}
x = pd.DataFrame({k: pd.Series(v) for k, v in x.items()})
x['"Non-Suffix" Partial Match in "Suffix"?'] = x['Non-Suffix'].apply(lambda v: x['Suffix'].str.contains(v).any()).replace({True: '--'}).replace({False: 'Add to Suffix'}).replace({np.nan: '--'})
x['"Suffix" Partial Match in "Non-Suffix"?'] = x['Suffix'].str.contains('|'.join(x['Non-Suffix'])).replace({True: '--'}).replace({False: 'Remove from Suffix'}).replace({np.nan: '--'})
x
#code breaks if anything is added to 'Suffix' column
這是確認列之間不同長度的錯誤:
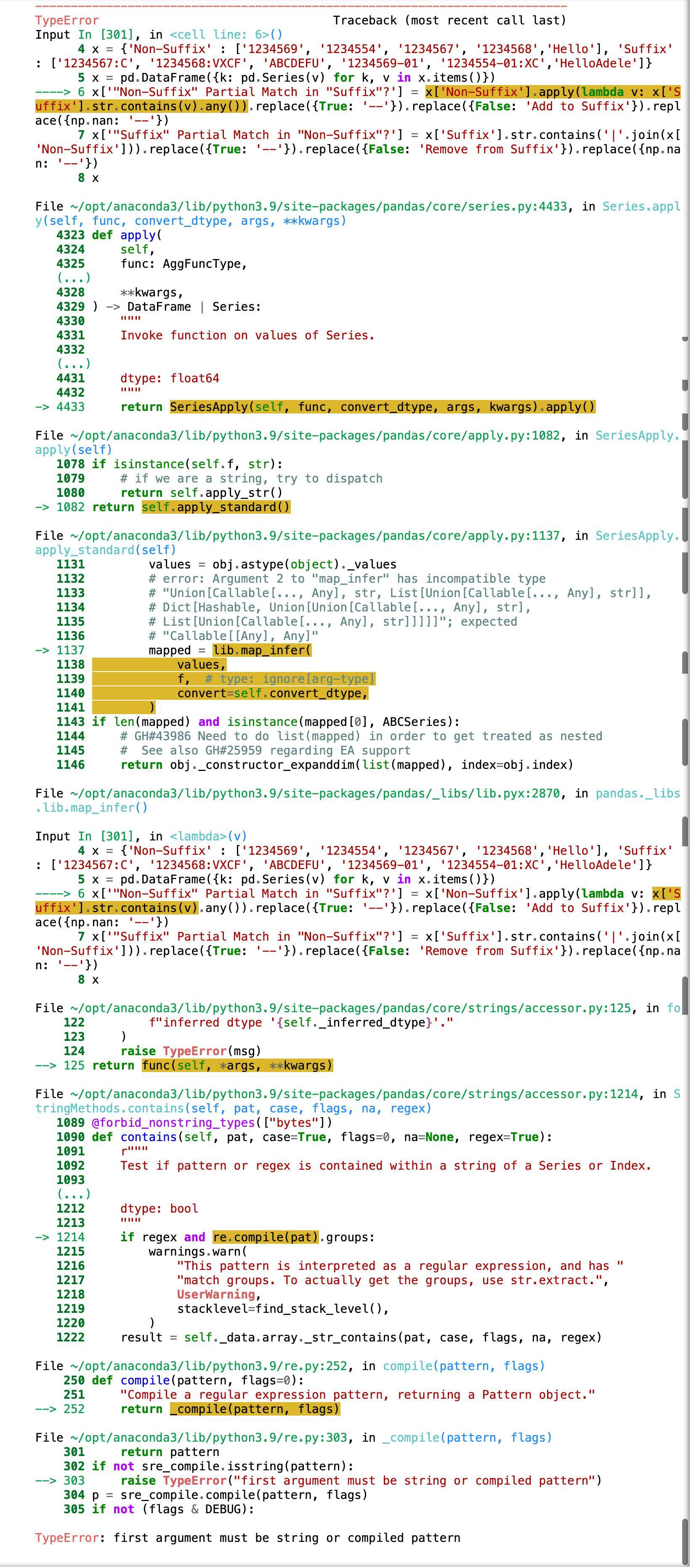
我希望能夠添加一些東西(比如'HelloAdele'在Suffix列中并且沒有代碼中斷。注意:我可以向Non-Suffix列添加值,但不能向Suffix列添加值。非常感謝任何關于如何克服這個問題的提示!
uj5u.com熱心網友回復:
更新以確保Non-Suffix列中的 NaN 不會導致“添加到后綴”值。
我認為這樣的事情應該有效:
import pandas as pd
import numpy as np
x = {'Non-Suffix' : ['1234569', '1234554', '1234567', '1234568','Hello'], 'Suffix' : ['1234567:C', '1234568:VXCF', 'ABCDEFU', '1234569-01', '1234554-01:XC','HelloAdele']}
x = pd.DataFrame({k: pd.Series(v) for k, v in x.items()})
print()
print(x)
x['"Non-Suffix" Partial Match in "Suffix"?'] = x['Non-Suffix'].apply(
lambda v: np.nan if v is np.nan else x['Suffix'].str.contains(v).any()).replace({True: '--'}).replace({False: 'Add to Suffix'}).replace({np.nan: '--'})
x['"Suffix" Partial Match in "Non-Suffix"?'] = x['Suffix'].str.contains('|'.join(
y for y in x['Non-Suffix'] if y is not np.nan)).replace({True: '--'}).replace({False: 'Remove from Suffix'}).replace({np.nan: '--'})
print(x)
我們基本上是特殊情況下的 NaNNon-Suffix并將結果設定為 np.nan (后來被“--”替換),并且在Suffix構建要匹配的模式時我們跳過 NaN。
輸入:
Non-Suffix Suffix
0 1234569 1234567:C
1 1234554 1234568:VXCF
2 1234567 ABCDEFU
3 1234568 1234569-01
4 Hello 1234554-01:XC
5 NaN HelloAdele
輸出:
Non-Suffix Suffix "Non-Suffix" Partial Match in "Suffix"? "Suffix" Partial Match in "Non-Suffix"?
0 1234569 1234567:C -- --
1 1234554 1234568:VXCF -- --
2 1234567 ABCDEFU -- Remove from Suffix
3 1234568 1234569-01 -- --
4 Hello 1234554-01:XC -- --
5 NaN HelloAdele -- --
轉載請註明出處,本文鏈接:https://www.uj5u.com/net/484226.html
上一篇:Python部分匹配的資料幀差異