我正在嘗試根據 ID 和年份標記行,如果 ID 出現在 [2017,2018,2019] 年份并且沒有出現在 [2020,2021,2022] 中,則需要將其標記為 1 else 0。
df1 = pd.DataFrame({'ID': ['AX1', 'Ax1', 'AX1','AX1','AX1','AX1','AX2','AX2','AX2','AX3','AX3','AX4','AX4','AX4'],'year':[2017,2018,2019,2020,2021,2022,2019,2020,2022,2019,2020,2017,2018,2019]})
ID year
0 AX1 2017
1 Ax1 2018
2 AX1 2019
3 AX1 2020
4 AX1 2021
5 AX1 2022
6 AX2 2019
7 AX2 2020
8 AX2 2022
9 AX3 2019
10 AX3 2020
11 AX4 2017
12 AX4 2018
13 AX4 2019
預期輸出:
ID year label
0 AX1 2017 0
1 Ax1 2018 0
2 AX1 2019 0
3 AX1 2020 0
4 AX1 2021 0
5 AX1 2022 0
6 AX2 2019 0
7 AX2 2020 0
8 AX2 2022 0
9 AX3 2019 0
10 AX3 2020 0
11 AX4 2017 1
12 AX4 2018 1
13 AX4 2019 1
在上面的示例中 ID:AX4 被標記為 1,因為它是唯一出現在第一組年份 [2017,2018,2019] 而沒有出現在第二組年份 [2020,2021,2022] 中的 ID。
我如何實作這一目標?
uj5u.com熱心網友回復:
利用
df1 = pd.DataFrame({'ID': ['AX1', 'AX1', 'AX1','AX1','AX1','AX1','AX2','AX2','AX2','AX3','AX3','AX4','AX4','AX4'],'year':[2017,2018,2019,2020,2021,2022,2019,2020,2022,2019,2020,2017,2018,2019]})
# find group level labels by checking if all of 2017-19 and none of 2020-22 exist for each ID
gr_lbl = df1.groupby('ID')['year'].apply(lambda g: {2017,2018,2019}.issubset(g) and not bool({2020,2021,2022}.intersection(g)))*1
# map group level labels to ID
df1['labels'] = df1.ID.map(gr_lbl)
df1
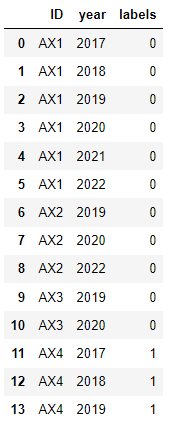
uj5u.com熱心網友回復:
import pandas as pd
df1 = pd.DataFrame({'ID': ['AX1', 'Ax1', 'AX1','AX1','AX1','AX1','AX2','AX2','AX2','AX3','AX3','AX4','AX4','AX4'],'year':[2017,2018,2019,2020,2021,2022,2019,2020,2022,2019,2020,2017,2018,2019]})
include = set()
exclude = set()
for ID, year in zip(df1['ID'], df1['year']):
if year in [2017,2018,2019]:
include.add(ID.upper())
if year in [2020,2021,2022]:
exclude.add(ID.upper())
df1['label'] = [int(x.upper() in include - exclude) for x in df1['ID']]
print(df1)
uj5u.com熱心網友回復:
Series通過聚合s創建set,然后通過比較它set.issubset,最后將輸出映射到新列:
y1 = set([2017,2018,2019])
y2 = set([2020,2021,2022])
s = df1.groupby('ID')['year'].agg(set)
df1['label'] = df1['ID'].map((s.map(y1.issubset) & ~s.map(y2.issubset)).astype(int))
print (df1)
ID year label
0 AX1 2017 0
1 Ax1 2018 0
2 AX1 2019 0
3 AX1 2020 0
4 AX1 2021 0
5 AX1 2022 0
6 AX2 2019 0
7 AX2 2020 0
8 AX2 2022 0
9 AX3 2019 0
10 AX3 2020 0
11 AX4 2017 1
12 AX4 2018 1
13 AX4 2019 1
詳情:
print (df1.groupby('ID')['year'].agg(set))
ID
AX1 {2017, 2019, 2020, 2021, 2022}
AX2 {2019, 2020, 2022}
AX3 {2019, 2020}
AX4 {2017, 2018, 2019}
Ax1 {2018}
Name: year, dtype: object()
print ((s.map(y1.issubset) & ~s.map(y2.issubset)).astype(int))
ID
AX1 0
AX2 0
AX3 0
AX4 1
Ax1 0
Name: year, dtype: int32
轉載請註明出處,本文鏈接:https://www.uj5u.com/net/484916.html
標籤:Python python-3.x 熊猫 数据框
下一篇:在r中將列分成多列時丟失資料