我希望制作一個線圖或散點圖(最好是 ggplot),它在 x 軸上有時間,在 y 軸上的二進制變數中有 1 的計數。這是我的資料。誰能幫我?
tweet_id text date morality_binary
1 Lorem ipsum... 2014-01-01 1
2 Lorem ipsum... 2015-01-01 0
3 Lorem ipsum... 2016-01-01 1
4 Lorem ipsum... 2017-01-01 0
5 Lorem ipsum... 2018-01-01 0
6 Lorem ipsum... 2019-01-01 1
這是實際資料的可重現示例:
df <- structure(list(X.1 = 0:5, X = c(502026L, 198322L, 711188L, 563672L,
993641L, 474508L), tweet_id = c(867481042428579840, 469268704732393536,
915248573083553792, 689948979740725248, 1003463365811953664,
958533305716101120), user_username = c("GerryConnolly", "SenatorMenendez",
"RepJayapal", "RoyBlunt", "SenJeffMerkley", "RepChrisStewart"
), text = c(".@governorva demonstrates compassion that potus lacks. trump's immigration eo still threatens to tear this family apart. #freeliliana",
"hoy,repet<ed> mi llamado a mis colegas rep. de la c<e1>mara para q hagan lo correcto y aprueben una #reformamigraotira #cir",
"@repadamsmith @reproybalallard the incarceration system for immigrants operates in the shadows, at a huge profit for corporations. our bill phases them out in 3 years.",
"now isn't the time to accept syrian & iraqi refugees into our country w/o proper system for vetting. rt if you agree",
"mr. president, the only <93>horrible law<94> is your policy. you have the power to change it. if you saw what i saw today, you would. never before has america deliberately inflicted cruelty on children to deter asylum seekers from finding refuge here. never. and we never should.",
"republicans and democrats need to work together and reform our immigration policies. #sotu"
), created_at = c("2017-05-24", "2014-05-22", "2017-10-03", "2016-01-20",
"2018-06-04", "2018-01-31"), user_name = c("Rep. Gerry Connolly",
"Senator Bob Menendez", "Rep. Pramila Jayapal", "Senator Roy Blunt",
"Senator Jeff Merkley", "Rep. Chris Stewart"), user_verified = c("True",
"True", "True", "True", "True", "True"), morality_binary = c(0.78794396,
0.06992793, 0.75065666, 0.7655833, 0.85510856, 0.52538866), morality = c(1,
0, 1, 1, 1, 1)), row.names = c(NA, 6L), class = "data.frame")
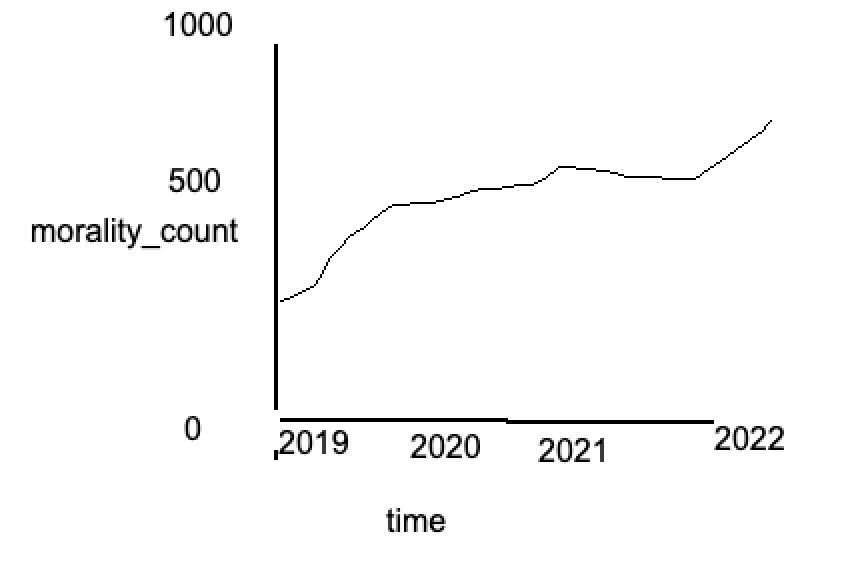
這就是我想要達到的
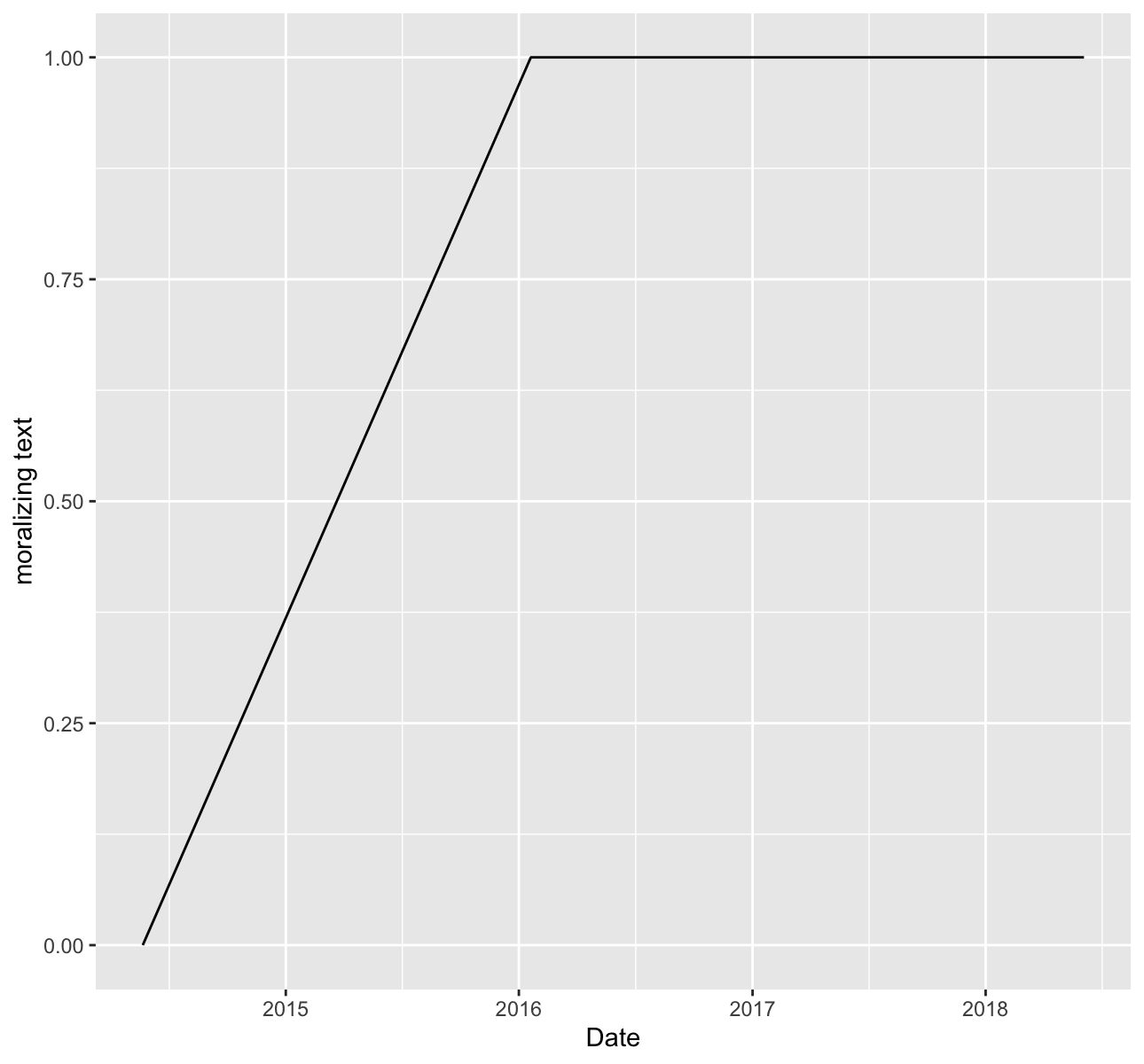
uj5u.com熱心網友回復:
您可以summarise計算 1 的數量morality,然后使用它來繪制ggplot2。您可以按每個日期分組進行總結。
library(tidyverse)
df %>%
mutate(created_at = as.Date(created_at)) %>%
group_by(created_at) %>%
summarise(count = sum(morality, na.rm = T)) %>%
ggplot(aes(x = created_at, y = count))
geom_line()
labs(x = "Date", y = "moralizing text")
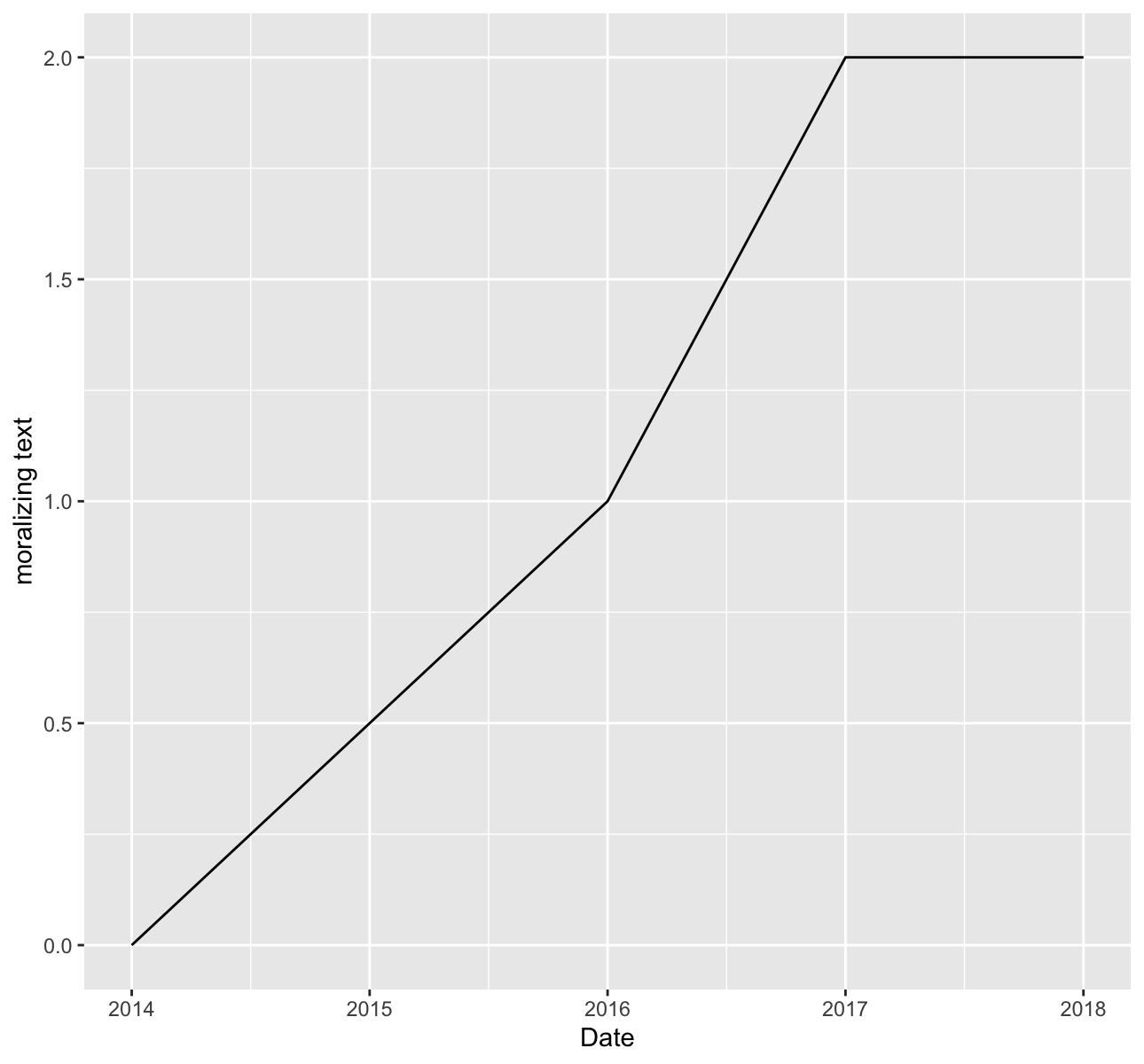
或者,如果您想獲取每年的計數,則可以從日期中提取年份,然后進行匯總。
library(tidyverse)
df %>%
mutate(Date = as.numeric(format(as.Date(created_at),"%Y"))) %>%
group_by(Date) %>%
summarise(count = sum(morality, na.rm = T)) %>%
ggplot(aes(x = Date, y = count))
geom_line()
labs(x = "Date", y = "moralizing text")
轉載請註明出處,本文鏈接:https://www.uj5u.com/net/491415.html