前言
System.Text.RegularExpressions 命名空間已經在 .NET 中使用了多年,一直追溯到 .NET Framework 1.1,它在 .NET 實施本身的數百個位置中使用,并且直接被成千上萬個應用程式使用,在所有這些方面,它也是 CPU 消耗的重要來源,
但是,從性能角度來看,正則運算式在這幾年間并沒有獲得太多關注,在 2006 年的 .NET Framework 2.0 中更改了其快取策略, .NET Core 2.0 在 RegexOptions.Compiled 之后看到了這個實作的到來(在 .NET Core 1.x 中,RegexOptions.Compiled 選項是一個 nop), .NET Core 3.0 受益于 Regex 內部的一些內部更新,以在某些情況下利用 Span<T> 提高記憶體利用率,在此程序中,一些非常受歡迎的社區貢獻改進了目標區域,例如 dotnet/corefx#32899,它減少了使用運算式 RegexOptions.Compiled | RegexOptions.IgnoreCase 時對CultureInfo.CurrentCulture 的訪問,但除此之外,實施很大程度上還是在15年前,
對于 .NET 5(本周發布了 Preview 2),我們已對 Regex 引擎進行了一些重大改進,在我們嘗試過的許多運算式中,這些更改通常會使吞吐量提高3到6倍,在某些情況下甚至會提高更多,在本文中,我將逐步介紹 .NET 5 中 System.Text.RegularExpressions 進行的許多更改,這些更改對我們自己的使用產生了可衡量的影響,我們希望這些改進將帶來可衡量的勝利在您的庫和應用中,
Regex內部知識
要了解所做的某些更改,了解一些Regex內部知識很有幫助,
Regex建構式完成所有作業,以采用正則運算式模式并準備對其進行匹配輸入:
-
RegexParser,該模式被送入內部RegexParser型別,該型別理解正則運算式語法并將其決議為節點樹,例如,運算式a|bcd被轉換為具有兩個子節點的“替代”RegexNode,一個子節點表示單個字符a,另一個子節點表示“多個”bcd,決議器還對樹進行優化,將一棵樹轉換為另一個等效樹,以提供更有效的表示和/或可以更高效地執行該樹, -
RegexWriter,節點樹不是執行匹配的理想表示,因此決議器的輸出將饋送到內部RegexWriter類,該類會寫出一系列緊湊的操作碼,以表示執行匹配的指令,這種型別的名稱是“ writer”,因為它“寫”出了操作碼,其他引擎通常將其稱為“編譯”,但是 .NET 引擎使用不同的術語,因為它保留了“編譯”術語,用于 MSIL 的可選編譯, -
RegexCompiler(可選),如果未指定RegexOptions.Compiled選項,則內部RegexInterpreter類稍后在匹配時使用RegexWriter輸出的操作碼來解釋/執行執行匹配的指令,并且在Regex構造程序中不需要任何操作,但是,如果指定了RegexOptions.Compiled,則建構式將獲取先前輸出的資產,并將其提供給內部RegexCompiler類,然后,RegexCompiler使用反射發射生成MSIL,該MSIL表示解釋程式將要執行的作業,但專門針對此特定運算式,例如,當與模式中的字符“ c”匹配時,解釋器將需要從變數中加載比較值,而編譯器會將“ c”硬編碼為生成的IL中的常量,
一旦構造了正則運算式,就可以通過IsMatch,Match,Matches,Replace和Split等實體方法將其用于匹配(Match回傳Match物件,該物件公開了NextMatch方法,該方法可以迭代匹配并延遲計算) ,這些操作最終以“掃描”回圈(某些其他引擎將其稱為“傳輸”回圈)結束,該回圈本質上執行以下操作:
while (FindFirstChar())
{
Go();
if (_match != null)
return _match;
_pos++;
}
return null;
_pos是我們在輸入中所處的當前位置,virtual FindFirstChar從_pos開始,并在輸入文本中查找正則運算式可能匹配的第一位;這并不是執行完整引擎,而是盡可能高效地進行搜索,以找到值得運行完整引擎的位置, FindFirstChar可以最大程度地減少誤報,并且找到有效位置的速度越快,運算式的處理速度就越快,如果找不到合適的起點,則可能沒有任何匹配,因此我們完成了,如果找到了一個好的起點,它將更新_pos,然后通過呼叫virtual Go來在找到的位置執行引擎,如果Go找不到匹配項,我們會碰到當前位置并重新開始,但是如果Go找到匹配項,它將存盤匹配資訊并回傳該資料,顯然,執行Go的速度也越快越好,
所有這些邏輯都在公共RegexRunner基類中, RegexInterpreter派生自RegexRunner,并用解釋正則運算式的實作覆寫FindFirstChar和Go,這由RegexWriter生成的操作碼表示, RegexCompiler使用DynamicMethods生成兩種方法,一種用于FindFirstChar,另一種用于Go,委托是從這些創建的、從RegexRunner派生的另一種型別呼叫,
.NET 5的改進
在本文的其余部分中,我們將逐步介紹針對 .NET 5 中的 Regex 進行的各種優化,這不是詳盡的清單,但它突出了一些最具影響力的更改,
CharInClass
正則運算式支持“字符類”,它們定義了輸入字符應該或不應該匹配的字符集,以便將該位置視為匹配字符,字符類用方括號表示,這里有些例子:
[abc]匹配“ a”,“ b”或“ c”,[^\n]匹配換行符以外的任何字符, (除非指定了RegexOptions.Singleline,否則這是您在運算式中使用的確切字符類,)[a-cx-z]匹配“ a”,“ b”,“ c”,“ x”,“ y”或“ z”,[\d\s\p{IsGreek}]匹配任何Unicode數字,空格或希臘字符, (與大多數其他正則運算式引擎相比,這是一個有趣的區別,例如,在其他引擎中,默認情況下,\d通常映射到[0-9],您可以選擇加入,而不是映射到所有Unicode數字,即[\p{Nd}],而在.NET中,您默認情況下會使用后者,并使用RegexOptions.ECMAScript選擇退出,)
當將包含字符類的模式傳遞給Regex建構式時,RegexParser的作業之一就是將該字符類轉換為可以在運行時更輕松地查詢的字符,決議器使用內部RegexCharClass型別來決議字符類,并從本質上提取三件事(還有更多東西,但這對于本次討論就足夠了):
- 模式是否被否定
- 匹配字符范圍的排序集
- 匹配字符的Unicode類別的排序集
這是所有實作的詳細資訊,但是該資訊然后保留在字串中,該字串可以傳遞給受保護的 RegexRunner.CharInClass 方法,以確定字符類中是否包含給定的Char,
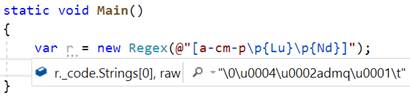
在.NET 5之前,每一次需要將一個字符與一個字符類進行匹配時,它將呼叫該CharInClass方法,然后,CharInClass對范圍進行二進制搜索,以確定指定字符是否存盤在一個字符中;如果不存盤,則獲取目標字符的Unicode類別,并對Unicode類別進行線性搜索,以查看是否匹配,因此,對于^\d*$之類的運算式(斷言它在行的開頭,然后匹配任意數量的Unicode數字,然后斷言在行的末尾),假設輸入了1000位數字,這加起來將對CharInClass進行1000次呼叫,
在 .NET 5 中,我們現在更加聰明地做到了這一點,尤其是在使用RegexOptions.Compiled時,通常,只要開發人員非常關心Regex的吞吐量,就可以使用它,一種解決方案是,對于每個字符類,維護一個查找表,該表將輸入字符映射到有關該字符是否在類中的是/否決定,雖然我們可以這樣做,但是System.Char是一個16位的值,這意味著每個字符一個位,我們需要為每個字符類使用8K查找表,并且這還要累加起來,取而代之的是,我們首先嘗試使用平臺中的現有功能或通過簡單的數學運算來快速進行匹配,以處理一些常見情況,例如,對于\d,我們現在不生成對RegexRunner.CharInClass(ch, charClassString) 的呼叫,而是僅生成對 char.IsDigit(ch)的呼叫, IsDigit已經使用查找表進行了優化,可以行內,并且性能非常好,類似地,對于\s,我們現在生成對char.IsWhitespace(ch)的呼叫,對于僅包含幾個字符的簡單字符類,我們將生成直接比較,例如對于[az],我們將生成等價于(ch =='a') | (ch =='z'),對于僅包含單個范圍的簡單字符類,我們將通過一次減法和比較來生成檢查,例如[a-z]導致(uint)ch-'a'<= 26,而 [^ 0-9] 導致 !((uint)c-'0'<= 10),我們還將特殊情況下的其他常見規范;例如,如果整個字符類都是一個Unicode類別,我們將僅生成對char.GetUnicodeInfo(也具有快速查找表)的呼叫,然后進行比較,例如[\p{Lu}]變為char.GetUnicodeInfo(c)== UnicodeCategory.UppercaseLetter,
當然,盡管涵蓋了許多常見情況,但當然并不能涵蓋所有情況,而且,因為我們不想為每個字符類生成8K查找表,并不意味著我們根本無法生成查找表,相反,如果我們沒有遇到這些常見情況之一,那么我們確實會生成一個查找表,但僅針對ASCII,它只需要16個位元組(128位),并且考慮到正則運算式中的典型輸入,這往往是一個很好的折衷方案基于方案,由于我們使用DynamicMethod生成方法,因此我們不容易將附加資料存盤在程式集的靜態資料部分中,但是我們可以做的就是利用常量字串作為資料存盤; MSIL具有用于加載常量字串的操作碼,并且反射發射對生成此類指令具有良好的支持,因此,對于每個查找表,我們只需創建所需的8個字符的字串,用不透明的位圖資料填充它,然后在IL中用ldstr吐出,然后我們可以像對待其他任何位圖一樣對待它,例如為了確定給定的字符是否匹配,我們生成以下內容:
bool result = ch < 128 ? (lookup[c >> 4] & (1 << (c & 0xF))) != 0 : NonAsciiFallback;
換句話說,我們使用字符的高三位選擇查找表字串中的第0至第7個字符,然后使用低四位作為該位置16位值的索引; 如果是1,則表示匹配,如果不是,則表示沒有匹配, 對于大于等于128的字符,我們需要一個回退,根據對字符類進行的一些分析,回退可能是各種各樣的事情, 最糟糕的情況是,回退只是對RegexRunner.CharInClass的呼叫,否則我們會做得更好, 例如,很常見的是,我們可以從輸入模式中得知所有可能的匹配項均小于<128,在這種情況下,我們根本不需要回退,例如 對于字符類[0-9a-fA-F](又稱十六進制),我們將生成以下內容:
bool result = ch < 128 && (lookup[c >> 4] & (1 << (c & 0xF))) != 0;
相反,我們可以確定127以上的每個字符都將去匹配, 例如,字符類[^aeiou](除ASCII小寫元音外的所有字符)將產生與以下代碼等效的代碼:
bool result = ch >= 128 || (lookup[c >> 4] & (1 << (c & 0xF))) != 0;
等等,
以上都是針對RegexOptions.Compiled,但解釋運算式并不會被冷落, 對于解釋運算式,我們當前會生成一個類似的查找表,但是我們這樣做是很懶惰的,第一次看到給定輸入字符時會填充該表,然后針對該字符類針對該字符的所有將來評估存盤該答案, (我們可能會重新研究如何執行此操作,但這是從 .NET 5 Preview 2 開始存在的方式,)
這樣做的最終結果可能是頻繁評估字符類的運算式的吞吐量顯著提高, 例如,這是一個微基準測驗,可將ASCII字母和數字與具有62個此類值的輸入進行匹配:
using BenchmarkDotNet.Attributes;
using BenchmarkDotNet.Running;
using System.Text.RegularExpressions;
public class Program
{
static void Main(string[] args) => BenchmarkSwitcher.FromAssemblies(new[] { typeof(Program).Assembly }).Run(args);
private Regex _regex = new Regex("[a-zA-Z0-9]*", RegexOptions.Compiled);
[Benchmark] public bool IsMatch() => _regex.IsMatch("abcdefghijklmnopqrstuvwxyz123456789ABCDEFGHIJKLMNOPQRSTUVWXYZ");
}
這是我的專案檔案:
<project Sdk="Microsoft.NET.Sdk">
<propertygroup>
<langversion>preview</langversion>
<outputtype>Exe</outputtype>
<targetframeworks>netcoreapp5.0;netcoreapp3.1</targetframeworks>
</propertygroup>
<itemgroup>
<packagereference Include="benchmarkdotnet" Version="0.12.0.1229"></packagereference>
</itemgroup>
</project>
在我的計算機上,我有兩個目錄,一個包含.NET Core 3.1,一個包含.NET 5的內部版本(此處標記為master,因為它是dotnet/runtime的master分支的內部版本), 當我執行以上操作針對兩個版本運行基準測驗:
dotnet run -c Release -f netcoreapp3.1 --filter ** --corerun d:\coreclrtest\netcore31\corerun.exe d:\coreclrtest\master\corerun.exe
我得到了以下結果:
| Method | Toolchain | Mean | Error | StdDev | Ratio |
|---|---|---|---|---|---|
| IsMatch | \master\corerun.exe | 102.3 ns | 1.33 ns | 1.24 ns | 0.17 |
| IsMatch | \netcore31\corerun.exe | 585.7 ns | 2.80 ns | 2.49 ns | 1.00 |
開發人員可能會寫的代碼生成器
如前所述,當RegexOptions.Compiled與Regex一起使用時,我們使用反射發射為其生成兩種方法,一種實作FindFirstChar,另一種實作Go, 為了支持回溯,Go最終包含了很多通常不需要的代碼, 生成代碼的方式通常包括不必要的欄位讀取和寫入,導致檢查JIT無法消除的邊界等, 在 .NET 5 中,我們改進了為許多運算式生成的代碼,
考慮運算式@"a\sb",它匹配一個'a',任何Unicode空格和一個'b', 以前,反編譯為Go發出的IL看起來像這樣:
public override void Go()
{
string runtext = base.runtext;
int runtextstart = base.runtextstart;
int runtextbeg = base.runtextbeg;
int runtextend = base.runtextend;
int num = runtextpos;
int[] runtrack = base.runtrack;
int runtrackpos = base.runtrackpos;
int[] runstack = base.runstack;
int runstackpos = base.runstackpos;
CheckTimeout();
runtrack[--runtrackpos] = num;
runtrack[--runtrackpos] = 0;
CheckTimeout();
runstack[--runstackpos] = num;
runtrack[--runtrackpos] = 1;
CheckTimeout();
if (num < runtextend && runtext[num++] == 'a')
{
CheckTimeout();
if (num < runtextend && RegexRunner.CharInClass(runtext[num++], "\0\0\u0001d"))
{
CheckTimeout();
if (num < runtextend && runtext[num++] == 'b')
{
CheckTimeout();
int num2 = runstack[runstackpos++];
Capture(0, num2, num);
runtrack[--runtrackpos] = num2;
runtrack[--runtrackpos] = 2;
goto IL_0131;
}
}
}
while (true)
{
base.runtrackpos = runtrackpos;
base.runstackpos = runstackpos;
EnsureStorage();
runtrackpos = base.runtrackpos;
runstackpos = base.runstackpos;
runtrack = base.runtrack;
runstack = base.runstack;
switch (runtrack[runtrackpos++])
{
case 1:
CheckTimeout();
runstackpos++;
continue;
case 2:
CheckTimeout();
runstack[--runstackpos] = runtrack[runtrackpos++];
Uncapture();
continue;
}
break;
}
CheckTimeout();
num = runtrack[runtrackpos++];
goto IL_0131;
IL_0131:
CheckTimeout();
runtextpos = num;
}
那里有很多東西,需要斜視和搜索才能將實作的核心看作方法的中間幾行, 現在在.NET 5中,相同的運算式導致生成以下代碼:
protected override void Go()
{
string runtext = base.runtext;
int runtextend = base.runtextend;
int runtextpos;
int start = runtextpos = base.runtextpos;
ReadOnlySpan<char> readOnlySpan = runtext.AsSpan(runtextpos, runtextend - runtextpos);
if (0u < (uint)readOnlySpan.Length && readOnlySpan[0] == 'a' &&
1u < (uint)readOnlySpan.Length && char.IsWhiteSpace(readOnlySpan[1]) &&
2u < (uint)readOnlySpan.Length && readOnlySpan[2] == 'b')
{
Capture(0, start, base.runtextpos = runtextpos + 3);
}
}
如果您像我一樣,則可以注視著眼睛看第一個版本,但是如果您看到第二個版本,則可以真正閱讀并了解它的功能, 除了易于理解和易于除錯之外,它還減少了執行的代碼,消除了邊界檢查,減少了對欄位和陣列的讀寫等方面的作業, 最終的結果是它的執行速度也快得多, (這里還有進一步改進的可能性,例如洗掉兩個長度檢查,可能會重新排序一些檢查,但總的來說,它比以前有了很大的改進,)
向量化的基于 Span 的搜索
正則運算式都是關于搜索內容的, 結果,我們經常發現自己正在運行回圈以尋找各種事物, 例如,考慮運算式 hello.*world, 以前,如果要反編譯我們在Go方法中生成的用于匹配.*的代碼,則該代碼類似于以下內容:
while (--num3 > 0)
{
if (runtext[num++] == '\n')
{
num--;
break;
}
}
換句話說,我們將手動遍歷輸入文本字串,逐個字符地查找 \n(請記住,默認情況下,.表示“ \n以外的任何內容”,因此.*表示“匹配所有內容,直到找到\n” ), 但是,.NET早已擁有完全執行此類搜索的方法,例如IndexOf,并且從最新版本開始,IndexOf是矢量化的,因此它可以同時比較多個字符,而不僅僅是單獨查看每個字符, 現在,在.NET 5中,我們不再像上面那樣生成代碼,而是得到如下代碼:
num2 = runtext.AsSpan(runtextpos, num).IndexOf('\n');
使用IndexOf而不是生成我們自己的回圈,則意味著對Regex中的此類搜索進行隱式矢量化,并且對此類實作的任何改進也都應歸于此, 這也意味著生成的代碼更簡單, 可以用這樣的基準測驗來查看其影響:
using BenchmarkDotNet.Attributes;
using BenchmarkDotNet.Running;
using System.Text.RegularExpressions;
public class Program
{
static void Main(string[] args) => BenchmarkSwitcher.FromAssemblies(new[] { typeof(Program).Assembly }).Run(args);
private Regex _regex = new Regex("hello.*world", RegexOptions.Compiled);
[Benchmark] public bool IsMatch() => _regex.IsMatch("hello. this is a test to see if it's able to find something more quickly in the world.");
}
即使輸入的字串不是特別大,也會產生可衡量的影響:
| Method | Toolchain | Mean | Error | StdDev | Ratio |
|---|---|---|---|---|---|
| IsMatch | \master\corerun.exe | 71.03 ns | 0.308 ns | 0.257 ns | 0.47 |
| IsMatch | \netcore31\corerun.exe | 149.80 ns | 0.913 ns | 0.809 ns | 1.00 |
IndexOfAny最侄訓是.NET 5實作中的重要工具,尤其是對于FindFirstChar的實作, .NET Regex實作使用的現有優化之一是對可以開始運算式的所有可能字符進行分析, 生成一個字符類,然后FindFirstChar使用該字符類對可能開始匹配的下一個位置生成搜索, 這可以通過查看運算式([ab]cd|ef [g-i])jklm的生成代碼的反編譯版本來看到, 與該運算式的有效匹配只能以'a','b'或'e'開頭,因此優化器生成一個字符類[abe],FindFirstChar然后使用:
public override bool FindFirstChar()
{
int num = runtextpos;
string runtext = base.runtext;
int num2 = runtextend - num;
if (num2 > 0)
{
int result;
while (true)
{
num2--;
if (!RegexRunner.CharInClass(runtext[num++], "\0\u0004\0acef"))
{
if (num2 <= 0)
{
result = 0;
break;
}
continue;
}
num--;
result = 1;
break;
}
runtextpos = num;
return (byte)result != 0;
}
return false;
}
這里需要注意的幾件事:
-
正如前面所討論的,我們可以看到每個字符都是通過
CharInClass求值的, 我們可以看到傳遞給CharInClass的字串是該類的內部可搜索表示(第一個字符表示沒有取反,第二個字符表示有四個用于表示范圍的字符,第三個字符表示沒有Unicode類別) ,然后接下來的四個字符代表兩個范圍,分別包含下限和上限, -
我們可以看到我們分別評估每個字符,而不是能夠一起評估多個字符,
-
我們只看第一個字符,如果匹配,我們退出以允許引擎完全執行
Go,
在.NET 5 Preview 2中,我們現在生成此代碼:
protected override bool FindFirstChar()
{
int runtextpos = base.runtextpos;
int runtextend = base.runtextend;
if (runtextpos <= runtextend - 7)
{
ReadOnlySpan<char> readOnlySpan = runtext.AsSpan(runtextpos, runtextend - runtextpos);
for (int num = 0; num < readOnlySpan.Length - 2; num++)
{
int num2 = readOnlySpan.Slice(num).IndexOfAny('a', 'b', 'e');
num = num2 + num;
if (num2 < 0 || readOnlySpan.Length - 2 <= num)
{
break;
}
int num3 = readOnlySpan[num + 1];
if ((num3 == 'c') | (num3 == 'f'))
{
num3 = readOnlySpan[num + 2];
if (num3 < 128 && ("\0\0\0\0\0\0?\0"[num3 >> 4] & (1 << (num3 & 0xF))) != 0)
{
base.runtextpos = runtextpos + num;
return true;
}
}
}
}
base.runtextpos = runtextend;
return false;
}
這里要注意一些有趣的事情:
-
現在,我們使用
IndexOfAny搜索三個目標字符,IndexOfAny是矢量化的,因此它可以利用SIMD指令一次比較多個字符,并且我們為進一步優化IndexOfAny所做的任何未來改進都將隱式歸于此類FindFirstChar實作, -
如果
IndexOfAny找到匹配項,我們不只是立即回傳以給Go機會執行,相反,我們對接下來的幾個字符進行快速檢查,以增加這實際上是匹配項的可能性,在原始運算式中,您可以看到可能與第二個字符匹配的唯一值是'c'和'f',因此該實作對這些字符進行了快速比較檢查,您會看到第三個字符必須與'd'或[g-i]匹配,因此該實作將這些字符組合到單個字符類[dg-i]中,然后使用位圖對其進行評估,后兩個字符檢查都突出了我們現在為字符類發出的改進的代碼生成,
我們可以在這樣的測驗中看到這種潛在的影響:
using BenchmarkDotNet.Attributes;
using BenchmarkDotNet.Running;
using System;
using System.Linq;
using System.Text.RegularExpressions;
public class Program
{
static void Main(string[] args) => BenchmarkSwitcher.FromAssemblies(new[] { typeof(Program).Assembly }).Run(args);
private static Random s_rand = new Random(42);
private Regex _regex = new Regex("([ab]cd|ef[g-i])jklm", RegexOptions.Compiled);
private string _input = string.Concat(Enumerable.Range(0, 1000).Select(_ => (char)('a' + s_rand.Next(26))));
[Benchmark] public bool IsMatch() => _regex.IsMatch(_input);
}
在我的機器上會產生以下結果:
| Method | Toolchain | Mean | Error | StdDev | Ratio |
|---|---|---|---|---|---|
| IsMatch | \master\corerun.exe | 1.084 us | 0.0068 us | 0.0061 us | 0.08 |
| IsMatch | \netcore31\corerun.exe | 14.235 us | 0.0620 us | 0.0550 us | 1.00 |
先前的代碼差異也突出了另一個有趣的改進,特別是舊代碼的int num2 = runtextend-num;`` if(num2> 0)和新代碼的if(runtextpos <= runtextend-7)之間的差異,,如前所述,RegexParser將輸入模式決議為節點樹,然后對其進行分析和優化, .NET 5包括各種新的分析,有些簡單,有些更復雜,較簡單的示例之一是決議器現在將對運算式進行快速掃描,以確定是否必須有最小輸入長度才能匹配輸入,考慮一下運算式[0-9]{3}-[0-9]{2}-[0-9]{4},該運算式可用于匹配美國的社會保險號(三個ASCII數字,破折號,兩個ASCII數字,一個破折號,四個ASCII數字),我們可以很容易地看到,此模式的任何有效匹配都至少需要11個字符;如果為我們提供了10個或更少的輸入,或者如果我們在輸入末尾找到10個字符以內卻沒有找到匹配項,那么我們可能會立即使匹配項失敗而無需進一步進行,因為這是不可能的匹配,
using BenchmarkDotNet.Attributes;
using BenchmarkDotNet.Diagnosers;
using BenchmarkDotNet.Running;
using System.Text.RegularExpressions;
public class Program
{
static void Main(string[] args) => BenchmarkSwitcher.FromAssemblies(new[] { typeof(Program).Assembly }).Run(args);
private readonly Regex _regex = new Regex("[0-9]{3}-[0-9]{2}-[0-9]{4}", RegexOptions.Compiled);
[Benchmark] public bool IsMatch() => _regex.IsMatch("123-45-678");
}
| Method | Toolchain | Mean | Error | StdDev | Ratio |
|---|---|---|---|---|---|
| IsMatch | \master\corerun.exe | 19.39 ns | 0.148 ns | 0.139 ns | 0.04 |
| IsMatch | \netcore31\corerun.exe | 459.86 ns | 1.893 ns | 1.771 ns | 1.00 |
回溯消除
.NET Regex實作當前使用回溯引擎,這種實作可以支持基于DFA的引擎無法輕松或有效地支持的各種功能,例如反向參考,并且在記憶體利用率以及常見情況下的吞吐量方面都非常高效,但是,回溯有一個很大的缺點,那就是可能導致退化的情況,即匹配在輸入長度上花費了指數時間,這就是.NET Regex類公開設定超時的功能的原因,因此失控匹配可能會被例外中斷,
.NET檔案提供了更多詳細資訊,但可以這樣說,開發人員可以撰寫正則運算式,而不會受到過多的回溯,一種方法是采用“原子組”,該原子組告訴引擎,一旦組匹配,實作就不得回溯到它,通常在這種回溯不會帶來好處的情況下使用,考慮與輸入aaaa匹配的示例運算式a+b:
-
Go引擎開??始匹配a+,此操作是貪婪的,因此它匹配第一個a,然后匹配aa,然后匹配aaa,然后匹配aaaa,然后,它會顯示在輸入的末尾, -
沒有
b匹配,因此引擎回溯1,而a+現在匹配aaa, -
仍然沒有
b匹配,因此引擎回溯1,而a+現在匹配aa, -
仍然沒有
b匹配,因此引擎回溯1,而a+現在匹配a, -
仍然沒有
b可以匹配,而a+至少需要1個a,因此匹配失敗,
但是,所有這些回溯都被證明是不必要的, a+不能匹配b可以匹配的東西,因此在這里進行大量的回溯是不會有成果的,看到這一點,開發人員可以改用運算式(?>a+)b, (?>和)是原子組的開始和結束,它表示一旦該組匹配并且引擎經過該組,則它一定不能回溯到該組中,然后,使用我們之前針對aaaa進行匹配的示例,則將發生這種情況:
-
Go引擎開??始匹配
a+,此操作是貪婪的,因此它匹配第一個a,然后匹配aa,然后匹配aaa,然后匹配aaaa,然后,它會顯示在輸入的末尾, -
沒有匹配的b,因此匹配失敗,
簡短得多,這只是一個簡單的示例,因此,開發人員可以自己進行此分析并找到手動插入原子組的位置,但是,實際上,有多少開發人員認為這樣做或花費時間呢?
相反,.NET 5現在將正則運算式作為節點樹優化階段的一部分進行分析,在發現原子組不會產生語意差異但可以幫助避免回溯的地方添加原子組,例如:
a+b將變成(?>a+)b1,因為沒有任何a+可以“回饋”與b相匹配的內容
\d+\s*將變成(?>\d+)(?>\s*),因為沒有任何可以匹配\d的東西也可以匹配\s,并且\s在運算式的末尾,
a*([xyz]|hello)將變為(?>a*)([xyz]|hello),因為在成功匹配中,a可以跟著x,y,z或h,并且沒有與任何這些重疊,
這只是.NET 5現在將執行的樹重寫的一個示例,它將進行其他重寫,部分目的是消除回溯,例如,現在它將合并彼此相鄰的各種形式的回圈,考慮退化的例子a*a*a*a*a*a*a*b,在.NET 5中,現在將其重寫為功能上等效的a*b,然后根據前面的討論將其進一步重寫為(?>a*)b,這將潛在的非常昂貴的執行轉換為具有線性執行時間的執行,由于我們正在處理不同的演算法復雜性,因此顯示示例基準幾乎沒有意義,但是無論如何我還是會這樣做,只是為了好玩:
using BenchmarkDotNet.Attributes;
using BenchmarkDotNet.Running;
using System.Text.RegularExpressions;
public class Program
{
static void Main(string[] args) => BenchmarkSwitcher.FromAssemblies(new[] { typeof(Program).Assembly }).Run(args);
private Regex _regex = new Regex("a*a*a*a*a*a*a*b", RegexOptions.Compiled);
[Benchmark] public bool IsMatch() => _regex.IsMatch("aaaaaaaaaaaaaaaaaaaaa");
}
| Method | Toolchain | Mean | Error | StdDev | Ratio |
|---|---|---|---|---|---|
| IsMatch | \master\corerun.exe | 379.2 ns | 2.52 ns | 2.36 ns | 0.000 |
| IsMatch | \netcore31\corerun.exe | 22,367,426.9 ns | 123,981.09 ns | 115,971.99 ns | 1.000 |
回溯減少不僅限于回圈,輪換表示回溯的另一個來源,因為實作方式的匹配方式與您手動匹配時的方式類似:嘗試一個輪換分支并繼續進行,如果匹配失敗,請回傳并嘗試下一個分支,依此類推,因此,減少交替產生的回溯也是有用的,
現在執行的此類重寫之一與交替前綴分解有關,考慮針對文本什么是運算式(?:this|that)的運算式,引擎將匹配內容,然后嘗試與此匹配,它不會匹配,因此它將回溯并嘗試與此匹配,但是交替的兩個分支都以th開頭,如果我們將其排除在外,然后將運算式重寫為th(?:is|at),則現在可以避免回溯,引擎將匹配,然后嘗試將th與它匹配,然后失敗,僅此而已,
這種優化還最終使更多文本暴露給FindFirstChar使用的現有優化,如果模式的開頭有多個固定字符,則FindFirstChar將使用Boyer-Moore實作在輸入字串中查找該文本,暴露給Boyer-Moore演算法的模式越大,在快速找到匹配并最小化將導致FindFirstChar退出到Go引擎的誤報中所能做的越好,通過從這種交替中拉出文本,在這種情況下,我們增加了Boyer-Moore可用的文本量,
作為另一個相關示例,.NET 5現在發現即使開發人員未指定也可以隱式錨定運算式的情況,這也有助于消除回溯,考慮用*hello匹配abcdefghijk,該實作將從位置0開始,并在該位置計算運算式,這樣做會將整個字串abcdefghijk與.*匹配,然后從那里回溯以嘗試匹配hello,這將無法完成,引擎將使匹配失敗,然后我們將升至下一個位置,然后,引擎將把字串bcdefghijk的其余部分與.*進行匹配,然后從那里回溯以嘗試匹配hello,這將再次失敗,等等,在這里觀察到的是,通過碰到下一個位置進行的重試通常不會成功,并且運算式可以隱式地錨定為僅在行的開頭匹配,然后,FindFirstChar可以跳過可能不匹配的位置,并避免在這些位置嘗試進行引擎匹配,
using BenchmarkDotNet.Attributes;
using BenchmarkDotNet.Diagnosers;
using BenchmarkDotNet.Running;
using System.Text.RegularExpressions;
public class Program
{
static void Main(string[] args) => BenchmarkSwitcher.FromAssemblies(new[] { typeof(Program).Assembly }).Run(args);
private readonly Regex _regex = new Regex(@".*text", RegexOptions.Compiled);
[Benchmark] public bool IsMatch() => _regex.IsMatch("This is a test.\nDoes it match this?\nWhat about this text?");
}
| Method | Toolchain | Mean | Error | StdDev | Ratio |
|---|---|---|---|---|---|
| IsMatch | \master\corerun.exe | 644.1 ns | 3.63 ns | 3.39 ns | 0.21 |
| IsMatch | \netcore31\corerun.exe | 3,024.9 ns | 22.66 ns | 20.09 ns | 1.00 |
(只是為了清楚起見,許多正則運算式仍將在 .NET 5 中采用回溯,因此開發人員仍然需要謹慎運行不可信的正則運算式,)
Regex.* 靜態方法和并發
Regex類同時公開實體方法和靜態方法,靜態方法主要是為了方便起見,因為它們仍然需要在Regex實體上使用和操作,每次使用這些靜態方法之一時,該實作都可以實體化一個新的Regex并經歷完整的決議/優化/代碼生成例程,但是在某些情況下,這將浪費大量的時間和空間,相反,Regex會保留最近使用的Regex物件的快取,并按使它們唯一的所有內容(例如,模式,RegexOptions甚至在CurrentCulture下(因為這可能會影響IgnoreCase匹配),此快取的大小受到限制,以Regex.CacheSize為上限,因此該實作采用了最近最少使用的(LRU)快取:當快取已滿并且需要添加另一個Regex時,實作將丟棄最近最少使用的項,快取,
實作這種LRU快取的一種簡單方法是使用鏈接串列:每次訪問某項時,它都會從串列中洗掉并重新添加到最前面,但是,這種方法有一個很大的缺點,尤其是在并發世界中:同步,如果每次讀取實際上都是一個突變,則我們需要確保并發讀取(并發突變)不會破壞串列,這樣的串列正是.NET早期版本所采用的串列,并且使用了全域鎖來保護它,在.NET Core 2.1中,社區成員提交的一項不錯的更改通過允許訪問最近使用的無鎖項在某些情況下對此進行了改進,從而提高了通過靜態使用相同Regex的作業負載的吞吐量和可伸縮性,方法反復,但是,對于其他情況,實作仍然鎖定在每種用法上,
通過查看諸如Concurrency Visualizer之類的工具,可以看到此鎖定的影響,該工具是Visual Studio的擴展,可在其擴展程式庫中使用,通過在分析器下運行這樣的示例應用程式:
using System.Text.RegularExpressions;
using System.Threading.Tasks;
class Program
{
static void Main()
{
Parallel.Invoke(
() => { while (true) Regex.IsMatch("abc", "^abc$"); },
() => { while (true) Regex.IsMatch("def", "^def$"); },
() => { while (true) Regex.IsMatch("ghi", "^ghi$"); },
() => { while (true) Regex.IsMatch("jkl", "^jkl$"); });
}
}
我們可以看到這樣的影像:

每行都是一個執行緒,它是此Parallel.Invoke的一部分, 綠色區域是執行緒實際執行代碼的時間, 黃色區域表示作業系統已搶占該執行緒的原因,因為該執行緒需要內核運行另一個執行緒, 紅色區域表示執行緒被阻止等待某物, 在這種情況下,所有紅色是因為執行緒正在等待Regex快取中的共享全域鎖,
在.NET 5中,圖片看起來像這樣:

注意,沒有更多的紅色部分, 這是因為快取已被重寫為完全無鎖的讀取; 唯一獲得鎖的時間是將新的Regex添加到快取中,但是即使發生這種情況,其他執行緒也可以繼續從快取中讀取實體并使用它們, 這意味著,只要為應用程式及其常規使用的Regex靜態方法正確調整Regex.CacheSize的大小,此類訪問將不再招致它們過去的延遲, 到今天為止,該值默認為15,但是該屬性具有設定器,因此可以對其進行更改以更好地滿足應用程式的需求,
靜態方法的分配也得到了改進,方法是精確地更改快取內容,從而避免分配不必要的包裝物件, 我們可以通過上一個示例的修改版本看到這一點:
using System.Text.RegularExpressions;
using System.Threading.Tasks;
class Program
{
static void Main()
{
Parallel.Invoke(
() => { for (int i = 0; i < 10_000; i++) Regex.IsMatch("abc", "^abc$"); },
() => { for (int i = 0; i < 10_000; i++) Regex.IsMatch("def", "^def$"); },
() => { for (int i = 0; i < 10_000; i++) Regex.IsMatch("ghi", "^ghi$"); },
() => { for (int i = 0; i < 10_000; i++) Regex.IsMatch("jkl", "^jkl$"); });
}
}
使用Visual Studio中的.NET物件分配跟蹤工具運行它, 左邊是.NET Core 3.1,右邊是.NET 5 Preview 2:
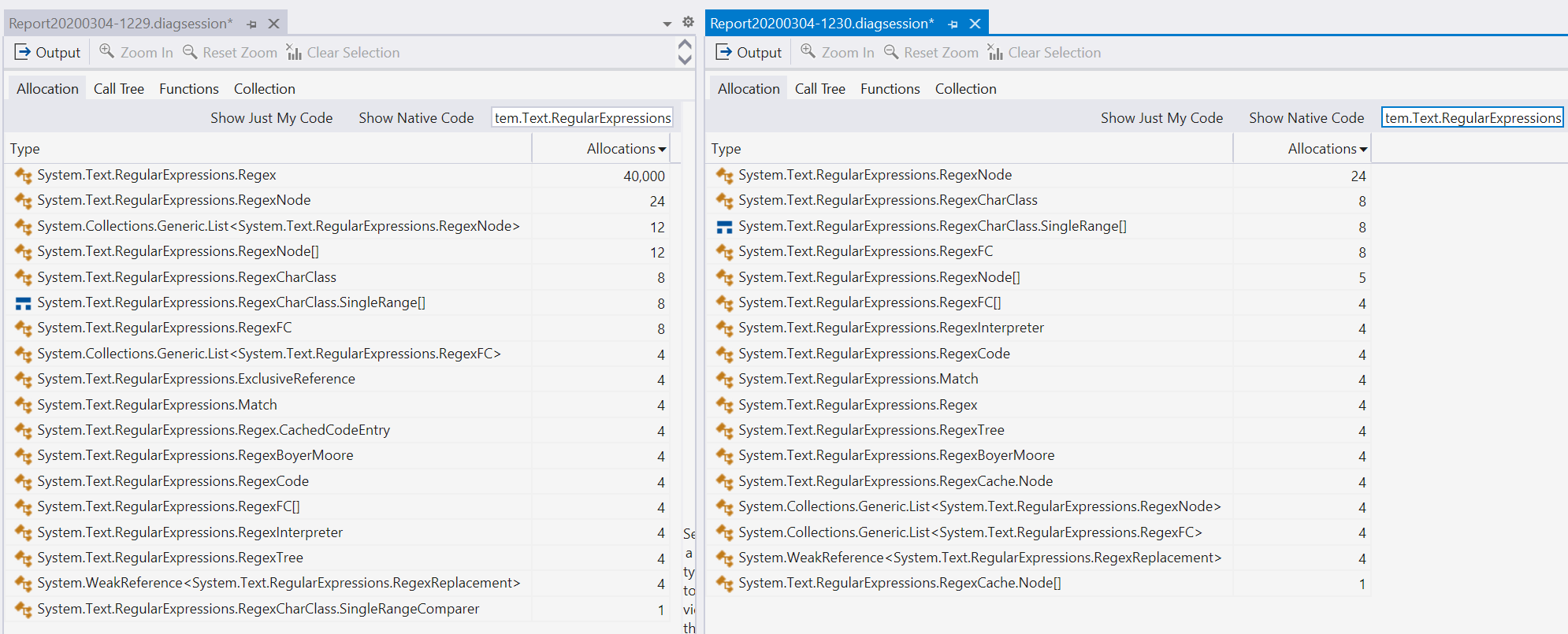
特別要注意的是,左側包含40,000個分配的行,而右側只有4個,
其他開銷減少
我們已經介紹了.NET 5中對正則運算式進行的一些關鍵改進,但該串列絕不是完整的, 到處都有一些較小的優化清單,盡管我們不能在這里列舉所有的優化清單,但我們可以逐步介紹更多,
在某些地方,我們已經采用了前面討論過的矢量化形式, 例如,當使用RegexOptions.Compiled且該模式包含一個字串字串時,編譯器將分別檢查每個字符, 如果查看諸如abcd之類的運算式的反編譯代碼,就會看到以下內容:
if (4 <= runtextend - runtextpos &&
runtext[runtextpos] == 'a' &&
runtext[runtextpos + 1] == 'b' &&
runtext[runtextpos + 2] == 'c' &&
runtext[runtextpos + 3] == 'd')
在.NET 5中,當使用DynamicMethod創建編譯后的代碼時,我們現在嘗試比較Int64值(在64位系統上,或在32位系統上比較Int32),而不是比較單個字符, 這意味著對于上一個示例,我們現在改為生成與此類似的代碼:
if (3u < (uint)readOnlySpan.Length && *(long*)readOnlySpan._pointer == 28147922879250529L)
(我說“類似”,因為我們無法在C#中表示生成的確切IL,這與使用Unsafe型別的成員更加一致,)我們這里不必擔心位元組順序問題,因為生成用于比較的Int64/Int32值的代碼與加載用于比較的輸入值的同一臺計算機(甚至在同一行程中)發生,
另一個示例是先前在先前生成的代碼示例中實際顯示的內容,但已被掩蓋,在比較@"a\sb"運算式的輸出時,您可能之前已經注意到,以前的代碼包含對CheckTimeout()的呼叫,但是新代碼沒有,此CheckTimeout()函式用于檢查我們的執行時間是否超過了Regex構造時提供給其的超時值所允許的時間,但是,在沒有提供超時的情況下使用的默認超時是“無限”,因此“無限”是非常常見的值,由于我們永遠不會超過無限超時,因此當我們為RegexOptions.Compiled正則運算式編譯代碼時,我們會檢查超時,如果是無限超時,則跳過生成這些CheckTimeout()呼叫,
在其他地方也存在類似的優化,例如,默認情況下,Regex執行區分大小寫的比較,僅在指定RegexOptions.IgnoreCase的情況下(或者運算式本身包含執行不區分大小寫的匹配的指令)才使用不區分大小寫的比較,并且僅當使用不區分大小寫的比較時,我們才需要訪問CultureInfo.CurrentCulture以確定如何進行比較,此外,如果指定了RegexOptions.InvariantCulture,則我們也無需訪問CultureInfo.CurrentCulture,因為它將永遠不會使用,所有這些意味著,如果我們證明不再需要它,則可以避免生成訪問CultureInfo.CurrentCulture的代碼,最重要的是,我們可以通過發出對char.ToLowerInvariant而不是char.ToLower(CultureInfo.InvariantCulture)的呼叫來使RegexOptions.InvariantCulture更快,尤其是因為.NET 5中ToLowerInvariant也得到了改進(還有另一個示例,其中將Regex更改為使用其他框架功能時,只要我們改進這些已利用的功能,它就會隱式受益,
另一個有趣的更改是Regex.Replace和Regex.Split,這些方法被實作為對Regex.Match的封裝,將其功能分層,但是,這意味著每次找到匹配項時,我們都將退出掃描回圈,逐步遍歷抽象的各個層次,在匹配項上執行作業,然后調回引擎,以正確的方式進行作業回傳到掃描回圈,依此類推,最重要的是,每個匹配項都需要創建一個新的Match物件,現在在.NET 5中,這些方法在內部使用了一個專用的基于回呼的回圈,這使我們能夠停留在嚴格的掃描回圈中,并一遍又一遍地重用同一個Match物件(如果公開公開,這是不安全的,但是可以作為內部實施細節來完成),在實作“替換”中使用的記憶體管理也已調整為專注于跟蹤要替換或不替換的輸入區域,而不是跟蹤每個單獨的字符,這樣做的最終結果可能對吞吐量和記憶體分配都產生相當大的影響,尤其是對于輸入量非常長且替換次數很少的輸入,
using BenchmarkDotNet.Attributes;
using BenchmarkDotNet.Running;
using System.Linq;
using System.Text.RegularExpressions;
[MemoryDiagnoser]
public class Program
{
static void Main(string[] args) => BenchmarkSwitcher.FromAssemblies(new[] { typeof(Program).Assembly }).Run(args);
private Regex _regex = new Regex("a", RegexOptions.Compiled);
private string _input = string.Concat(Enumerable.Repeat("abcdefghijklmnopqrstuvwxyz", 1_000_000));
[Benchmark] public string Replace() => _regex.Replace(_input, "A");
}
| Method | Toolchain | Mean | Error | StdDev | Ratio | Gen 0 | Gen 1 | Gen 2 | Allocated |
|---|---|---|---|---|---|---|---|---|---|
| Replace | \master\corerun.exe | 93.79 ms | 1.120 ms | 0.935 ms | 0.45 | – | – | – | 81.59 MB |
| Replace | \netcore31\corerun.exe | 209.59 ms | 3.654 ms | 3.418 ms | 1.00 | 33666.6667 | 666.6667 | 666.6667 | 371.96 MB |
看看效果
所有這些結合在一起,可以在各種基準上產生明顯更好的性能, 為了說明這一點,我在網上搜索了正則運算式基準并進行了幾次測驗,
mariomka/regex-benchmark的基準測驗已經具有C#版本,因此簡單地編譯和運行這很容易:
using System;
using System.IO;
using System.Text.RegularExpressions;
using System.Diagnostics;
class Benchmark
{
static void Main(string[] args)
{
if (args.Length != 1)
{
Console.WriteLine("Usage: benchmark <filename>");
Environment.Exit(1);
}
StreamReader reader = new System.IO.StreamReader(args[0]);
string data = https://www.cnblogs.com/hez2010/p/reader.ReadToEnd();
// Email
Benchmark.Measure(data, @"[/w/.+-]+@[/w/.-]+/.[/w/.-]+");
// URI
Benchmark.Measure(data, @"[/w]+://[^/s?#]+[^\s?#]+(?:\?[^\s#]*)?(?:#[^\s]*)?");
// IP
Benchmark.Measure(data, @"(?:(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9])\.){3}(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9])");
}
static void Measure(string data, string pattern)
{
Stopwatch stopwatch = Stopwatch.StartNew();
MatchCollection matches = Regex.Matches(data, pattern, RegexOptions.Compiled);
int count = matches.Count;
stopwatch.Stop();
Console.WriteLine(stopwatch.Elapsed.TotalMilliseconds.ToString("G", System.Globalization.CultureInfo.InvariantCulture) + " - " + count);
}
}
在我的機器上,這是使用.NET Core 3.1的控制臺輸出:
966.9274 - 92
746.3963 - 5301
65.6778 - 5
以及使用.NET 5的控制臺輸出:
274.3515 - 92
159.3629 - 5301
15.6075 - 5
破折號前的數字是執行時間,破折號后的數字是答案(因此,第二個數字保持不變是一件好事), 執行時間急劇下降:分別提高了3.5倍,4.6倍和4.2倍!
我還找到了 https://zherczeg.github.io/sljit/regex_perf.html,它具有各種基準,但沒有C#版本, 我將其轉換為Benchmark.NET測驗:
using BenchmarkDotNet.Attributes;
using BenchmarkDotNet.Running;
using System.IO;
using System.Text.RegularExpressions;
[MemoryDiagnoser]
public class Program
{
static void Main(string[] args) => BenchmarkSwitcher.FromAssemblies(new[] { typeof(Program).Assembly }).Run(args);
private static string s_input = File.ReadAllText(@"d:\mtent12.txt");
private Regex _regex;
[GlobalSetup]
public void Setup() => _regex = new Regex(Pattern, RegexOptions.Compiled);
[Params(
@"Twain",
@"(?i)Twain",
@"[a-z]shing",
@"Huck[a-zA-Z]+|Saw[a-zA-Z]+",
@"\b\w+nn\b",
@"[a-q][^u-z]{13}x",
@"Tom|Sawyer|Huckleberry|Finn",
@"(?i)Tom|Sawyer|Huckleberry|Finn",
@".{0,2}(Tom|Sawyer|Huckleberry|Finn)",
@".{2,4}(Tom|Sawyer|Huckleberry|Finn)",
@"Tom.{10,25}river|river.{10,25}Tom",
@"[a-zA-Z]+ing",
@"\s[a-zA-Z]{0,12}ing\s",
@"([A-Za-z]awyer|[A-Za-z]inn)\s"
)]
public string Pattern { get; set; }
[Benchmark] public bool IsMatch() => _regex.IsMatch(s_input);
}
并對照該頁面提供的大約20MB文本檔案輸入運行它,得到以下結果:
| Method | Toolchain | Pattern | Mean | Ratio |
|---|---|---|---|---|
| IsMatch | \master\corerun.exe | (?i)T(…)Finn [31] | 12,703.08 ns | 0.32 |
| IsMatch | \netcore31\corerun.exe | (?i)T(…)Finn [31] | 40,207.12 ns | 1.00 |
| IsMatch | \master\corerun.exe | (?i)Twain | 159.81 ns | 0.84 |
| IsMatch | \netcore31\corerun.exe | (?i)Twain | 189.49 ns | 1.00 |
| IsMatch | \master\corerun.exe | ([A-Z(…)nn)\s [29] | 6,903,345.70 ns | 0.10 |
| IsMatch | \netcore31\corerun.exe | ([A-Z(…)nn)\s [29] | 67,388,775.83 ns | 1.00 |
| IsMatch | \master\corerun.exe | .{0,2(…)Finn) [35] | 1,311,160.79 ns | 0.68 |
| IsMatch | \netcore31\corerun.exe | .{0,2(…)Finn) [35] | 1,942,021.93 ns | 1.00 |
| IsMatch | \master\corerun.exe | .{2,4(…)Finn) [35] | 1,202,730.97 ns | 0.67 |
| IsMatch | \netcore31\corerun.exe | .{2,4(…)Finn) [35] | 1,790,485.74 ns | 1.00 |
| IsMatch | \master\corerun.exe | Huck[(…)A-Z]+ [26] | 282,030.24 ns | 0.01 |
| IsMatch | \netcore31\corerun.exe | Huck[(…)A-Z]+ [26] | 19,908,290.62 ns | 1.00 |
| IsMatch | \master\corerun.exe | Tom.{(…)5}Tom [33] | 8,817,983.04 ns | 0.09 |
| IsMatch | \netcore31\corerun.exe | Tom.{(…)5}Tom [33] | 94,075,640.48 ns | 1.00 |
| IsMatch | \master\corerun.exe | TomS(…)Finn [27] | 39,214.62 ns | 0.14 |
| IsMatch | \netcore31\corerun.exe | TomS(…)Finn [27] | 281,452.38 ns | 1.00 |
| IsMatch | \master\corerun.exe | Twain | 64.44 ns | 0.77 |
| IsMatch | \netcore31\corerun.exe | Twain | 83.61 ns | 1.00 |
| IsMatch | \master\corerun.exe | [a-q][^u-z]{13}x | 1,695.15 ns | 0.09 |
| IsMatch | \netcore31\corerun.exe | [a-q][^u-z]{13}x | 19,412.31 ns | 1.00 |
| IsMatch | \master\corerun.exe | [a-zA-Z]+ing | 3,042.12 ns | 0.31 |
| IsMatch | \netcore31\corerun.exe | [a-zA-Z]+ing | 9,896.25 ns | 1.00 |
| IsMatch | \master\corerun.exe | [a-z]shing | 28,212.30 ns | 0.24 |
| IsMatch | \netcore31\corerun.exe | [a-z]shing | 117,954.06 ns | 1.00 |
| IsMatch | \master\corerun.exe | \b\w+nn\b | 32,278,974.55 ns | 0.21 |
| IsMatch | \netcore31\corerun.exe | \b\w+nn\b | 152,395,335.00 ns | 1.00 |
| IsMatch | \master\corerun.exe | \s[a-(…)ing\s [21] | 1,181.86 ns | 0.23 |
| IsMatch | \netcore31\corerun.exe | \s[a-(…)ing\s [21] | 5,161.79 ns | 1.00 |
這些比例中的一些非常有趣,
另一個是“The Computer Language Benchmarks Game”中的“ regex-redux”基準, 在dotnet/performance回購中利用了此實作,因此我運行了該代碼:
| Method | Toolchain | options | Mean | Error | StdDev | Median | Min | Max | Ratio | RatioSD | Gen 0 | Gen 1 | Gen 2 | Allocated |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| RegexRedux_5 | \master\corerun.exe | Compiled | 7.941 ms | 0.0661 ms | 0.0619 ms | 7.965 ms | 7.782 ms | 8.009 ms | 0.30 | 0.01 | – | – | – | 2.67 MB |
| RegexRedux_5 | \netcore31\corerun.exe | Compiled | 26.311 ms | 0.5058 ms | 0.4731 ms | 26.368 ms | 25.310 ms | 27.198 ms | 1.00 | 0.00 | 1571.4286 | – | – | 12.19 MB |
因此,在此基準上,.NET 5的吞吐量是.NET Core 3.1的3.3倍,
呼吁社區行動
我們希望您的反饋和貢獻有多種方式,
下載.NET 5 Preview 2并使用正則運算式進行嘗試,您看到可衡量的收益了嗎?如果是這樣,請告訴我們,如果沒有,也請告訴我們,以便我們共同努力,為您最有價值的表達方式改善效果,
是否有對您很重要的特定正則運算式?如果是這樣,請與我們分享;我們很樂意使用來自您的真實正則運算式,您的輸入資料以及相應的預期結果來擴展我們的測驗套件,以幫助確保在對我們進行進一步改進時,不會退回對您而言重要的事情代碼庫,實際上,我們歡迎PR到dotnet/runtime來以這種方式擴展測驗套件,您可以看到,除了成千上萬個綜合測驗用例之外,Regex測驗套件還包含大量示例,這些示例來自檔案,教程和實際應用程式,如果您認為應該在此處添加運算式,請提交PR,作為性能改進的一部分,我們已經更改了很多代碼,盡管我們一直在努力進行驗證,但是肯定會漏入一些錯誤,您對自己的重要表達的反饋將有助于您實作這一目標!
與 .NET 5中已經完成的作業一樣,我們還列出了可以探索的其他已知作業的清單,這些作業已編入dotnet/runtime#1349,我們將在這里歡迎其他建議,更歡迎在此處概述的一些想法的實際原型設計或產品化(通過適當的性能審查,測驗等),一些示例:
-
改進自動添加原子組的回圈,如本文所述,我們現在自動在多個位置插入原子組,我們可以檢測到它們可能有助于減少回溯,同時保持語意相同,我們知道,但是,我們的分析存在一些空白,填補這些空白非常好,例如,該實作現在將
a*b+c更改為(?>a*)(?>b+)c,因為它將看到b+不會提供任何可以匹配c的東西,而a*不會給出可以匹配b的任何東西(b+表示必須至少有一個b),但是,即使后者合適,運算式a*b*c也會轉換為a*(?>b*)c而不是(?>a*)(?>b*)c,這里的問題是,我們目前僅查看序列中的下一個節點,并且b*可能匹配零項,這意味著a*之后的下一個節點可能是c,而我們目前的眼光并不那么遠, -
改進原子基團自動交替添加的功能,根據對交替的分析,我們可以做更多的作業來將交替自動升級為原子,例如,給定類似
(Bonjour|Hello), .*的運算式,我們知道,如果Bonjour匹配,則Hello也不可能匹配,因此可以將這種替換設定為原子的, -
改善
IndexOfAny的向量化,如本文所述,我們現在盡可能使用內置函式,這樣對這些運算式的改進也將使Regex受益(除了使用它們的所有其他作業負載),現在,我們在某些正則運算式中對IndexOfAny的依賴度很高,以至于它可以代表處理的很大一部分,例如在前面顯示的“ regex redux”基準上,約有30%的時間花費在IndexOfAny上,這里有機會改進此功能,從而也改進Regex,這由 dotnet/runtime#25023 單獨引入, -
制作DFA實作原型, .NET正則運算式支持的某些方面很難使用基于DFA的正則運算式引擎來完成,但是某些操作應該是可以實作的,而不必擔心,例如,
Regex.IsMatch不必關心捕獲語意(.NET在捕獲方面有一些額外的功能,這使其比其他實作更具挑戰性),因此,如果該運算式不包含諸如反向參考之類的問題構造,或環顧四周,對于IsMatch,我們可以探索使用基于DFA的引擎,并且有可能隨著時間的推移而得到更廣泛的使用, -
改善測驗,如果您對測驗的興趣超過對實施的興趣,那么在這里也需要做一些有價值的事情,我們的代碼覆寫率已經很高,但是仍然存在差距,插入這些代碼(并可能在該程序中找到無效代碼)將很有幫助,查找并合并其他經過適當許可的測驗套件以提供更多涵蓋各種運算式的內容也很有價值,
謝謝閱讀,翻譯自 Regex Performance Improvements in .NET 5
轉載請註明出處,本文鏈接:https://www.uj5u.com/net/49225.html
標籤:.NET Core