我有一串鍵值對,我想將其拆分為 Python 中的字典。在此處的其他一些問題的幫助下,我已經能夠將一些正則運算式放在一起以在一個級別上實作這一目標:
(\S ?):(. ?),
但是,我遇到的一個問題是我想支持子對,例如,我有這個字串:
document-name:string,document-type:string,description:string,initiative-name:string,milestone:struct<key:string,name:string>,size:int
目前正在這樣拆分:
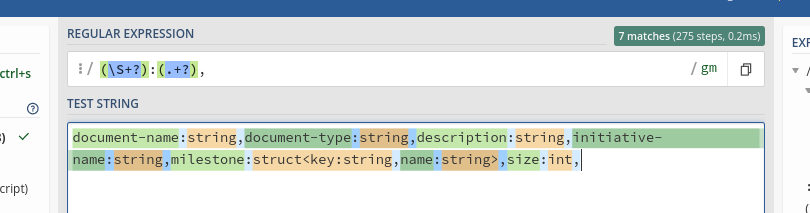
因此,正如您所看到的,它目前正在將“里程碑”對的值中間的逗號視為新對的開始。
我計劃在代碼級別使用遞回來處理這個拆分已經成功完成,因為可能有無限的深度。但是,當逗號被括號或類似的東西包裹時,有沒有辦法讓它忽略逗號?
謝謝!
uj5u.com熱心網友回復:
該re庫不支持正則運算式中的遞回,因此您必須匯入替代的正則運算式庫,或者您可以撰寫一個同時生成嵌套字典的決議器。此決議器仍將使用正則運算式,但只是對輸入進行標記。然后決議器可以使用自己的堆疊來應用和驗證嵌套。
該解決方案采用該路線:
import re
def parse(s):
regex = r"([^:<>,] ):(?:(struct)<|([^:<>,]*)(>*),?)|(\w |.)"
stack = []
d = {}
for match in re.finditer(regex, s):
key, opening, value, closing, invalid = match.group(1, 2, 3, 4, 5)
if opening:
d[key] = {}
stack.append(d)
d = d[key]
elif invalid:
raise ValueError(f"expected key:value, but found '{invalid}'")
elif not value:
raise ValueError(f"missing value after colon")
else:
d[key] = value
if closing:
if len(closing) > len(stack):
raise ValueError(f"too many '{closing}'")
d = stack[-len(closing)]
del stack[-len(closing):]
if stack:
raise ValueError("missing '>'")
return d
示例呼叫:
s = "document-name:string,document-type:string,description:string,initiative-name:string,milestone:struct<key:string,name:struct<s:string>>,size:int"
d = parse(s)
d將會:
{
'document-name': 'string',
'document-type': 'string',
'description': 'string',
'initiative-name': 'string',
'milestone': {
'key': 'string',
'name': {
's': 'string'
}
},
'size': 'int'
}
uj5u.com熱心網友回復:
據我了解,正則運算式應milestone作為鍵和struct<key:string,name:string>值匹配。如果是這樣,那么您可以使用
(\S ?):([^:]*?<.*>|. ?)(?:,|$)
查看正則運算式演示
由于上面的正則運算式不是您問題的最佳解決方案,我決定提供一個 Python 函式來將此類字串轉換為 Python dict。
import re
import json
def convert(string):
string = re.sub(r">", "}", string)
string = re.sub(r"(?<=:)(struct<)", "{", string)
string = re.sub(r"(^|,|{)(.*?)(?=:)", "\\1\"\\2\"", string)
string = re.sub(r"(:)([^{}]*?)(?=$|,|})", "\\1\"\\2\"", string)
return json.loads("{%s}" % string)
注意:這無需遞回即可正常作業,但可以正常作業
struct = "document-name:string,document-type:string,description:string,initiative-name:string,milestone:struct<foo:struct<a:bar,b:baz>,name:string>,milestone:struct<foo:struct<a:bar,b:baz>,name:string>,size:int"
print(convert(struct)) # {'document-name': 'string', 'document-type': 'string', 'description': 'string', 'initiative-name': 'string', 'milestone': {'foo': {'a': 'bar', 'b': 'baz'}, 'name': 'string'}, 'size': 'int'}
uj5u.com熱心網友回復:
如果要使用單個正則運算式捕獲單個鍵值對,則不能使用標準正則運算式,因為正則運算式不支持遞回結構。但是,您可以使用增加了對遞回的支持的正則運算式庫。
你的表達可能是這樣的:([^:<>,] ):(struct\<(?R) \>|[^:<> ] )(,|$|(?=>)). 分解:
([^:<>,] ):- 鍵和冒號(struct\<(?R) \>|[^:<> ] )- 值,或者:struct\<(?R) \>- 一個結構值((?R)表示庫中的“遞回”regex)- 或一個值,例如
"string"
(,|$|(?=>))- 結尾:必須是逗號、輸入結尾或字符前瞻>。
這是一個更完整的決議器(幾乎相同的正則運算式,但使用命名組):
import regex
pattern = regex.compile(
r"([^:<>,] ):(struct\<(?P<rec_value>(?R) )\>|(?P<value>[^:<> ] ))(,|$|(?=>))"
)
def parse(s):
return {
match[1]: parse(match["rec_value"]) if match["rec_value"] else match["value"]
for match in pattern.finditer(s)
}
print(
parse(
"document-name:string,document-type:string,description:string,initiative-name:string,milestone:struct<foo:struct<a:bar,b:baz>,name:string>,milestone:struct<foo:struct<a:bar,b:baz>,name:string>,size:int"
)
)
輸出:
{
"document-name": "string",
"document-type": "string",
"description": "string",
"initiative-name": "string",
"milestone": {"foo": {"a": "bar", "b": "baz"}, "name": "string"},
"size": "int"
}
請注意,這不會在格式錯誤的輸入上出錯,例如a:A,b::B,c:C,只會默默地忽略b::B錯誤。需要做更多的作業來捕捉這樣的錯誤。
轉載請註明出處,本文鏈接:https://www.uj5u.com/net/490569.html
下一篇:修改資料框串列的列